

Python3基础笔记--基础知识
目录:
一、变量问题
二、运算符总结
三、字符串问题
四、数据结构
五、文件操作
一、变量问题
变量存储在内存中的值。这就意味着在创建变量时会在内存中开辟一个空间。它自始至终都是在内存中活动,只有指明其保存时才保存到硬盘。
这里注意结合计算机组成那的 CPU 内存 硬盘 知识进行回顾
1、Python语言中的变量特点:
1)Python 中的变量赋值不需要类型声明。每个变量在内存中创建,都包括变量的标识,名称和数据这些信息。
2)每个变量在使用前都必须赋值,变量赋值以后该变量才会被创建。
2、Python语言中变量的命名规则:
1)变量名只能是字母,数字,下划线的任意组合
2)变量名的第一个字符不能是数字
3)关键字不能声明为变量名
4)大小写敏感
3、Python变量实际应用中的规范:
1)好的变量名要做到见名知意(使用下划线划分单词以及驼峰命名法)
2)Python中没有常量,约定用全体大写代表常量
4、一个例子:
1 user1 = 'Jim' 2 user2 = user1 3 print(user1, user2) 4 # output: Jim Jim 5 user1 = "Tom" 6 print(user1, user2) 7 # output:Tom JIm
运行结果以一张图片来解释一下
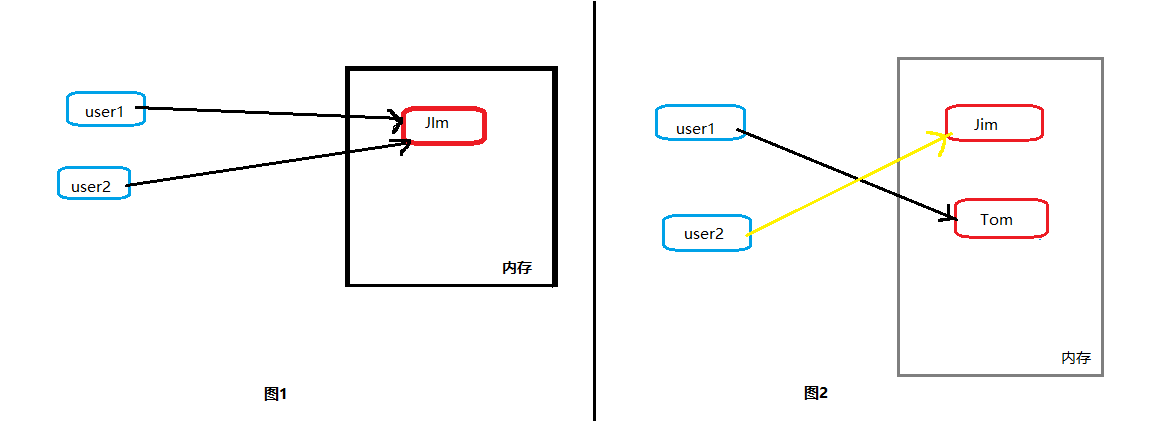
首先是第四行的输出结果,如图1所示,user1与user2都是指向了内存中的Jim
然后我们有
user1 = "Tom"
这只改变了user1的指向,并没有改变user2的,其结果如图2所示
二、运算符总结
1)算术运算符 : + - * / //(取整除) %(取余) **(次方)
2)赋值运算符: = += -= *= /= %= //= **=
3)比较运算符:>、 <、 >=、 <=、 ==、!=
4)逻辑运算符: not 、and、 or
首先,‘and’、‘or’和‘not’的优先级是not>and>or。其次,逻辑操作符and 和or 也称作短路操作符(short-circuitlogic)或者惰性求值(lazy evaluation):它们的参数从左向右解析,一旦结果可以确定就停止。例如,如果A 和C 为真而B 为假, A and B and C 不会解析C 。
5)成员运算符: not in 、in (判断某个单词里是不是有某个字母)
6)身份运算符: is、is not(讲数据类型时讲解,一般用来判断变量的数据类型)
三、字符串问题
1)字符串的拼接: 用万恶的 + 号...........推荐用join()
print("Hello" + "World") # output: HelloWorld
2)print() 语句不输出换行
1 # python2 2 print("Hello",) 3 # python3 4 print("Hello Perry", end='')
解释一下python3, end='', 这里是有默认值的,默认值是换行符,这里给它指定为空,便不再换行,还可以指定其他值
3)字符串之间用逗号,一个逗号代表一个空格
4)格式化输出
第一种利用占位符
1 lan = 'python' 2 slan = 'i love %s' % m 3 print(slan) 4 # output: i love python 5 6 name = 'Perry' 7 age = '23' 8 print('your name is %s.age is %s' % (name, age) 9 # output: your name is Perry.age is 23
第二种format方法
5)相关操作
1 # 1 * 重复输出字符串 2 print('hello'*2) 3 4 # 2 切片或者索引 [] ,[:] 通过索引获取字符串中字符,这里和列表的切片操作是相同的,具体内容见列表 5 print('helloworld'[2:]) 6 7 # 3 in 成员运算符 - 如果字符串中包含给定的字符返回 True 8 print('el' in 'hello') 9 10 # 4 % 格式字符串 11 print('alex is a good teacher') 12 print('%s is a good teacher'%'alex') 13 14 15 # 5 + 字符串拼接 16 a='123' 17 b='abc' 18 c='789' 19 d1=a+b+c 20 print(d1) 21 # +效率低,该用join 22 d2=''.join([a,b,c]) 23 print(d2) # 输出是:123abc789 24 25 d3 = '-'.join([a, b, c]) 26 print(d3) # 输出是:123-abc-789
注意join()方法,这是进行拼接,在各个字符串之间按给定的字符串拼接
养成用的习惯
6)内置方法
# string.count(str, beg=0, end=len(string)) 返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数 # string.replace(str1, str2, num=string.count(str1)) 把 string 中的 str1 替换成 str2,如果 num 指定,则替换不超过 num 次. # string.center(width) 返回一个原字符串居中,并使用空格填充至长度 width 的新字符串,还可以指定填充的字符 # string.ljust(width) 返回一个原字符串左对齐,并使用空格填充至长度 width 的新字符串 # string.rjust(width) 返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串 # string.strip([obj]) 在 string 上执行 lstrip()和 rstrip() # string.lstrip() 截掉 string 左边的空白,换行符也会去掉 # string.rstrip() 删除 string 字符串末尾的空白. # string.split(str="", num=string.count(str)) 以 str 为分隔符切片 string,如果 num有指定值,则仅分隔 num 个子字符串,然后用join()拼接 # string.isdigit() 如果 string 只包含数字则返回 True 否则返回 False. # string.endswith(obj, beg=0, end=len(string)) 检查字符串是否以 obj 结束,如果beg 或者 end 指定则检查指定的范围内是否以 obj 结束,如果是,返回 True,否则返回 False. # string.startswith(obj, beg=0,end=len(string)) 检查字符串是否是以 obj 开头,是则返回 True,否则返回 False。如果beg 和 end 指定值,则在指定范围内检查. # string.find(str, beg=0, end=len(string)) 检测 str 是否包含在 string 中,如果 beg 和 end 指定范围,则检查是否包含在指定范围内,如果是返回开始的索引值,否则返回-1 # string.lower() 转换 string 中所有大写字符为小写. # string.upper() 转换 string 中的小写字母为大写 # string.rfind(str, beg=0,end=len(string) ) 类似于 find()函数,不过是从右边开始查找. # string.index(str, beg=0, end=len(string)) 跟find()方法一样,只不过如果str不在 string中会报一个异常. # string.rindex( str, beg=0,end=len(string)) 类似于 index(),不过是从右边开始. # max(str) 返回字符串 str 中最大的字母。 # min(str) 返回字符串 str 中最小的字母。 # string.expandtabs(tabsize=8) 把字符串 string 中的 tab 符号转为空格,tab 符号默认的空格数是 8。 # string.capitalize() 把字符串的第一个字符大写 # string.isalnum() 如果 string 至少有一个字符并且所有字符都是字母或数字则返回 True,否则返回 False # string.isalpha() 如果 string 至少有一个字符并且所有字符都是字母则返回 True,否则返回 False # string.isdecimal() 如果 string 只包含十进制数字则返回 True 否则返回 False. # string.islower() 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False # string.isnumeric() 如果 string 中只包含数字字符,则返回 True,否则返回 False # string.isspace() 如果 string 中只包含空格,则返回 True,否则返回 False. # string.istitle() 如果 string 是标题化的(见 title())则返回 True,否则返回 False # string.isupper() 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False # string.join(seq) 以 string 作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串 # string.partition(str) 有点像 find()和 split()的结合体,从 str 出现的第一个位置起,把 字 符 串 string 分 成 一 个 3 元 素 的 元 组 (string_pre_str,str,string_post_str),如果 string 中不包含str 则 string_pre_str == string. # string.rpartition(str) 类似于 partition()函数,不过是从右边开始查找. # string.splitlines(num=string.count('\n')) 按照行分隔,返回一个包含各行作为元素的列表,如果 num 指定则仅切片 num 个行. # string.swapcase() 翻转 string 中的大小写 # string.title() 返回"标题化"的 string,就是说所有单词都是以大写开始,其余字母均为小写(见 istitle()) # string.translate(str, del="") 根据 str 给出的表(包含 256 个字符)转换 string 的字符,要过滤掉的字符放到 del 参数中
详解translat方法 Python3.6环境中
translate的用法如下:
bstr = astr.translate(strtable,delete)
astr是一个需要被转换的字符串,strtable是一个翻译表,delete包含的字符在astr中需要被移除,移除后剩下的字符经过翻译表得到bstr。 先删除然后翻译
翻译表是什么呢?翻译表是通过maketrans方法转换而来,其原型如下:
string.maketrans(instr,outstr) 返回一个翻译表
instr中的字符是需要被outstr中的字符替换,而且instr和outstr的长度必须相等,返回的翻译表的长度必须是256.如下面的例子:
instr = 'abc' outstr = '123' table = str.maketrans(instr,outstr)
则在table中,原本存储字符a,b,c的位置分别换成了1,2,3,maketrans的作用就是这样。
得到翻译表之后,然后就用translate方法进行翻译,看下面几个例子,就容易理解了。
import string instr = 'abcde' outstr = '12345' table = str.maketrans(instr,outstr) astr = 'abcdefg-123' bstr = astr.translate(table,'123') print(bstr)
结果是
12345fg-
四、数据结构
Python有6个序列的内置类型,但最常见的是列表和元组。序列都可以进行的操作包括索引,切片,加,乘,检查成员。此外,Python已经内置确定序列的长度以及确定最大和最小的元素的方法。
参考博客:Py西游攻关之基础数据类型
1、列表 list
列表是Python中最基本的数据结构,列表是最常用的Python数据类型,列表的数据项不需要具有相同的类型。列表中的每个元素都分配一个数字 - 它的位置,或索引,不仅可以从前往后,还可以从后往前。第一个索引是0,第二个索引是1,最后一个索引是-1,依此类推。
列表操作包含以下方法:
① list.append(obj): 在列表末尾添加新的对象
② list.count(obj): 统计某个元素在列表中出现的次数
③ list.extend(seq): 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表)
④ list.index(obj): 从列表中找出某个值第一个匹配项的索引位置
⑤ list.insert(index, obj): 将对象插入列表中的自己指定的位置
⑥ list.pop(obj=list[-1]): 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值,按索引删除
⑦ list.remove(obj): 移除列表中某个值的第一个匹配项 ,按值删除
⑧ list.reverse(): 反向列表中元素
⑨ list.sort([func]): 对原列表进行排序,默认升序
要熟练掌握列表的切片操作,可以做到事半功倍,写出简洁优雅的代码
1 a = ['tom', 'jim', 'amy', 'james', 'panlei','perry','curry'] 2 b = list('qwer') # ['q','w','e','r'] 3 print(a[:]) # 全部输出 4 print(a[3:]) # 从下标为3开始,从左到右,输出到最后 5 print(a[1:-1]) # 从下标为1开始,从左到右,输出到最后的前一个 6 print(a[1::2]) # 从下标为1开始,从左到右,以2为步长输出到最后 7 print(a[3:0:-1]) # 从下标为3开始,从右到左,以1为步长输出到第一个的前一个 8 '''output 9 ['tom', 'jim', 'amy', 'james', 'panlei', 'perry', 'curry'] 10 ['james', 'panlei', 'perry', 'curry'] 11 ['jim', 'amy', 'james', 'panlei', 'perry'] 12 ['jim', 'james', 'perry'] 13 ['james', 'amy', 'jim'] 14 '''
解释参数 a[A:B:C] A:代表开始位置 B:代表结束位置,不会输出这个位置,而是其前一个位置 C:代表步长,其正负代表方向(默认为从左到右, -代表从右向左)
2、元组 tuple
元组跟列表差不多,也是存一组数,只不是它一旦创建,便不能再修改,所以又叫只读列表
1 a = ('q',1,3,4,'t',) 2 3 b = (1,) 4 5 # 注意只有一个元素时要在最后加逗号
它只有2个方法,一个是count(obj) : 统计某个元素出现的次数,一个是index(obj) : 查询某个元素的下标
3、字典 dict
字典是python中唯一的映射类型,采用键值对(key-value)的形式存储数据。python对key进行哈希函数运算,根据计算的结果决定value的存储地址,所以字典是无序存储的,且key必须是可哈希的。可哈希表示key必须是不可变类型,如:数字、字符串、元组。
不可变类型:数字、字符串、元组
可变类型:列表,字典
字典的特性:
- dict是无序的
- key必须是唯一的,天生去重
对应操作:
1)创建
dic1={'name':'panlei','age':23,'sex':'male'}
dic2=dict((('name','panlei'),))
print(dic1)
print(dic2)
2)增
dic3={} dic3['name']='panlei' dic3['age']=18 print(dic3) # output: {'name': 'alex', 'age': 18} a=dic3.setdefault('name','yuan') b=dic3.setdefault('ages',22) print(a,b) print(dic3)
可以直接对字典对象进行操作,指定键值对,若直接指定,则没有创建,有则覆盖。若使用setdefault()函数,有则不做任何改变,无则创建新的键值对,并返回相应值
3)查
dic3={'name': 'panlei', 'age': 23}
print(dic3['name'])
print(dic3.get('age',False))
print(dic3.get('ages',False))
print(dic3.items()) # 以列表形式输出所有键值对
print(dic3.keys()) # 这里keys()的返回值类型需要注意,可以利用list()转换为列表
print(list(dic3.keys()))
print(dic3.values())
print('name' in dic3) # py2: dic3.has_key('name')
print(list(dic3.values()))
4)改
dic3 = {'name': 'panlei', 'age': 18}
dic3['name'] = 'alvin'
dic4 = {'sex':'male','hobby':'girl','age':36}
dic3.update(dic4)
print(dic3)
update()函数是将一个字典加入另一个字典,若两个字典里有重复的,则覆盖,也就是更新
5)删
dic4={'name': 'panlei', 'age': 23,'class':1}
dic4.clear() # 清空
print(dic4)
del dic4['name'] # 删除整个键值对
print(dic4)
a=dic4.popitem() # 随机弹出(删除),并返回这个键值对。没啥用
print(a,dic4)
print(dic4.pop('age')) # 删除指定键值对,并返回值
print(dic4)
del dic4 # 彻底删除
print(dic4)
6)字典的遍历
dic5 = {'name': 'panlei', 'age': 23}
for i in dic5: # 这里i 只获得字典的 键
print(i, dic5[i])
for items in dic5.items():
print(items)
for keys, values in dic5.items():
print(keys, values)
'''
output
name panlei
age 23
('name', 'panlei')
('age', 23)
name panlei
age 23
'''
7)其他操作
①字典的嵌套,应用于多级显示
china = { "山东省":{ "济南市": ["省会","一般"], "青岛市": ["第一","山东的希望"], "潍坊市": ["挺大","还行"], }, "陕西省":{ "西安市":["省会","雾霾"], "宝鸡市":["后院","还行"], }, } china["山东省"]["潍坊市"][1] += ",风筝之都" print(china["山东省"]["潍坊市"]) # output # ['挺大', '还行,风筝之都']
还用我们上面的例子,存取这个班学生的信息,我们如果通过字典来完成,那:
dic={'zhangsan':{'age':23,'sex':'male'},
'李四':{'age':33,'sex':'male'},
'wangwu':{'age':27,'sex':'women'}
}
②排序:sorted(dict) : 返回一个有序的包含字典所有key的列表
dic={5:'555',2:'222',4:'444'}
print(sorted(dic))
4、集合 set
集合是一个无序的,不重复的数据组合,它的主要作用如下:
- 去重,把一个列表变成集合,就自动去重了
- 关系测试,测试两组数据之前的交集、差集、并集等关系
集合(set):把不同的元素组成一起形成集合,是python基本的数据类型。
集合对象是一组无序排列的可哈希的值:集合成员可以做字典的键
集合分类:可变集合、不可变集合
可变集合(set):可添加和删除元素,非可哈希的,不能用作字典的键,也不能做其他集合的元素
不可变集合(frozenset):与上面恰恰相反
1)创建集合
由于集合没有自己的语法格式,只能通过集合的工厂方法set()和frozenset()创建
s1 = set('perry') s2 = frozenset('panlei') print(s1, type(s1)) # {'r', 'y', 'p', 'e'} <class 'set'> print(s2, type(s2)) # frozenset({'i', 'l', 'p', 'e', 'a', 'n'}) <class 'frozenset'>
2)访问集合
由于集合本身是无序的,所以不能为集合创建索引或切片操作,只能循环遍历或使用in、not in来访问或判断集合元素。
s1 = set('alvin') print('a' in s1) print('b' in s1) #s1[1] #TypeError: 'set' object does not support indexing for i in s1: print(i) # # True # False # v # n # l # i # a
3)更新集合
可使用以下内建方法来更新:
s.add()
s.update()
s.remove() # set中必须有要remove()的字符
注意只有可变集合才能更新:
s = set('perry') s.add('pl') print(s) # {'y', 'pl', 'r', 'e', 'p'} # update() 方法的参数是一个可迭代对象,逐个添加 s.update('PL') # 添加多个元素 print(s) # {'y', 'P', 'pl', 'L', 'r', 'e', 'p'} s.update(['QWE',12]) print(s) # {'e', 'y', 'p', 'r', 12, 'pl', 'L', 'QWE', 'P'} s.remove('r') print(s) # {'y', 'P', 'pl', 'L', 'e', 'p'} s.pop() # 随机删除一个元素 s.clear() # 清空
4)集合类型操作符
① in ,not in
② 集合等价与不等价(==, !=)
③ 子集、超集
s=set('alvinyuan') s1=set('alvin') print('v' in s) # True print(s1<s) # True
a = set([1,2,3,4,5]) b = set([3,4,5]) print(a.issuperset(b)) print(a > b) print(a < b) print(a.issubset(b))
④ 并交差集
a = set([1, 2, 3, 4, 5, 7]) b = set([4, 5, 6, 7, 8]) # 交集 print(a.intersection(b)) print(a & b) # 并集 print(a.union(b)) print(a | b) # 差集 print(a.difference(b)) print(a - b) # 对称差集:输出除了交集之外的元素 print(a.symmetric_difference(b)) print(a ^ b)
应用:
'''最简单的去重方式''' lis = [1,2,3,4,1,2,3,4] print list(set(lis)) #[1, 2, 3, 4]
五、文件操作 : 一定要把握好光标的移动,不论是write还是read操作,都会移动光标
https://blog.csdn.net/silentwolfyh/article/details/74931123
1、文件操作的流程
1)打开文件,得到文件句柄并赋值给一个变量
2)通过句柄对文件进行操作
3)关闭文件
1 昨夜寒蛩不住鸣。 2 惊回千里梦,已三更。 3 起来独自绕阶行。 4 人悄悄,帘外月胧明。 5 白首为功名,旧山松竹老,阻归程。 6 欲将心事付瑶琴。 7 知音少,弦断有谁听。
1 f = open('文件名') #打开文件 2 data=f.read()#获取文件内容 3 f.close() #关闭文件
注意在Windows中,python3的文件是 utf8 保存的,打开文件时open函数是通过操作系统打开的文件,而win操作系统
默认的是gbk编码,所以直接打开会乱码,需要f=open('hello',encoding='utf8'),若文件如果是gbk保存的,则直接打开即可
2、文件打开模式
'r' 只读,文件必须先存在。默认打开方式 'w' 只写,文件不存在就创建,存在就清空openforwriting, truncating thefilefirst'r+' 读写方式,写的时候从最前开始,会覆盖已有内容 'w+' 读写方式,清空已有内容
'a+' 'x' 创建一个新文件(这个文件不能与其他文件重名),并以只写的方式打开 'a' 以追加的方式打开文件 'b' 二进制模式 't' text mode (default) '+' open a disk file for updating (reading and writing) 'U' universal newline mode (deprecated)
3、一个常用的文件读代码
f = open('name', 'r') for i in f: print(i.strip()) f.close()
这里for内部将文件对象转换为一个迭代器,不像read()方法一样是将所有内容读到内存中去,而是用一行从磁盘中读一行
4、文件具体操作


def read(self, size=-1): # known case of _io.FileIO.read """ 注意,不一定能全读回来 Read at most size bytes, returned as bytes. Only makes one system call, so less data may be returned than requested. In non-blocking mode, returns None if no data is available. Return an empty bytes object at EOF. """ return "" def readline(self, *args, **kwargs): pass def readlines(self, *args, **kwargs): pass def tell(self, *args, **kwargs): # real signature unknown """ Current file position. Can raise OSError for non seekable files. """ pass def seek(self, *args, **kwargs): # real signature unknown """ Move to new file position and return the file position. Argument offset is a byte count. Optional argument whence defaults to SEEK_SET or 0 (offset from start of file, offset should be >= 0); other values are SEEK_CUR or 1 (move relative to current position, positive or negative), and SEEK_END or 2 (move relative to end of file, usually negative, although many platforms allow seeking beyond the end of a file). Note that not all file objects are seekable. """ pass def write(self, *args, **kwargs): # real signature unknown """ Write bytes b to file, return number written. Only makes one system call, so not all of the data may be written. The number of bytes actually written is returned. In non-blocking mode, returns None if the write would block. """ pass def flush(self, *args, **kwargs): pass def truncate(self, *args, **kwargs): # real signature unknown """ Truncate the file to at most size bytes and return the truncated size. Size defaults to the current file position, as returned by tell(). The current file position is changed to the value of size. """ pass def close(self): # real signature unknown; restored from __doc__ """ Close the file. A closed file cannot be used for further I/O operations. close() may be called more than once without error. """ pass ##############################################################less usefull def fileno(self, *args, **kwargs): # real signature unknown """ Return the underlying file descriptor (an integer). """ pass def isatty(self, *args, **kwargs): # real signature unknown """ True if the file is connected to a TTY device. """ pass def readable(self, *args, **kwargs): # real signature unknown """ True if file was opened in a read mode. """ pass def readall(self, *args, **kwargs): # real signature unknown """ Read all data from the file, returned as bytes. In non-blocking mode, returns as much as is immediately available, or None if no data is available. Return an empty bytes object at EOF. """ pass def seekable(self, *args, **kwargs): # real signature unknown """ True if file supports random-access. """ pass def writable(self, *args, **kwargs): # real signature unknown """ True if file was opened in a write mode. """ pass
f = open('name') #打开文件 # data1=f.read()#获取文件内容 # data2=f.read()#获取文件内容 # # print(data1) # print('...',data2) # data=f.read(5)#获取文件内容 # data=f.readline() # data=f.readline() # print(f.__iter__().__next__()) # for i in range(5): # print(f.readline()) # data=f.readlines() # for line in f.readlines(): # print(line) # 问题来了:打印所有行,另外第3行后面加上:'end 3' # for index,line in enumerate(f.readlines()): # if index==2: # line=''.join([line.strip(),'end 3']) # print(line.strip()) # 切记:以后我们一定都用下面这种 # count=0 # for line in f: # if count==3: # line=''.join([line.strip(),'end 3']) # print(line.strip()) # count+=1 # print(f.tell()) # tell()方法告诉光标的位置,应用于断点续传 # print(f.readline()) # print(f.tell()) # tell对于英文字符就是占一个,中文字符占三个,区分与read()的不同. # print(f.read(5)) # 一个中文占三个字符 # print(f.tell()) # f.seek(0) # seek()调整光标的位置,应用于断点续传 # print(f.read(6)) #read后不管是中文字符还是英文字符,都统一算一个单位,read(6),此刻就读了6个中文字符 #terminal上操作: f = open('hello','w') # f.write('hello \n') # f.flush() # flush() 将缓冲区中的内容保存到硬盘中 # f.write('world') # 应用:进度条 # import time,sys # for i in range(30): # sys.stdout.write("*") # # sys.stdout.flush() # time.sleep(0.1) # f = open('hello','a') # f.truncate() #全部截断 # f.truncate(5) #从第5个位置往后全部截断 # print(f.isatty()) # print(f.seekable()) # print(f.readable()) f.close() #关闭文件
5、终极问题:如何对一个文件进行修改
由于文件光标位置以及内存的机制,我们无法在源文件上在读写操作上对其进行修改。我们只能利用新建一个文件的方式进行操作
fr = open(yuani', 'r', encoding='utf8') fw = open('yuancopy', 'w', encoding='utf8') num = 0 for ir in fr: num += 1 if num == 6: ir = ''.join([ir.strip(),'追加\n']) fw.write(ir) fr.close() fw.close()
6、with语句
为了避免打开文件后忘记关闭,可以通过管理上下文,即:
with open('log','r') as f: pass
如此方式,当with代码块执行完毕时,内部会自动关闭并释放文件资源。
在Python 2.7 后,with又支持同时对多个文件的上下文进行管理,即:
with open('log1') as obj1, open('log2') as obj2: pass
