自整定模糊PID算法的理论
模糊控制系统的构成与与常规的反馈控制系统的主要区别在于控制器主要是由模糊化,模糊推理机和精确化三个功能模块和知识库(包括数据库和规则库)构成的。具体实现过程如下所示:
(1)预处理:
输入数据往往是通过测量设备测量得到的一个具体数据,预处理就是在它们进入控制器前对这些数据进行分类,或性质程度的定义。预处理过程也是量化过程,它是在离散空间中把输入数据划分为若干个数字级别。例如,假设一个反馈误差为 4.5,误差空间是(-5,-4…4,5),量化器会使它靠近离它最近的级别,四舍五入到 5。称量化器量化的比例为量化因子。量化过程是个削减数据量的方法,但是如果量化过于粗糙,控制器会振荡甚至失去平衡。
(2)模糊化
在进行模糊化时,需要确定模糊集论域中语言变量各值所对应的模糊子集的隶属度函数。隶属度函数一般是根据操作者的经验初步确定,在调试开发甚至控制器运行中需不断修正和优化,以满足控制的要求。隶属度函数的形状很多,但是影响模糊控制器性能的关键因素是各模糊集覆盖论域的情况,而隶属函数的形状在达到控制要求方面并无大的差别,为使数学表达和运算简单,一般选用三角形、梯形隶属函数。但隶属函数的幅宽大小对性能影响较大,隶属函数形状较陡时,引起的输出变化较剧烈,控制的灵敏度高;隶属函数形状平缓时,引起的输出变化较缓慢,对系统的稳定性好。因此,在选择隶属函数时,一般在偏差较小或接近于零附近时,采用形状较陡的隶属函数;而在偏差较大的区域采用形状平缓的隶属函数,以使系统具有良好的鲁棒性。而且在实际工作中,不应出现三个隶属函数相交的状态。一般,任何两个模糊子集的交集的最大隶属度中的最大值取为 0.4~0.8 之间。另外,隶属函数的位置分布对控制性能也有一定的影响,当函数在整个论域平均分布时,控制效果并不好,因此,一般将零固定,其它模糊子集向零集靠拢,以达到较好的控制效果。
(3)设计控制规则表
规则的条件和结论中要用到一些变量,控制器用来解决多输入多输出和单输入单输出问题,传统的单输入单输出问题是基于误差 E 调节控制信号,有时也需要误差的变化速度还有累积误差,但是我们也称之为单输入单输出系统,因为从原则上讲,这三个量都来源于对误差的测量。简单地说,我们的控制对象如果是围绕着一个标准值被调节,我们的陈述及研究仅限于单输入单输出系统而言。
规则格式:基本上,一个模糊语言控制器都包含 LIWKHQ 形式的规则,但也有其他规则格式。在多数系统中,规则以这样的形式展现:
if A is NB and B is NB, then c is NB (2-11)
式中 Zero,Pos,Nag——模糊集的标签: Z、PB 、 NM ——表示零点,正大和负中
(4)推理机
规则只反应了控制信号是误差和误差变化率等量通过了计算得到的。而推理决策才是模糊控制的核心,它利用知识库中的信息和模糊运算方式,模拟人的推理决策的思想方法,在一定的输入条件下激活相应的控制规则给出适当的模糊控制输出。
这一部分可以通过设计不同推理算法的软件在计算机上来实现,也可以采用专门设计的模糊推理硬件集成电路芯片来实现。由于基于模糊推理的硬件集成电路价格一般比较高,目前多数模糊控制器采用软件在计算机上实现。
(5)精确化
通过模糊化推理得到的结果是一个模糊量,是一组具有多个隶属度值的模糊向量。而控制系统执行的输出信号是一个确定的量值,因此,在模糊控制应用中,必须将控制器的模糊输出量转化成一个确定值,即进行精确化过程。常用的精确化方法有两种,即最大隶属度法和重心法。对于最大隶属度法,若输出量模糊集合的隶属度函数只有一个峰值,则取隶属度函数的最大值为精确值,选取模糊子集中隶属度最大的元素作为控制量。若输出模糊向量中有多个最大值,一般取这些元素的平均值作为控制量。最大隶属度法的优点是计算简单,但由于该法利用的信息量较少,会引起一定的控制偏差,一般应用于控制精度要求不高的场合。
重心法是取模糊隶属度函数曲线与横坐标围成面积的中心为模糊推理输出的精确值,对于有 N个输出量化级数的离散域情况有: 
这里 xi是离散空间里不同的点,i(xi) 是它在隶属函数中的隶属度,表达式可以理解为在设定隶属集中的重心。对于连续的情况,可以把作和替换成积分来算。计算量相对高些,但算法相对精确,因此也是最常用的算法之一。
最大隶属度法,这种方法最简单,只要在推理结论的模糊集合中取隶属度最大的那个元素作为输出量即可。这种方法不考虑隶属函数的形状。
(6) 后处理
系统控制输出值只是相对的,并不是实际控制量,相对控制量与实际工程所需值有个比例关系,再后处理过程中,要乘上这个输出比例因子,并赋予有实际意义的单位像是电压、米、公斤等,例如(-2,2)表示电压(-10 V,10V)。
以上就是模糊控制算法的主要内容。模糊控制算法最大的特点是不必完全通晓一个系统的数学模型,就可以实现控制效果。所以对于数学模型难以确定的系统而言有很大的优势,但是由于模糊控制算法中不存在积分项,所以控制结果容易产生静差。为了消除这一个缺陷,我们可以将模糊控制算法和PID算法结合起来,从而得到参数自整定模糊PID算法。
参数自整定模糊PID算法的框图如下所示:
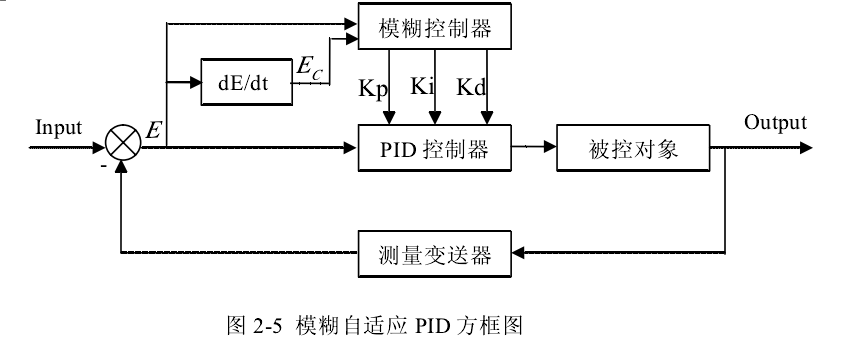
具体实现措施就是先设定PID控制器的初值(具体的数值可以引用上学期的调试结果),然后在根据模糊规则得到相应的调节值,然后相加即得到最终的PID参数。
Kp = Kp' + Qp * △Kp (Kp' : 初值 Qp: 比例系数 △Kp : 模糊规则得到的Kp调节值)
Ki = Ki' + Qi * △Ki
Kd = Kd' + Qd * △Kd
以上就是参数自整定模糊PID算法的理论全部内容。
转载:http://www.cnblogs.com/qifengle/p/5212270.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号