

【one day one linux】好用的数据处理工具awk
awk:好用的数据处理工具
取自《鸟哥私房菜》awk一节
应用:awk是以一行为一次的处理单位,将一行分成数个“字段”进行处理。
#awk的命令格式 awk '条件类型1{动作1} 条件类型2{动作2} ...' filename
awk后面接两个单引号并加上大括号{}来设置想要对数据的处理动作。awk处理后面接的文件名字.
awk主要处理每一行的字段内的数据,而默认的字段的分隔符为空格键或者[tab]键。
如下的例子,处理last取出的登录数据:
last -n 5
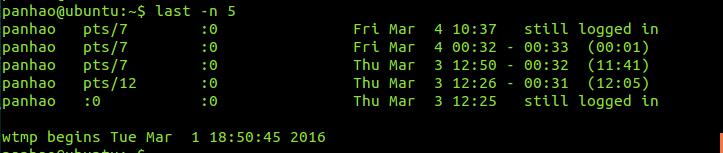
# last -n 5 | awk '{print $1 "\t" $3}'
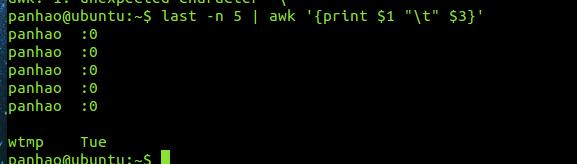
上面是默认使用空格键作为分隔符。
有上面可以看出awk把每个字段分配一个变量名称,$1表示第一个字段,$2表示第二个字段,而$0表示一整行。
awk的处理流程是:
- 读入第一行,并将第一行的数据填入$0 $1 $2等变量中
- 依据条件类型限制,判断是否进行后面的动作。(上面的没有条件类型)
- 做完所有的动作和条件类型 (上面的动作就是"print $1 "\t" $3")
- 后面还有行的话,重复以上的动作
awk的内置变量,可以查看到底有几行,几列
| 变量名称 | 代表意义 |
| NF | 每一行($0)拥有的字段总数 |
| NR | 目前awk所处理的是“第几行”数据 |
| FS | 目前的分割字符,默认是空格键 |
上面的last -n 5的例子来做说明:
- 列出每一行的账号(就是$1)
- 列出目前处理的行数(就是awk内的NR变量)
- 并且说明,该行有多少字段(就是awk内的NF变量)
# last -n 5 | awk '{print $1 "\t lines: "NR "\t columes: "NF}'
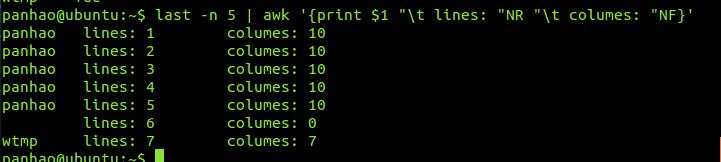
有上面的代码可以看出:
- 当awk后续所有的动作都是用 ' 单引号括起来的
- print打印时,如果属于非变量的文字需要使用 " 双引号括起来
awk的逻辑运算和条件
awk需要使用判断条件,所以就有逻辑运算符,和C语言差不多: "<" ">" ">=" "<=" "==" "!="
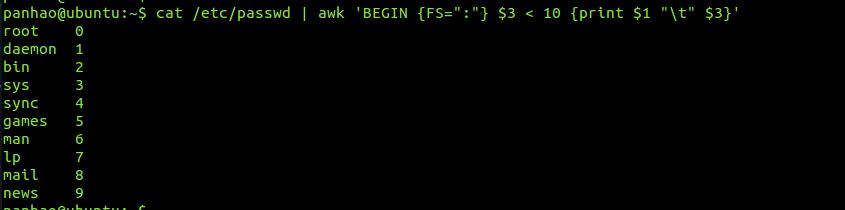
下面使用cat 查看/etc/passwd文件的字符串,他的第一个字段是账号,第三个字段是UID,使用awk筛选出UID小于10 的数据
# cat /etc/passwd | awk '{FS=":"} $3<10 {print $1 "\t" $3}'
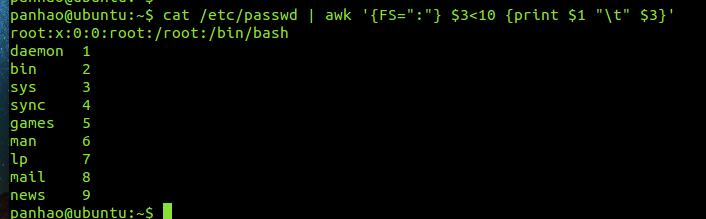
可以看到,这里的第一行是没有被处理的,这里是因为我们读入第一行的时候,那些变量$1 $2 ...默认还是以空格分割的,所以我们虽然定义了FS=":"了,但是切仅能作用在第二行后才开始生效。
解决办法:利用BEGIN关键字,like this
# cat /etc/passwd | awk 'BEGIN {FS=":"} $3 < 10 {print $1 "\t" $3}'
awk计算处理数据
# cat pay.txt | \ awk 'NR==1{printf "%10s %10s %10s %10s %10s\n",$1,$2,$3,$4,"Total"} NR>=2{total = $2+$3+$4 printf "%10d %10d %10d %10d %10.2f",$1,$2,$3,$4,total}'
这里这条命令一直运行出错,待稍后查看

 浙公网安备 33010602011771号
浙公网安备 33010602011771号