第八节 数据结构与算法
1. 模板函数
int Add(int a, int b) { return a + b; } //函数重载,通过参数列表,自动查找执行函数 double Add(double a, double b) { return a + b; } //C++新的写法,但是返回值无法使用多类型 int Add(double, int a, double, int b) { return a + b; } //创建模板 template<class T> T Add(T a, T b) { return a + b; } //使用多个模板 template<class T1, class T2> T1 Add(T1 a, T2 b) { return a + b; } int main() { Add(3, 4); //函数重载 Add<int>(3, 4); //模板函数 Add<int, double>(3, 4); //模板函数 return 0; }
2. 基本数据结构
// 1. 数组:数据在内存中顺序存储,声明时需要确定大小,元素的增删都需要移动所有元素,查找时只能按照顺序查找 // 数组在创建时大小就已经确定,因此无论是插入还是删除,都需要开辟一块新的内存空间 // 或者使用数组指针的方式,以指针的形式进行移动,强制后移一块数据空间,这种做法可能造成数据丢失 int* ArrayInsert(int array[], int size, int index, int value) { int newArray[size + 1]; for(int i = 0; i < (size + 1); i++) { if(i < index) newArray[i] = array[i]; else if (i > index) newArray[i] = array[i - 1]; } newArray[index] = value; return newArray; } // 2. 链表:数据在内存中无序存放,通过指针相连接,声明时不需要去确定大小,增删操作只需要修改一个元素指针,查找时只能按照顺序查找 struct ListNode { int Value; ListNode* Pre; ListNode* Next; }; struct List { ListNode* Head; int NodeCount; }; List CreateNewList(int value) { ListNode head {value, NULL, NULL}; return List{&head, 1}; } // 链表的节点在内存中是松散的结构,因此插入和删除都不需要额外的内存空间或者移动数据 void InsertListNode(List* list, /*or ListNode* head,*/ ListNode* node, int index /* or at last*/) { ListNode* head = list->Head; for(;index > 0; index--) if(head->Next != NULL) head = head->Next; //index or last head->Next = node; node->Pre = head; } // 3.队列:以链表为基础,增删时要遵守先入先出规则 struct Queue { ListNode* head; ListNode* end; }; Queue CreateQueue(int value) { ListNode node {value, NULL, NULL}; return Queue {&node, &node}; } // 队列的规则是先入先出,因此只能从队尾取数据,以及向队首插入数据两个操作 int Pop(Queue* queue) { if (queue->end != NULL) { int value = queue->end->Value; ListNode *pre = queue->end->Pre; queue->end = pre; pre->Next = NULL; } } void Push(Queue* queue, ListNode* node) { node->Pre = NULL; node->Next = queue->head; queue->head->Pre = node; } // 4. 栈:以链表为基础,增删时要遵守先入后出规则 struct Stack { ListNode* head; ListNode* end; }; // 栈的规则是先入后出,与队列的规则相反 int Pop_Stack(Stack* stack) { if (stack->head != NULL) { int value = stack->head->Value; ListNode *next = stack->head->Next; stack->head = next; next->Pre = NULL; } } // 5. 树:以链表为基础,形成root-leaf结构,每个根节点可以具有多个子节点和一个父节点 // 如果按照特定方式排序可以形成排序二叉树,是文件存储,计算机高级编码方式的基础 // 如果树枝上带有特定的值,就变为加权树 struct TreePath; struct TreeNode { int Value; TreePath* Branch; int BranchCount; }; struct TreePath { TreeNode* Root; TreeNode* Leaf; }; struct Tree { TreeNode* TreeRoot; }; // DFS // 深度优先搜索,或者利用循环+栈的形式实现,后者主要用于图的搜索 void DFS(TreeNode* root) { cout << root->Value; for(int i = 0; i < root->BranchCount; i++) { DFS(root->Branch[i].Leaf); } } // BFS struct TreeListNode { TreeNode* Value; TreeListNode* Next; }; // begin: TreeListNode head{root, NULL, NULL} void BFS(TreeListNode* head) { TreeListNode *nextLevelHead = NULL; TreeListNode *nextLevelNode = NULL; while (head != NULL) { for (int i = 0; i < head->Value->BranchCount; i++) { TreeListNode newNode{head->Value->Branch[i].Leaf, NULL}; if (nextLevelHead == NULL) { nextLevelHead = &newNode; } else { nextLevelNode->Next = &newNode; } nextLevelNode = &newNode; } head = head->Next; } BFS(nextLevelHead); } // 6. 图:以树为基础,当一个节点具有多个父节点并形成环路时,就变成了图,图可以分为有向图、无向图、加权图等 struct GraphPath; struct GraphNode { int Value; GraphPath* Path; int PathCount; }; struct GraphPath { GraphNode* Head; GraphNode* Tail; }; struct Graph { GraphNode* Begin; // 对于图而言,并没有明确的起点 }; // DFS 对于图而言,会形成环路,因此无法使用是否具有子叶的方式判断结束 void Push_Stack(Stack* stack, GraphNode* node); bool Find_Stack(Stack* stack, GraphNode* node); Stack* DFSRes; void DFS_Stack(GraphNode* node) { cout << node->Value; for(int i = 0; i < node->PathCount; i++) { GraphNode* childNode = node->Path[i].Tail; if(!Find_Stack(DFSRes, childNode)) { Push_Stack(DFSRes, childNode); DFS_Stack(childNode); } } } // 7. 散列表:通过映射的方式,将元素重新赋值,形成的表格状数据结构,如果不是一一映射,需要处理映射冲突 // 8. 字典:以散列表为基础,以<key, value>作为一个元素结构的存储方式 struct Set { int* Keys; int** Values; int count; int* operator [] (int key) { for(int i = 0; i< count; i++) { if(Keys[i] == key) return Values[i]; } return NULL; //未找到 } }; struct Dictionary { int* Keys; int* Values; };
3. 容器
//C++标准库已经根据数据结构,提供了各种默认的库 //vector, list, deque,queue, stack, map, set等 //如dictionary, tree, graph等高级数据结构也有第三方库支持 //vector是可变数组容器 #include<vector> #include<iostream> using namespace std; int main() { //vector使用模板进行声明 vector<int> intArr = { 1,2,3 }; //属性操作 intArr.size(); //intArr内已经存放的元素的数目 intArr.empty(); //判断intArr是否为空 //访问操作 intArr[5];//如果索引不存在,系统会崩溃 intArr.at(5);//同上,但是会抛出异常 intArr.front();// 返回vector中头部的元素的引用 intArr.back();// 返回vector中尾部的元素的引用 //添加操作: intArr.push_back(6);//在迭代器的尾部添加一个元素 intArr.insert(intArr.begin() + 2, 6); //在第二个位置,插入6 //删除操作: intArr.erase(intArr.begin() + 2);// 删除人人迭代器指定的元素,返回被删除元素之后的元素的迭代器。(效率很低,最好别用) intArr.clear();//清空所有元素 return 0; }
4. 练习
#include<iostream> using namespace std; void func(int value) { if (value < 0) { throw "Error Here"; cout << "Will not Run to Here"; } else { //... } } int main() { try { func(10); func(-10); func(10); } catch(string error) { cout << error; } return 0; }
//使用模板与结构体,声明模板数组 template<class T> struct TemplateArray { T* array; int count; TemplateArray(int count) { this->count = count; array = new T[count]; } T& operator [] (int index) { if(index >= count || index <0) throw "out of range" else return array[index]; } }; int main() { TemplateArray<int> array = TemplateArray<int>(10); for (int i = 0; i < array.count; i++) { try { array[i] = i; cout << array[i] << endl; } catch(string error) { continue; } } return 0; }
//创建链表节点类与链表类 //创建以下虚函数的**声明** //1. 创建链表 //2. 插入链表节点 //3. 删除链表节点 template<class LN> class ListNode { public: LN NodeValue; ListNode<LN>* PreNode; ListNode<LN>* NextNode; }; template<class L> class List { public: ListNode<L>* Head; virtual void Create() {} virtual void Insert(ListNode<L>* preNode, L value) {} virtual void Delete(ListNode<L>* deleteNode) {} }; //继承链表类创建栈类 //实例化创建栈方法 //实现出栈入栈方法 template<class Q> class Stack: public List<Q> { void Create() override { this->Head = nullptr; } void Push(Q value) { ListNode<Q> newNode = new ListNode<Q>(); newNode.NodeValue = value; if (this->Head == nullptr) { newNode.PreNode = nullptr; newNode.NextNode = nullptr; } else { this->Head->NextNode = newNode; newNode.PreNode = this->Head; newNode.NextNode = nullptr; this->Head = newNode; } } Q* Pop(Q value) { if (this->Head == nullptr) return nullptr; else { ListNode<Q> returnNode = this->Head; this->Head = this->Head->PreNode; return returnNode; } } }; //实现二叉查找树:左子树小于树根,右子树大于等于树根 //实现二叉查找树节点插入 class BiTree { int data; BiTree* lchild; BiTree* rchild; BiTree* InsertBST(BiTree* t, int key) { if (t == nullptr) { t = new BiTree(); t->lchild = t->rchild = nullptr; t->data = key; return t; } //递归插入 if (key < t->data) t->lchild = InsertBST(t->lchild, key); else t->rchild = InsertBST(t->rchild, key); return t; } BiTree* CreateBiTree(BiTree* tree, int d[], int n) { for (int i = 0; i < n; i++) tree = InsertBST(tree, d[i]); } }; //map容器使用map<key, value>的形式保存数据 //使用map容器保存语文、数学、英语成绩 //打印map中存储的英语成绩 #include<map> #include<string> #include<iostream> using namespace std; void Mark() { map<string, double> marks; marks.insert(map<string, double>::value_type("语文", 90)); marks.insert(map<string, double>::value_type("数学", 90)); marks.insert(map<string, double>::value_type("英语", 90)); marks["语文"] == 45; cout << marks["英语"]; }
5. 算法
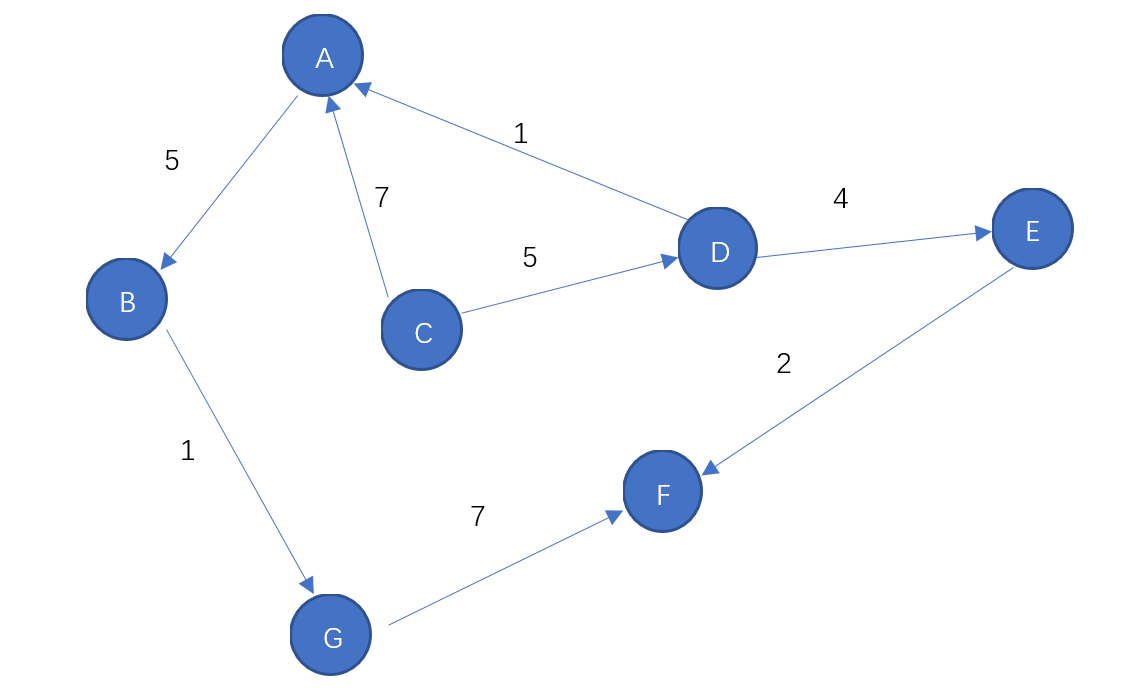
迪杰斯特拉最短路径算法:以节点为遍历对象,最基本的算法只能解决有向正权值图
算法经过多次遍历,找到点之间的最短路径,以矩阵dis[source][des]表示
若只需要找到某一点的最短路径,可以简化为以下两个集合,
S{ }:该集合表示已经找到最短路径的顶点集合
U{ }:该集合表示未找到最短路径的顶点集合
例子:找到从C点出发,到达各顶点的最短路径
初始值:
S = { C(C,0 }
U = { A(CA,7),B(CB,-1),D(CD,5),E(CE,-1),F(CF,-1),G(CG,-1) }
第一次:
从U中找到路径最短的节点,D(CD,5)加入到S中
S = { C(C,0),D(CD,5)}
U = { A(CA,7),B(CB,-1),E(CE,-1),F(CF,-1),G(CG,-1) }
以C为起点,可以途径S中的点,更新U:这个过程称为松弛
如,A(CA,7),A(CDA,6),因此选取后者
更新后的U = { A(CDA,6),B(CB,-1),E(CDE,9),F(CF,-1),G(CG,-1) }
最终结果:
S = { C(C,0),D(CD,5)}
U = { A(CDA,6),B(CB,-1),E(CDE,9),F(CF,-1),G(CG,-1) }
第二次:
S = { C(C,0),D(CD,5),A(CDA,6)}
U = {B(CDAB,11),E(CDE,9),F(CF,-1),G(CG,-1) }
第三次:
S = { C(C,0),D(CD,5),A(CDA,6),E(CDE,9)}
U = {B(CDAB,11),F(CDEF,11),G(CG,-1) }
第四次:
S = { C(C,0),D(CD,5),A(CDA,6),E(CDE,9),B(CDAB,11)}
U = {F(CDEF,11),G(CDABG,12) }
第五次:
S = { C(C,0),D(CD,5),A(CDA,6),E(CDE,9),B(CDAB,11)}
U = {F(CDEF,11),G(CDABG,12) }
第六次:
S = { C(C,0),D(CD,5),A(CDA,6),E(CDE,9),B(CDAB,11),F(CDEF,11)}
U = {G(CDABG,12) }
第七次:
S = {C,D,A,E,B,F,G},U = { }
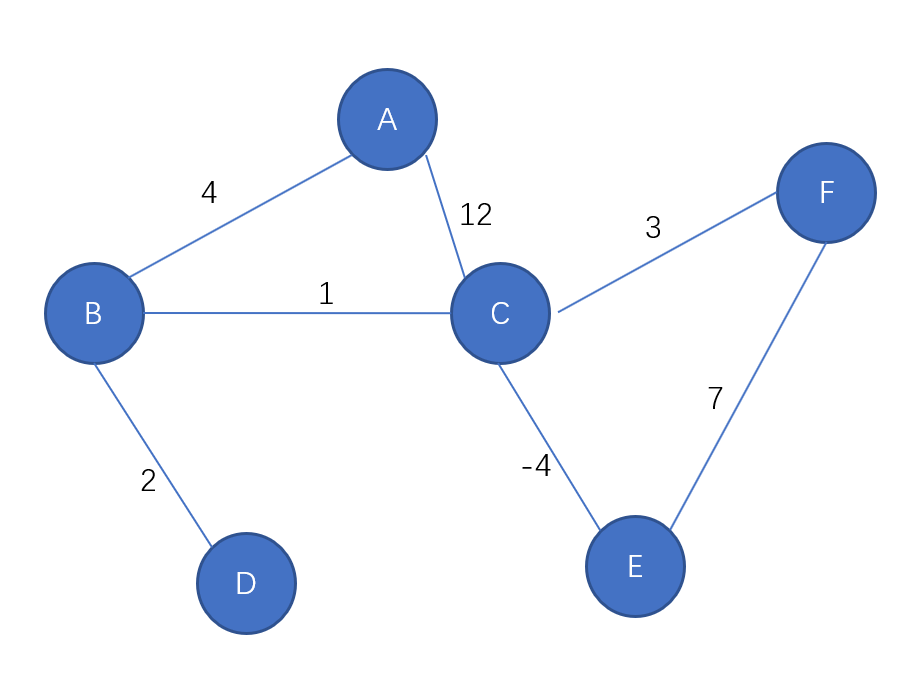
Ford最短路径算法:以边为松弛对象
最长的最短路径为顶点数n-1,因此遍历的次数为顶点数n-1
初始化:
A(A,0),B(-1),C(-1),D(-1),E(-1),F(-1)
第一次迭代:通过一条边
|
对比组 |
A(A,0) |
B(AB,4) |
C(AC,12) |
D(-1) |
E(-1) |
F(-1) |
|
原始组 |
A(A,0) |
B(-1) |
C(-1) |
D(-1) |
E(-1) |
F(-1) |
|
结果组 |
A(A,0) |
B(AB,4) |
C(AC,12) |
D(-1) |
E(-1) |
F(-1) |
第二次迭代:通过两条边‘
|
对比组 |
A(A,0) |
B(ACB,13) |
C(ABC,5) |
D(ABD,6) |
E(ACE,8) |
F(ACF,15) |
|
原始组 |
A(A,0) |
B(AB,4) |
C(AC,12) |
D(-1) |
E(-1) |
F(-1) |
|
结果组 |
A(A,0) |
B(AB,4) |
C(ABC,5) |
D(ABD,6) |
E(ACE,8) |
F(ACF,15) |
第三次迭代:通过三条边
|
对比组 |
A(A,0) |
B(-1) |
C(-1) |
D(ACBD,15) |
E(ACFE,22) E(ABCE,1) |
F(ACEF,15) F(ABCF,8) |
|
原始组 |
A(A,0) |
B(AB,4) |
C(ABC,5) |
D(ABD,6) |
E(ACE,8) |
F(ACF,15) |
|
结果组 |
A(A,0) |
B(AB,4) |
C(ABC,5) |
D(ABD,6) |
E(ABCE,1) |
F(ABCF,8) |
第四次迭代:通过四条边
|
对比组 |
A(A,0) |
B(-1) |
C(-1) |
D(-1) |
E(ABCFE,15) |
F(ABCEF,8) |
|
原始组 |
A(A,0) |
B(AB,4) |
C(ABC,5) |
D(ABD,6) |
E(ACE,8) |
F(ACF,15) |
|
结果组 |
A(A,0) |
B(AB,4) |
C(ABC,5) |
D(ABD,6) |
E(ABCE,1) |
F(ABCF,8) |
第五次迭代:通过五条边,n-1=5,结束遍历
6. 作业
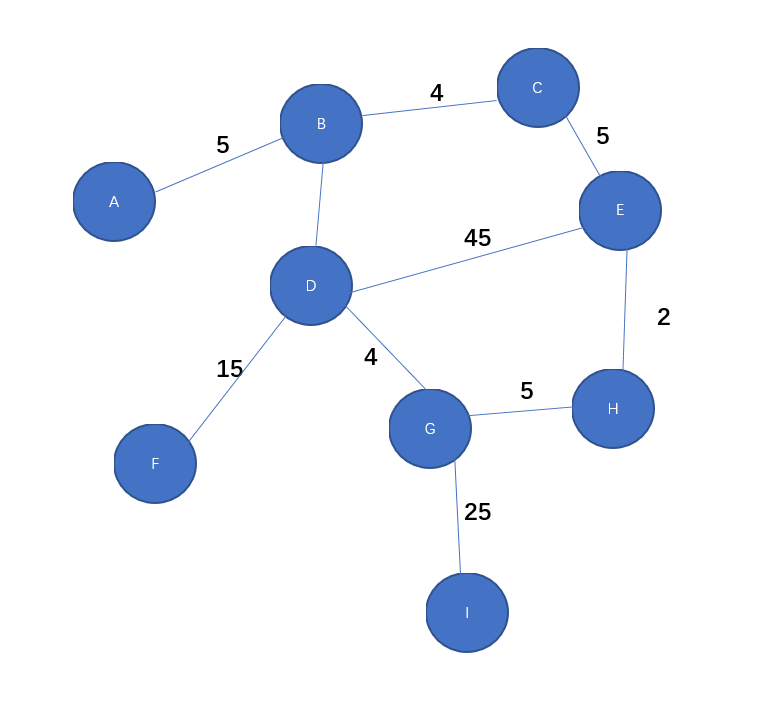
创建加权图的数据结构,并利用该结构保存如下图的网络,创建方法计算任意两点间的最短路径(如从E点到F点)。
可以自己创建数据结构,也可自行搜索使用第三方,但是最短路径算法必须自己实现。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号