


Perl语言入门-第八章-以正则表达式进行匹配-习题
1. 题目


2. 代码与输出
1 #-----------------------------------------------------------#
2 # Source: Learning Perl, chapter8,exercise-1
3 # Date: 2012-01-18
4 # Author: xiaodongrush
5 #-----------------------------------------------------------#
6 use 5.010;
7 while(<>) {
8 chomp;
9 if($_ =~ m|match|) {
10 say "<$`><$&><$'>";
11 }
12 }
13 #-----------------------------------------------------------#
14 # 1. /match/ 是对 m/match/的简写
15 # m/match/,m|match|,m<match>,m{match}这些都是等价的
16 # 2. =~可以匹配指定的变量
17 #-----------------------------------------------------------#
2 # Source: Learning Perl, chapter8,exercise-1
3 # Date: 2012-01-18
4 # Author: xiaodongrush
5 #-----------------------------------------------------------#
6 use 5.010;
7 while(<>) {
8 chomp;
9 if($_ =~ m|match|) {
10 say "<$`><$&><$'>";
11 }
12 }
13 #-----------------------------------------------------------#
14 # 1. /match/ 是对 m/match/的简写
15 # m/match/,m|match|,m<match>,m{match}这些都是等价的
16 # 2. =~可以匹配指定的变量
17 #-----------------------------------------------------------#

1 #-----------------------------------------------------------#
2 # Source: Learning Perl, chapter8,exercise-2
3 # Date: 2012-01-18
4 # Author: xiaodongrush
5 #-----------------------------------------------------------#
6 use 5.010;
7 while(<>) {
8 chomp;
9 if($_ =~ m|\b\w*a\b|) {
10 say "<$`><$&><$'>";
11 }
12 }
13 #-----------------------------------------------------------#
14 # 1. \w等价于[A-Za-z0-9_],即字母、数字和下划线
15 # 2. \b是表示单词开始或结束位置
16 # 3. 不能匹配到Mrs._Wilma_Flintsone,因为下划线属于\w,为\b
17 # 匹配“非\w”的位置
18 #-----------------------------------------------------------#
2 # Source: Learning Perl, chapter8,exercise-2
3 # Date: 2012-01-18
4 # Author: xiaodongrush
5 #-----------------------------------------------------------#
6 use 5.010;
7 while(<>) {
8 chomp;
9 if($_ =~ m|\b\w*a\b|) {
10 say "<$`><$&><$'>";
11 }
12 }
13 #-----------------------------------------------------------#
14 # 1. \w等价于[A-Za-z0-9_],即字母、数字和下划线
15 # 2. \b是表示单词开始或结束位置
16 # 3. 不能匹配到Mrs._Wilma_Flintsone,因为下划线属于\w,为\b
17 # 匹配“非\w”的位置
18 #-----------------------------------------------------------#

1 #-----------------------------------------------------------#
2 # Source: Learning Perl, chapter8,exercise-3
3 # Date: 2012-01-18
4 # Author: xiaodongrush
5 #-----------------------------------------------------------#
6 use 5.010;
7 while(<>) {
8 chomp;
9 if($_ =~ m|\b(\w*a)\b|) {
10 say "<$`><$&><$'>";
11 say '$1 contains ' . "\'$1\'";
12 }
13 }
14 #-----------------------------------------------------------#
2 # Source: Learning Perl, chapter8,exercise-3
3 # Date: 2012-01-18
4 # Author: xiaodongrush
5 #-----------------------------------------------------------#
6 use 5.010;
7 while(<>) {
8 chomp;
9 if($_ =~ m|\b(\w*a)\b|) {
10 say "<$`><$&><$'>";
11 say '$1 contains ' . "\'$1\'";
12 }
13 }
14 #-----------------------------------------------------------#

1 #-----------------------------------------------------------#
2 # Source: Learning Perl, chapter8,exercise-4
3 # Date: 2012-01-18
4 # Author: xiaodongrush
5 #-----------------------------------------------------------#
6 use 5.010;
7 while(<>) {
8 chomp;
9 if($_ =~ m|\b(?<word>\w*a)\b|) {
10 say "<$`><$&><$'>";
11 say 'word contains ' . "\'$+{word}\'";
12 }
13 }
14 #-----------------------------------------------------------#
15 # 1. 定义命名捕获 (?<命名>待捕获模式串)
16 # 使用命名捕获 $+{命名}
17 #-----------------------------------------------------------#
2 # Source: Learning Perl, chapter8,exercise-4
3 # Date: 2012-01-18
4 # Author: xiaodongrush
5 #-----------------------------------------------------------#
6 use 5.010;
7 while(<>) {
8 chomp;
9 if($_ =~ m|\b(?<word>\w*a)\b|) {
10 say "<$`><$&><$'>";
11 say 'word contains ' . "\'$+{word}\'";
12 }
13 }
14 #-----------------------------------------------------------#
15 # 1. 定义命名捕获 (?<命名>待捕获模式串)
16 # 使用命名捕获 $+{命名}
17 #-----------------------------------------------------------#

1 #-----------------------------------------------------------#
2 # Source: Learning Perl, chapter8,exercise-5
3 # Date: 2012-01-18
4 # Author: xiaodongrush
5 #-----------------------------------------------------------#
6 use 5.010;
7 while(<>) {
8 chomp;
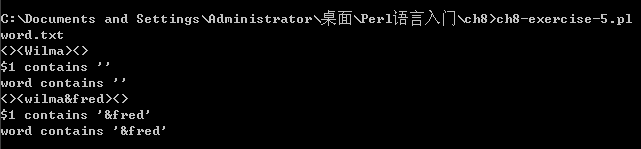
9 if($_ =~ m|\b\w*a\b(?<word>.{0,5})|) {
10 say "<$`><$&><$'>";
11 say '$1 contains ' . "\'$1\'";
12 say 'word contains ' . "\'$+{word}\'";
13 }
14 }
15 #-----------------------------------------------------------#
16 # 1. 通用量词,{0,5} 0次到5次,{0,}0次或者以上
17 #-----------------------------------------------------------#
2 # Source: Learning Perl, chapter8,exercise-5
3 # Date: 2012-01-18
4 # Author: xiaodongrush
5 #-----------------------------------------------------------#
6 use 5.010;
7 while(<>) {
8 chomp;
9 if($_ =~ m|\b\w*a\b(?<word>.{0,5})|) {
10 say "<$`><$&><$'>";
11 say '$1 contains ' . "\'$1\'";
12 say 'word contains ' . "\'$+{word}\'";
13 }
14 }
15 #-----------------------------------------------------------#
16 # 1. 通用量词,{0,5} 0次到5次,{0,}0次或者以上
17 #-----------------------------------------------------------#
1 #-----------------------------------------------------------#
2 # Source: Learning Perl, chapter8,exercise-6
3 # Date: 2012-01-18
4 # Author: xiaodongrush
5 #-----------------------------------------------------------#
6 use 5.010;
7 while(<>) {
8 chomp;
9 if($_ =~ m|\s$|) {
10 say "|$`|$&|$'|";
11 say "|$_|";
12 }
13 }
14 #-----------------------------------------------------------#
15 # 如果匹配成功,那么$&将是字符串的最后一个空白,而$'是空串
16 # $`是除了最后一个空白的前面所有字符
17 #-----------------------------------------------------------#
2 # Source: Learning Perl, chapter8,exercise-6
3 # Date: 2012-01-18
4 # Author: xiaodongrush
5 #-----------------------------------------------------------#
6 use 5.010;
7 while(<>) {
8 chomp;
9 if($_ =~ m|\s$|) {
10 say "|$`|$&|$'|";
11 say "|$_|";
12 }
13 }
14 #-----------------------------------------------------------#
15 # 如果匹配成功,那么$&将是字符串的最后一个空白,而$'是空串
16 # $`是除了最后一个空白的前面所有字符
17 #-----------------------------------------------------------#

3. 文件

