


阅读笔记-精通正则表达式-第1章-正则表达式入门
1. 解决实际问题
通过几个实例说明正则表达式是十分有用的:
· 检查许多文件,确保每一行中的"SetSize"的出现次数与"ResetSize"的出现次数一样多,而且要保证大小写不敏感。
· 处理远端机器上的某些E-mail,把邮件的标题作为列表整理出来。使用了grep工具和正则表达式"^(From|Subject)"
· 查找一个特殊的(5000行!)邮件。使用sed工具和正则表达式。
2. 作为编程语言的正则表达式
完整的正则表达式由两种字符构成。特殊字符称为元字符,普通字符称为文字。如果把正则表达式比作语言,那么普通字符可以理解为语言的单词,而特殊字符可以理解为语言的语法。比如:"*.txt"中的"*"是元字符,"txt"是文字。
3. Egrep元字符
Egrep在指定了正则表达式和需要检索的文件之后,会尝试用正则表达式来匹配每个文件中的每一行,并显示能够匹配的行。比如: % egrep '^(From|Subject):' mailbox-file
Egrep的元字符列表:
| 元字符 | 名称 | 匹配对象 |
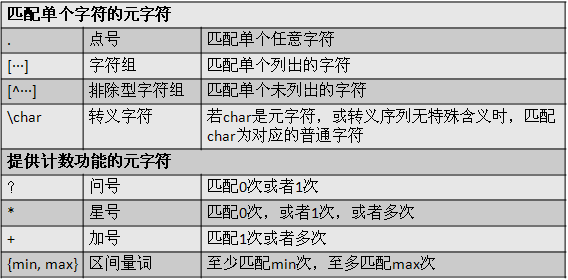
| . | 点号 | 单个任意字符 |
| [···] | 字符组 | 列出的任意字符 |
| [^···] | 排除型字符组 | 未列出的任意字符 |
| ^ | 脱字符 | 行的起始位置 |
| $ | 美元符 | 行的终止位置 |
| \< | 反斜杠-小于 | 单词的起始位置(某些版本的egrep可能不支持) |
| \> | 反斜杠-大于 | 单词的终止位置(某些版本的egrep可能不支持) |
| | | 竖线 | 匹配分隔两边的任意一个表达式 |
| (···) | 括号 | 限制竖线的作用范围,其他功能下文讨论 |
3.1 行的开始和结束
脱字符'^'表示行的开始,美元符'$'表示行的结束。
^cat 表示以cat开头的行
^cat$ 表示只包含cat的行
cat$ 表示以cat结尾的行
^$ 表示空行
^ 无意义,每一行都能匹配
$ 无意义,每一行都能匹配
3.2 字符组匹配
字符组[]内部的两个元字符是连字符'-'和脱字符'^'。
只有在字符组[]的内部,'-'连字符才有可能是一个元字符,确切的说[-1-9]中的第一个连字符是一个普通字符,第二个连字符是元字符。
我理解的'-'是元字符的条件:首先在字符组内部,然后连字符两侧是数字或者小写字母或者大写字母。对于A-f是不是呢,是按照字符编码计算吗?如果[0-3]表示(0|1|2|3),那么[3-0]能够表示吗?
关于'^',[^1-6]表示除1-6以外的任意一个字符。我们知道'^'本身就是一个元字符,^cat表示以cat开头的行,那么cat^cat表示什么呢,这样的表达式是不是错误的呢?相应的cat$表示以cat结尾的行,cat$cat又表示什么呢?
关于字符组[]本身,能嵌套吗,如果能够嵌套,最多嵌套几层呢,比如[0[123]4]?
3.2 用点号匹配任意字符
点号'.'匹配任意一个字符。
例如,如果我们需要搜索03/19/76、03-19-76或者03.19.76,可以使用03[-./]19[-./]76或者可以尝试03.19.76
此处值得注意的是在字符组[]内部,元字符的意义是不同的,比如[-./]中的点号是普通字符'.',而非任意字符。
3.3 多选结构
竖线'|'匹配两边的任意一个表达式,括号'(···)'限制竖线的作用范围。比如:^(From|Subject|Date):
表示:1. 行起始,然后是From,然后是:
2. 行起始,然后是Subject,然后是:
3. 行起始,然后是Date,然后是:
同样质疑,括号的嵌套是否可以呢?
3.4 忽略大小
比如,要忽略From的大小写,可能需要把正则表达式From改写为[Ff][Rr][Oo][Mm],这样无疑是十分麻烦的。使用egrep本身的参数可以实现忽略大小写:% egrep -i '^(From|Subject):' mailbox-file
参数i告诉egrep忽略大小写,不过这样就是忽略所有的大小写了,如果要忽略部分的大小写,估计只能去改正则表达式了。
3.5 单词分界符
某些版本的egrep对单词的识别提供了有限的支持:也就是单词分界符的匹配。比如/<cat会匹配以cat开始的单词,cat\>会匹配以cat为结束的单词,/<cat/>匹配cat这个单词,注意
\>cat表示以cat
3.6 可选项元素
元字符'?',代表可选项。把它加在一个字符的后面,就表示词除允许出现0个或者1个这样的字符。
例如:(July|Jul) 等价于July? (4th|4)等价于4(th)?
3.7 其他量词:重复出现
元字符'+',表示之前的元素出现1次或者多次,元字符'*',表示之前的元素出现0次,1次或者多次。
" ?"可以匹配0个或者1个空格," +"可以表示1个或者多个空格," *"可以表示0个,1个或者多个空格。
比如:要匹配<HR SIZE=14>这样的tag,考虑到空格的情况,正则为<HR +SIZE *= *14 *>,为了不受14的限制,可以进一步改为<HR +SIZE *= *[0-9]+ *>
3.8 规定重现次数的范围
某些版本的egrep可以使用元字符序列来自定义重现次数的区间,{min, max}称为区间量词。{3,12}能够允许前面的字符出现3到12次之间。
比如:有人使用[a-zA-Z]{1,5}来匹配美国的股票代码。
3.9 括号及反向引用
已见过括号的两种用途,限制多选项的范围和将若干个字符组合为一个单元。 在许多流派的正则表达式中,括号还能够“记住”它们包含的子表达式匹配的文本。比如([a-z])([0-9])\1\2,\1代表[a-z]匹配的内容,\2表示[0-9]匹配的内容。
对于a1a1这样的文本能够匹配成功,对于a1a2这样的文本不能匹配成功。
括号的这个作用就是为了反向引用“捕获”文本。\1,\2分别匹配之前的第一组、第二组括号内的字表达式匹配的文本。
如下命令: %egrep -i '\<([a-z]+) + \1\>' files 能够匹配文件中the the这样的重复情况。
3.10 神奇的转义
如果需要匹配的某个字符本身是元字符,那么可以使用反斜杠\加上该字符来表示。这样的方法适用于所有的元字符,但是在字符数组内无效,即[\.cat)]中的点依旧是元字符,表示任意一个字符,而\是普通字符。
比如:对于元字符点来说,本身代表的是任意字符:ega\.att\.com可以匹配ega.att.com,而不能匹配ega1att1com。对于括号来说,\([a-zA-Z]\)可以匹配一个括号内的单词。\( *[0-9]+ *,[0-9]+ *\)可以匹配任意的开区间,例如(22 , 45), ( 222, 33 ),\( *[0-9]+ *,[0-9]+ *\]可以匹配任意的左开右闭区间。
4. egrep 元字符总结

5. 感受
这一章主要是介绍了一些正则表达式的元字符、转义、反向引用的用法。基本上,是个热身活动,需要一定的记忆,更深入的理解还需要阅读后面的几个重点的章节。

