
计算机组成原理=指令、栈、内存、ELF和静态链

女神镇楼
1、计算机指令
从硬件的角度来看,CPU 就是一个超大规模集成电路,通过电路实现了加法、乘法乃至各种各样的处理逻辑。
从软件的角度来讲,CPU 就是一个执行各种计算机指令(Instruction Code)的逻辑机器。这里的计算机指令,就好比一门 CPU 能够听得懂的语言,也可以把它叫作机器语言(Machine Language)。
不同的 CPU 能够听懂的语言不太一样。比如,个人电脑用的是 Intel 的 CPU,苹果手机用的是 ARM 的 CPU。这两者能听懂的语言就不太一样。类似这样两种 CPU 各自支持的语言,就是两组不同的计算机指令集。
一个计算机程序,不可能只有一条指令,而是由成千上万条指令组成的。但是 CPU 里不能一直放着所有指令,所以计算机程序平时是存储在存储器中的。这种程序指令存储在存储器里面的计算机,我们就叫作存储程序型计算机(Stored-program Computer)。
2、代码怎么变成机器码
把整个程序翻译成一个汇编语言(ASM,Assembly Language)的程序,这个过程我们一般叫编译(Compile)成汇编代码。
针对汇编代码,我们可以再用汇编器(Assembler)翻译成机器码(Machine Code)。这些机器码由“0”和“1”组成的机器语言表示。这一条条机器码,就是一条条的计算机指令。这样一串串的 16 进制数字,就是我们 CPU 能够真正认识的计算机指令。
从高级语言到汇编代码,再到机器码,就是一个日常开发程序,最终变成了 CPU 可以执行的计算机指令的过程。
3、解析指令和机器码
常见的指令可以分成五大类。
第一类是算术类指令。我们的加减乘除,在 CPU 层面,都会变成一条条算术类指令。
第二类是数据传输类指令。给变量赋值、在内存里读写数据,用的都是数据传输类指令。
第三类是逻辑类指令。逻辑上的与或非,都是这一类指令。
第四类是条件分支类指令。日常我们写的“if/else”,其实都是条件分支类指令。
最后一类是无条件跳转指令。写一些大一点的程序,我们常常需要写一些函数或者方法。在调用函数的时候,其实就是发起了一个无条件跳转指令。

4、CPU 是如何执行指令的
逻辑上,我们可以认为,CPU 其实就是由一堆寄存器组成的。而寄存器就是 CPU 内部,由多个触发器(Flip-Flop)或者锁存器(Latches)组成的简单电路。N 个触发器或者锁存器,就可以组成一个 N 位(Bit)的寄存器,能够保存 N 位的数据。比方说, 64 位 Intel 服务器,寄存器就是 64 位的。
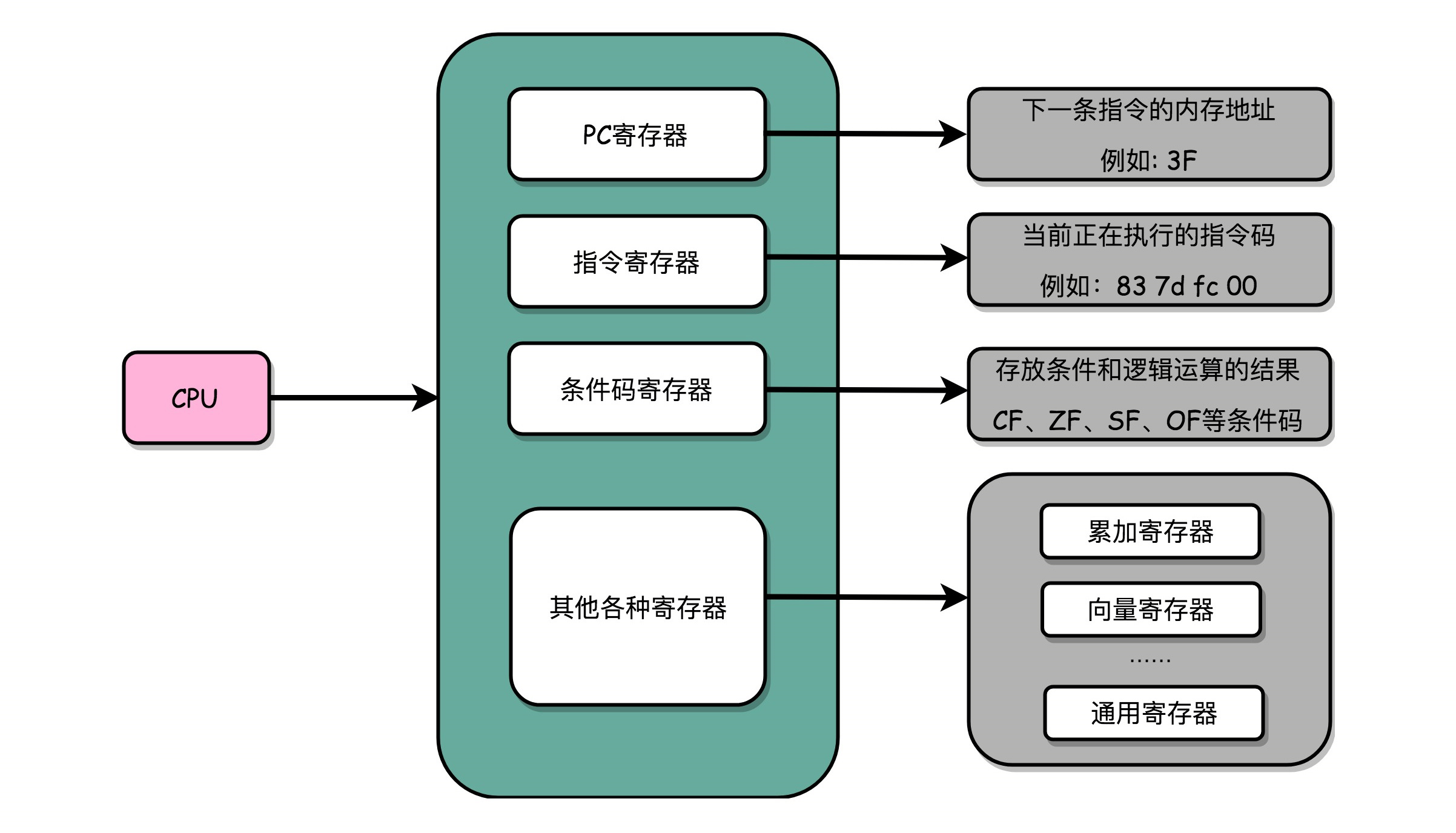
一个 CPU 里面会有很多种不同功能的寄存器。介绍三种比较特殊的:
一个是 PC 寄存器(Program Counter Register),我们也叫指令地址寄存器(Instruction Address Register)。顾名思义,它就是用来存放下一条需要执行的计算机指令的内存地址。
第二个是指令寄存器(Instruction Register),用来存放当前正在执行的指令。
第三个是条件码寄存器(Status Register),用里面的一个一个标记位(Flag),存放 CPU 进行算术或者逻辑计算的结果。
除了这些特殊的寄存器,CPU 里面还有更多用来存储数据和内存地址的寄存器。这样的寄存器通常一类里面不止一个。通常根据存放的数据内容来给它们取名字,比如整数寄存器、浮点数寄存器、向量寄存器和地址寄存器等等。有些寄存器既可以存放数据,又能存放地址,就叫它通用寄存器。
5、程序栈
程序中函数相互调用,是在原来顺序执行的指令过程里,执行了一个内存地址的跳转指令,让指令从原来顺序执行的过程里跳开,从新的跳转后的位置开始执行。在对应函数的指令执行完了之后,还要再回到函数调用的地方,继续执行 call 之后的指令。
那有没有一个可以不跳转回到原来开始的地方,来实现函数的调用呢?直觉上似乎有这么一个解决办法。可以把调用的函数指令,直接插入在调用函数的地方,替换掉对应的 call 指令,然后在编译器编译代码的时候,直接就把函数调用变成对应的指令替换掉。
不过,这个方法有些问题。如果函数 A 调用了函数 B,然后函数 B 再调用函数 A,我们就得面临在 A 里面插入 B 的指令,然后在 B 里面插入 A 的指令,这样就会产生无穷无尽地替换。就好像两面镜子面对面放在一块儿,任何一面镜子里面都会看到无穷多面镜子。
换个方法:把后面要跳回来执行的指令地址给记录下来,像前面讲 PC 寄存器一样,可以专门设立一个“程序调用寄存器”,来存储接下来要跳转回来执行的指令地址。等到函数调用结束,从这个寄存器里取出地址,再跳转到这个记录的地址,继续执行就好了。
但是在多层函数调用里,简单只记录一个地址也是不够的。在调用函数 A 之后,A 还可以调用函数 B,B 还能调用函数 C。这一层又一层的调用并没有数量上的限制。在所有函数调用返回之前,每一次调用的返回地址都要记录下来,但是CPU 里的寄存器数量并不多。
一个更完善的解决方法:在内存里面开辟一段空间,用栈这个后进先出(LIFO,Last In First Out)的数据结构。栈就像一个乒乓球桶,每次程序调用函数之前,我们都把调用返回后的地址写在一个乒乓球上,然后塞进这个球桶。这个操作其实就是常说的压栈。如果函数执行完了,就从球桶里取出最上面的那个乒乓球,很显然,这就是出栈。拿到出栈的乒乓球,找到上面的地址,把程序跳转过去,就返回到了函数调用后的下一条指令了。如果函数 A 在执行完成之前又调用了函数 B,那么在取出乒乓球之前,需要往球桶里塞一个乒乓球。而从球桶最上面拿乒乓球的时候,拿的也一定是最近一次的,也就是最下面一层的函数调用完成后的地址。乒乓球桶的底部,就是栈底,最上面的乒乓球所在的位置,就是栈顶。

在真实的程序里,压栈的不只有函数调用完成后的返回地址。比如函数 A 在调用 B 的时候,需要传输一些参数数据,这些参数数据在寄存器不够用的时候也会被压入栈中。整个函数 A 所占用的所有内存空间,就是函数 A 的栈帧(Stack Frame)。而实际的程序栈布局,顶和底与乒乓球桶相比是倒过来的。底在最上面,顶在最下面,这样的布局是因为栈底的内存地址是在一开始就固定的。而一层层压栈之后,栈顶的内存地址是在逐渐变小而不是变大。
6、ELF和静态链接
高级编程语言编写的程序,通过编译器编译成汇编代码,然后汇编代码再通过汇编器变成 CPU 可以理解的机器码,于是 CPU 就可以执行这些机器码了。实际上,“C 语言代码 - 汇编代码 - 机器码” 这个过程,在计算机上进行的时候是由两部分组成的。
第一个部分由编译(Compile)、汇编(Assemble)以及链接(Link)三个阶段组成。在这三个阶段完成之后,就生成了一个可执行文件。
第二部分,我们通过装载器(Loader)把可执行文件装载(Load)到内存中。CPU 从内存中读取指令和数据,来开始真正执行程序。

在 Linux 下,可执行文件和目标文件所使用的都是一种叫 ELF(Execuatable and Linkable File Format)的文件格式,中文名字叫可执行与可链接文件格式,这里面不仅存放了编译成的汇编指令,还保留了很多别的数据。Windows 的可执行文件格式是一种叫作 PE(Portable Executable Format)的文件格式。Linux 下的装载器只能解析 ELF 格式而不能解析 PE 格式。
7、程序装载
在运行这些可执行文件的时候,其实是通过一个装载器,解析 ELF 或者 PE 格式的可执行文件。装载器会把对应的指令和数据加载到内存里面来,让 CPU 去执行。装载器需要满足两个要求:
第一,可执行程序加载后占用的内存空间应该是连续的。执行指令的时候,程序计数器是顺序地一条一条指令执行下去。这也就意味着,这一条条指令需要连续地存储在一起。
第二,需要同时加载很多个程序,并且不能让程序自己规定在内存中加载的位置。虽然编译出来的指令里已经有了对应的各种各样的内存地址,但是实际加载的时候,我们其实没有办法确保,这个程序一定加载在哪一段内存地址上。因为我们现在的计算机通常会同时运行很多个程序,可能你想要的内存地址已经被其他加载了的程序占用了。
要满足这两个基本的要求,很容易想到一个办法。那就是可以在内存里面,找到一段连续的内存空间,然后分配给装载的程序,然后把这段连续的内存空间地址,和整个程序指令里指定的内存地址做一个映射。
我们把指令里用到的内存地址叫作虚拟内存地址(Virtual Memory Address),实际在内存硬件里面的空间地址,我们叫物理内存地址(Physical Memory Address)。
程序里有指令和各种内存地址,我们只需要关心虚拟内存地址就行了。对于任何一个程序来说,它看到的都是同样的内存地址。我们维护一个虚拟内存到物理内存的映射表,这样实际程序指令执行的时候,会通过虚拟内存地址,找到对应的物理内存地址,然后执行。因为是连续的内存地址空间,所以我们只需要维护映射关系的起始地址和对应的空间大小就可以了。
8、内存分段
找出一段连续的物理内存和虚拟内存地址进行映射的方法,我们叫分段(Segmentation)。这里的段,就是指系统分配出来的那个连续的内存空间。分段的办法很好,解决了程序本身不需要关心具体的物理内存地址的问题,但它也有一些不足之处,第一个就是内存碎片(Memory Fragmentation)的问题。

解决的办法叫内存交换(Memory Swapping)。把某个程序内存写到硬盘上,然后再从硬盘上读回来到内存里面。不过读回来的时候,不再把它加载到原来的位置,而是紧紧跟在那已经被占用了的某个内存后面。虚拟内存、分段,再加上内存交换,看起来似乎已经解决了计算机同时装载运行很多个程序的问题。不过,这三者的组合仍然会遇到一个性能瓶颈。硬盘的访问速度要比内存慢很多,而每一次内存交换,都需要把一大段连续的内存数据写到硬盘上。所以,如果内存交换的时候,交换的是一个很占内存空间的程序,这样整个机器都会显得卡顿。
9、内存分页
既然问题出在内存碎片和内存交换的空间太大上,那么解决问题的办法就是,少出现一些内存碎片。另外,当需要进行内存交换的时候,让需要交换写入或者从磁盘装载的数据更少一点,这样就可以解决这个问题。这个办法,在现在计算机的内存管理里面,就叫作内存分页(Paging)。
和分段这样分配一整段连续的空间给到程序相比,分页是把整个物理内存空间切成一段段固定尺寸的大小。而对应的程序所需要占用的虚拟内存空间,也会同样切成一段段固定尺寸的大小。这样一个连续并且尺寸固定的内存空间,我们叫页(Page)。从虚拟内存到物理内存的映射,不再是拿整段连续的内存的物理地址,而是按照一个一个页来的。页的尺寸一般远远小于整个程序的大小。在 Linux 下,我们通常只设置成 4KB。
由于内存空间都是预先划分好的,也就没有了不能使用的碎片,而只有被释放出来的很多 4KB 的页。即使内存空间不够,需要让现有的、正在运行的其他程序,通过内存交换释放出一些内存的页出来,一次性写入磁盘的也只有少数的一个页或者几个页,不会花太多时间,让整个机器被内存交换的过程给卡住。
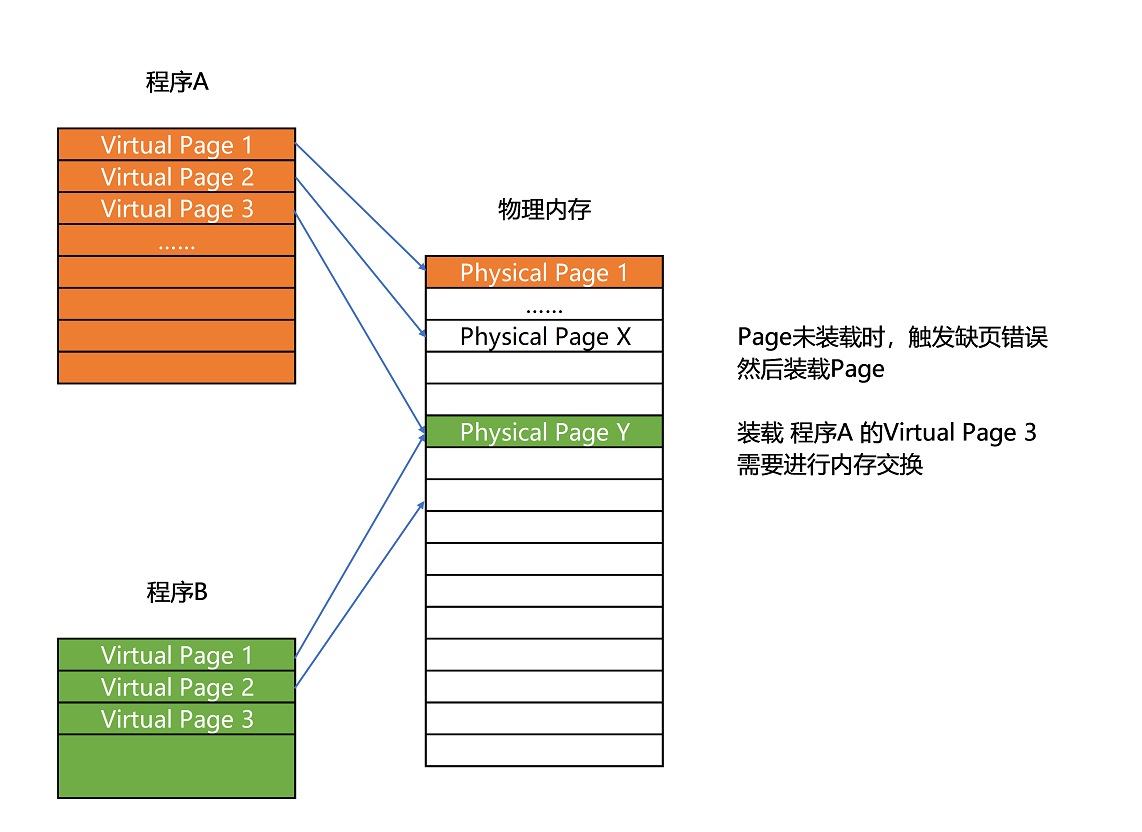
更进一步地,分页的方式使得我们在加载程序的时候,不再需要一次性都把程序加载到物理内存中。我们完全可以在进行虚拟内存和物理内存的页之间的映射之后,并不真的把页加载到物理内存里,而是只在程序运行中,需要用到对应虚拟内存页里面的指令和数据时,再加载到物理内存里面去。
实际上,我们的操作系统,的确是这么做的。当要读取特定的页,却发现数据并没有加载到物理内存里的时候,就会触发一个来自于 CPU 的缺页错误(Page Fault)。操作系统会捕捉到这个错误,然后将对应的页,从存放在硬盘上的虚拟内存里读取出来,加载到物理内存里。这种方式,可以运行那些远大于实际物理内存的程序。同时,这样一来,任何程序都不需要一次性加载完所有指令和数据,只需要加载当前需要用到就行了。
通过虚拟内存、内存交换和内存分页这三个技术的组合,我们最终得到了一个让程序不需要考虑实际的物理内存地址、大小和当前分配空间的解决方案。这些技术和方法,对于我们程序的编写、编译和链接过程都是透明的。这也是我们在计算机的软硬件开发中常用的一种方法,就是加入一个间接层。
通过引入虚拟内存、页映射和内存交换,我们的程序本身,就不再需要考虑对应的真实的内存地址、程序加载、内存管理等问题了。任何一个程序,都只需要把内存当成是一块完整而连续的空间来直接使用。


