
作业缘由:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3363

这是爬取的数据,豆瓣上权利的游戏的影评,将txt文件转换为csv文件

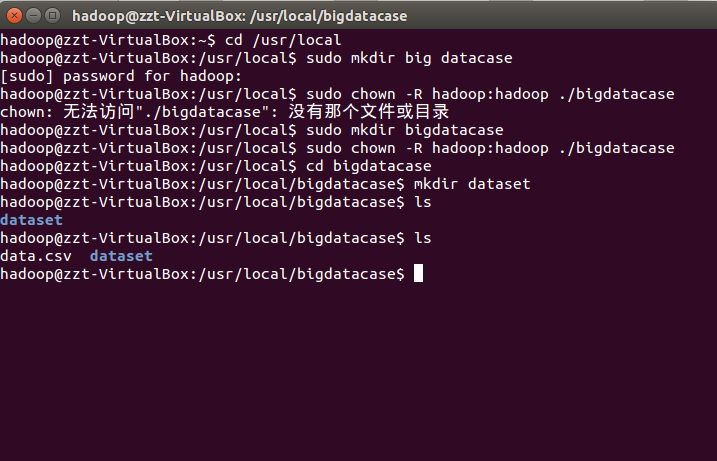
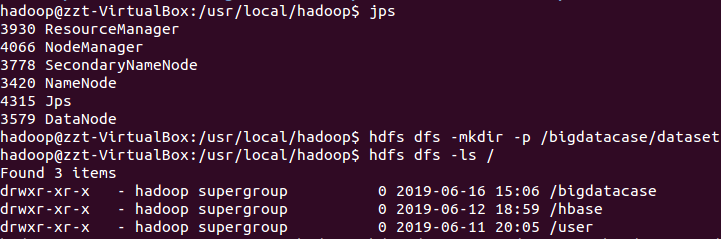
准备工作,开启hadoop,mysql,hive 服务,挂在文件。
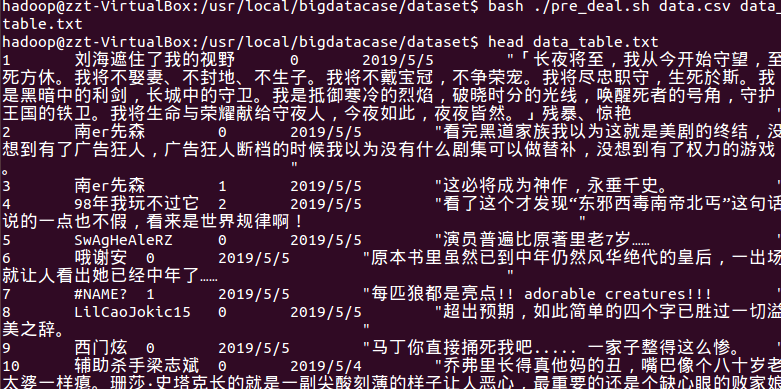
查询爬取的数据
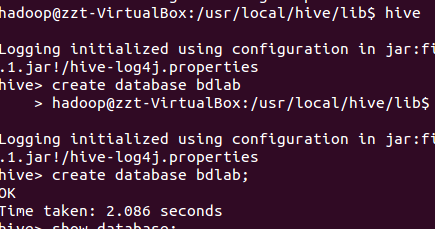
创建表

创建表时的数据类型分类,分别为:第几条、用户名、点赞数、发表时间、评论。
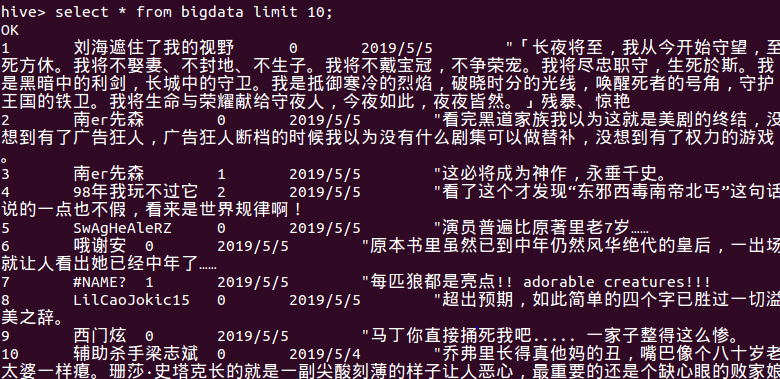
建完后 检查一下 确认无误。
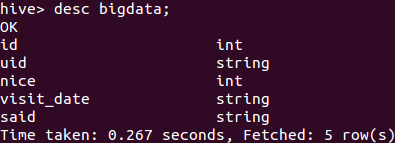
查询表中的数据类型
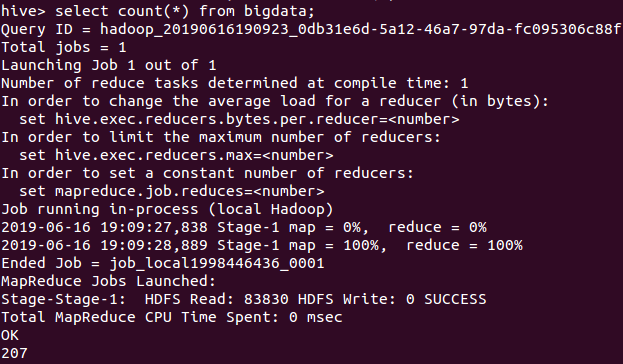
因为豆瓣在未登录下只爬取少量的数据 爬取了207条影评
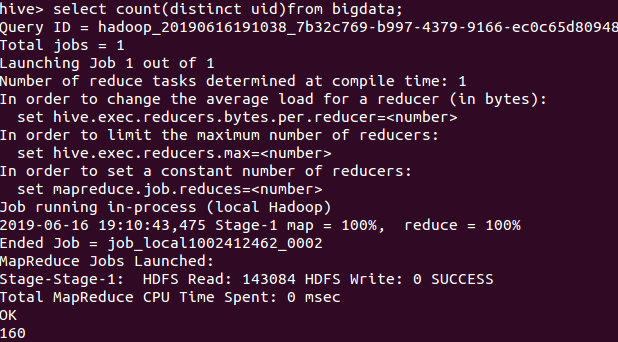
查出UID不重复的数据 有160条
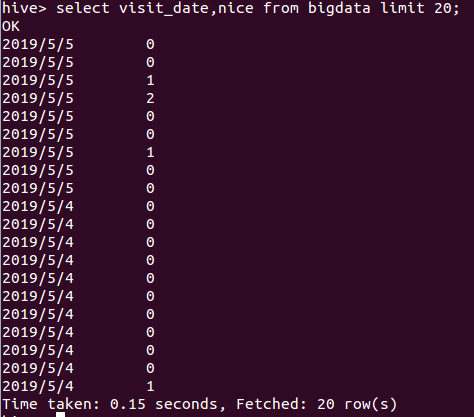
查询时间前20的各点赞数
总结
这次作业是结合本学期学过的所有知识,利用PYHTON爬取出的数据来进行分析,将数据通过HDFS传入数据库MYSQL中,
在HIVE中进行建表和区分数据类型,再利用HIVE中进行特定要求的数据查询,获得所需要的结果。
问题:在实验过程中,将CSV文件导入进取时总是遇到乱码,是因为没有设置为UTF-8模式进行保存才会出现乱码。
还有在HIVE建表时第一列我本应该为用户名,可在表格中是序号,所以我建的第一个表格bigdata_user导致后面的数据类型不规范,
我上网百度了下后删除了表格中的所有数据,并重新建立了一个新表格bigdata。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号