

随笔原有:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/2753
1.列表,元组,字典,集合分别如何增删改查及遍历。
(1)列表
增:
list = ['NBA', 'CBA', 'NCAA', ];
list1 = ['A', 'B', 'C', 'D', 'E'];
list.append('JAMES');
print(list);
list.extend(list1);
print(list);
list.insert(1, 'LA');
print(list);
list[0] = 'NY';
print(list);

删:
list = ['NBA', 'CBA', 'NCAA', ];
del list[1];
print(list)
list.pop()
print(list)
list.remove('NBA')
print(list)

改:
list[1]="a"
print(list)
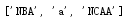
查:
list = ['NBA', 'CBA', 'NCAA', ];
print(list[2]) ##根据下标直接查找列表元素
print(list[1:3])##通过切片方式进行取值
print(list[:])##获取列表所有元素
print(list[-1])##取列表最后一个值
print(list[2:])##取下标后面所有的值
print(list[:3])##取下标前面所有的值
print(list[:1:2])##隔位取值

遍历:
for index in range(len(list)):
print(list[index])

(2)元组
tup1 = ('NBA', 'CBA', 1000, 2000)
tup2 = (1, 2, 3, 4, 5, 8)
tup3 = "a", "b", "c", "d"
print(tup1)
print(tup2)
print(tup3)
print(tup1[0])
print(tup2[1:3])
tup4=tup1+tup2+tup3
print(tup4)

(3)字典
dict = {'Name': 'NVA', 'Age': 12, 'Class': 'First'}
print("dict['Name']: ", dict['Name'])
print("dict['Age']: ", dict['Age'])
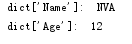
(4)集合
set = {'NBA', 'CBA', 'LA', 'NY', 'GZ'};
set.add('ABC');
print(set);
set.update({123, 222});
print(set);
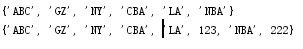
2.总结列表,元组,字典,集合的联系与区别。
列表(list)是Python中最有用的一种内置类型,是处理一组有序项目的数据结构,或者说,是一个有序对象的集合。
元组(tuple)就是不可更改的列表,一旦创建,便不可更改。除了表示的方式有点不一样、元组的元素不可更改,其他的特性与前面学习的列表基本一致。
字典含义和表示都与我们语义上的感觉近似。像小时候查找汉字,我们通过拼音字母(或笔画)进行索引,Python中的字典我们可以自己定义名字,然后通过这个名字查找到对应的数值。这个名字叫做键,对应的数值简称值,所以字典也称键值对。需要注意的是,字典没有顺序一说,所有的值仅能用键获取。
简而言之,字典被看作无序的键值对或有名字的元素列表。
集合是无序的对象集,它和字典一样使用花括号{},但没有键值对的概念。它属于可变的数据类型,一般用于保持序列的唯一性——也就是同样的元素仅出现一次。
在使用时一定要注意集合的无序和唯一两个特点,避免出错。
3.词频统计
-
1.下载一长篇小说,存成utf-8编码的文本文件 file
2.通过文件读取字符串 str
3.对文本进行预处理
4.分解提取单词 list
5.单词计数字典 set , dict
6.按词频排序 list.sort(key=lambda),turple
7.排除语法型词汇,代词、冠词、连词等无语义词
- 自定义停用词表
- 或用stops.txt
8.输出TOP(20)


- 9.可视化:词云
排序好的单词列表word保存成csv文件
import pandas as pd
pd.DataFrame(data=word).to_csv('big.csv',encoding='utf-8')

