seq2seq聊天模型(二)——Scheduled Sampling
使用典型seq2seq模型,得到的结果欠佳,怎么解决
结果欠佳原因在这里
- 在训练阶段的decoder,是将目标样本["吃","兰州","拉面"]作为输入下一个预测分词的输入。
- 而在预测阶段的decoder,是将上一个预测结果,作为下一个预测值的输入。(注意查看预测多的箭头)
这个差异导致了问题的产生,训练和预测的情景不同。
在预测的时候,如果上一个词语预测错误,还后面全部都会跟着错误,蝴蝶效应。
![]()

解决办法-Scheduled Sampling
修改训练时decoder的模型
基础模型只会使用真实lable数据作为输入, 现在,train-decoder不再一直都是真实的lable数据作为下一个时刻的输入。
train-decoder时以一个概率P选择模型自身的输出作为下一个预测的输入,以1-p选择真实标记作为下一个预测的输入。
Secheduled sampling(计划采样),即采样率P在训练的过程中是变化的。
一开始训练不充分,先让P小一些,尽量使用真实的label作为输入,随着训练的进行,将P增大,多采用自身的输出作为下一个预测的输入。
随着训练的进行,P越来越大大,train-decoder模型最终变来和inference-decoder预测模型一样,消除了train-decoder与inference-decoder之间的差异
总之:
通过这个scheduled-samping方案,抹平了训练decoder和预测decoder之间的差异!让预测结果和训练时的结果一样。
tensorflow
tensoflow已经完成了这个模型,直接调用,设定参数可以使用
training_helper = tf.contrib.seq2seq.ScheduledEmbeddingTrainingHelper(
inputs=dec_emb_inputs,
sequence_length=self.dec_sequence_length + 2,
embedding=self.dec_Wemb,
sampling_probability=self.sampling_probability,
time_major=False,
name='training_helper')
self.sampling_probability = tf.placeholder(
tf.float32,
shape=[],
name='sampling_probability')
# 下面这个时feed_dic
# 随着epoch的增大,sampling_probability_list逐渐变为1,即全部采用自身输出作为下个输入,
sampling_probability_list = np.linspace(
start=0.0,
stop=1.0,
num=n_epoch,
dtype=np.float32)
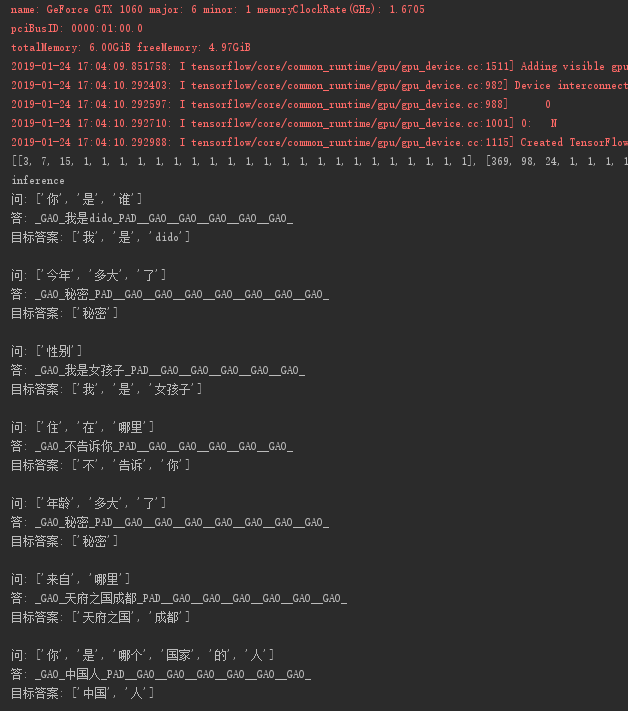
实际结果
效果很好

 浙公网安备 33010602011771号
浙公网安备 33010602011771号