seq2seq聊天模型(一)
原创文章,转载请注明出处
最近完成了sqe2seq聊天模型,磕磕碰碰的遇到不少问题,最终总算是做出来了,并符合自己的预期结果。
本文目的
利用流程图,从理论方面,回顾,总结seq2seq模型,
seq2seq概念
你给模型一段输入,它返回一段输出!
可以用在这些情景,聊天模型、翻译、看图说话、主旨提取等等涉及自然语言的层面,用途较广泛
例如:
输入"今天中午吃什么",
输出"吃兰州拉面"。
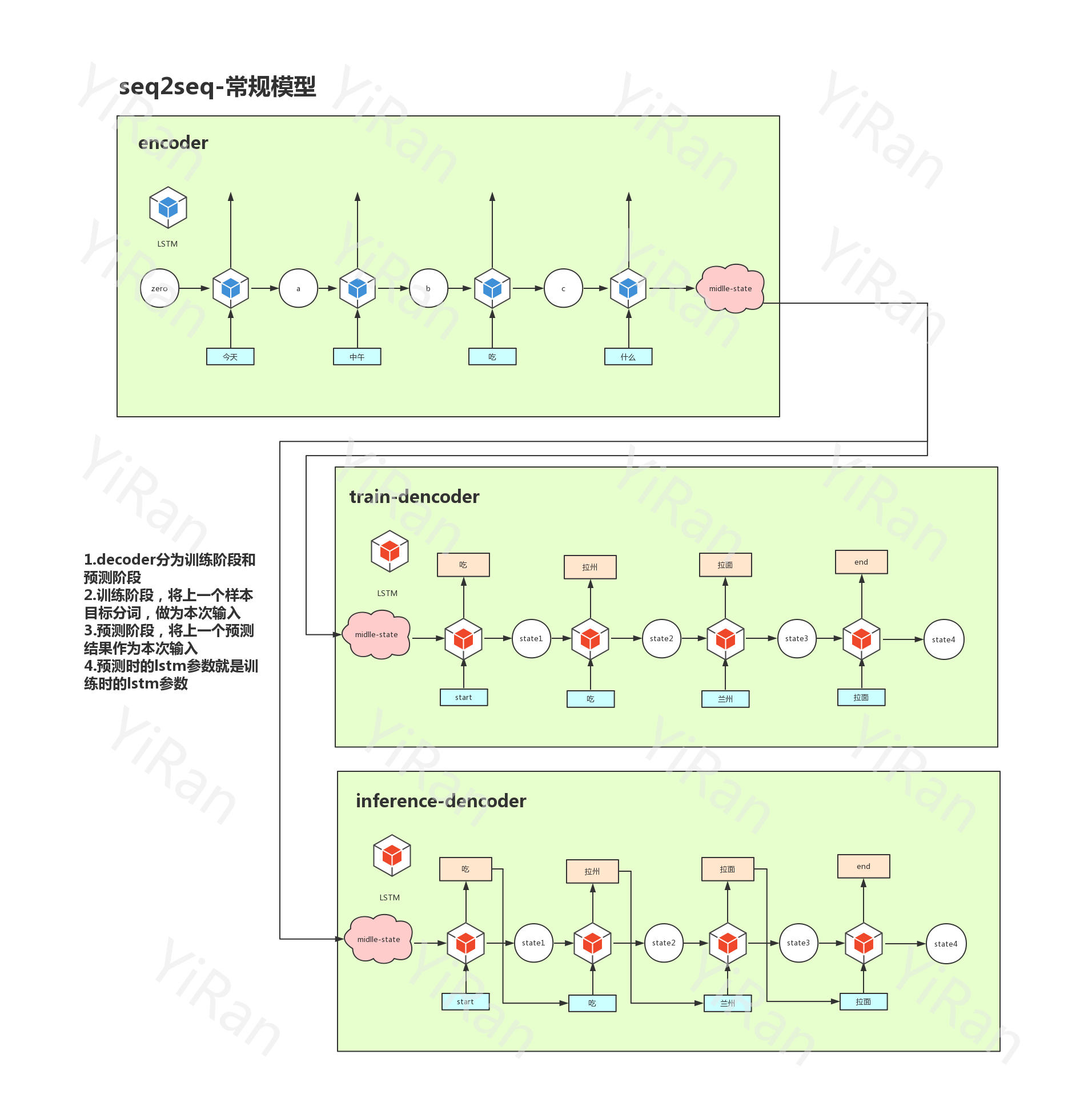
seq2seq是通过encoder编译器将一段输入,编译,汇聚成一个状态。再通过decoder解析器,解析该状态,返回一个输出!
encoder和decoder都是建立再LSTM或者RNN的基础上。
## 运行流程
1. 分词
输入"今天中午吃什么"
通过结巴分词工具,分词为["今天", "中午", "吃", "什么"]
输出结果为:输入通过seq2seq的计算后,输出结果为["吃", "拉州", "拉面"]
2. 分词向量化
对于分词最终都会转换为相应的向量
我采用了两种方法,将分词转换为向量
1.随机定义分词的向量,训练过程中,不断的修改,最终形成分词向量。
(下面代码,可以忽略)
self.dec_Wemb = tf.get_variable('embedding',
initializer=tf.random_uniform([dec_vocab_size + 2, self.dec_emb_size]),
dtype=tf.float32)
2.使用gesim工具,将分词转换为向量。(我认为这个好,拓展性广很多)
for world in all_words_list:
# ["_GAO_", "_PAD_", "*",
if world == "_GAO_" or world == "_PAD_" or world == "*":
continue
try:
embedding.append(model[world].tolist())
except KeyError:
embedding.append([0.5] * vim)
3.seq2seq核心运作如下流程图
这里是基础模型(还有attention模型,schedule模型等)
模型的核心点都是在encoder处,编译整理输入状态,传递给decoder解析器,解析得到结果!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号