


数据库设计三范式
面向对象程序开发都是以类为基础的。实体类中的字段或属性,基本上都是与数据库表中的字段一一对应的,所以数据表设计的好坏直接关系到程序执行的效率。
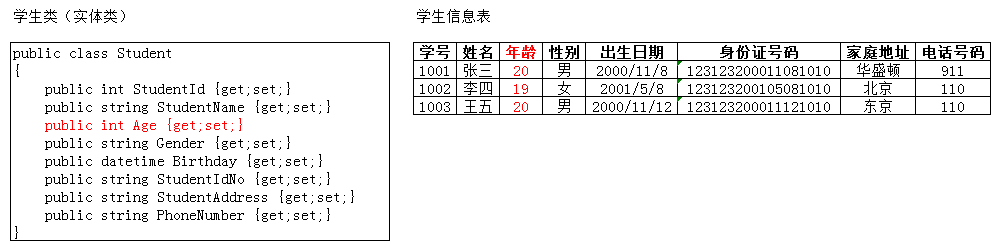
这里学生类中的Age属性是可以计算出来的,Age = Now.DateTime.Year - Convert.ToDateTime(objStu.Birthday).Year;所以实体类字段不必与数据表中的字段一一对应。如果仅仅想简化表设计,在设计学生信息表时不添加年龄这一字段,数据库也采用这种类似的方式计算Age,那么势必得不偿失。
那么数据表设计的三范式是什么呢?
1NF:必须满足原子性(字段是否还能在拆分),这是针对具体开发项目而言的。
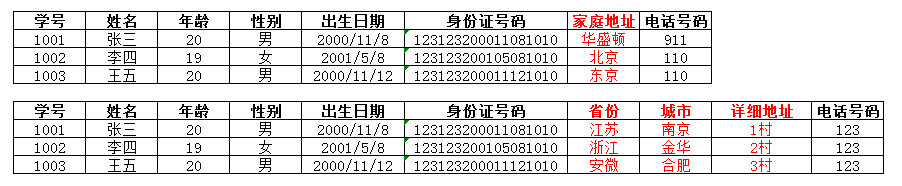
如下图:针对具体项目中,如家庭地址——是否有明确的省份、城市区分的要求,如果没有则可用一表,否则用二表
2NF:所有非主键字段完全依赖于主键。单纯从数据表设计的角度看,不是特别好理解。
网上看了许多解释,都是直观的划分的,如张三和小白的班级名称就重复了,发现这种现象,那么就必须把班级名称独立出去成为一张新的表。这种解释给人一种隔靴搔痒的感觉,等看完三范式,又忘了2NF是啥。
从面向对象的角度设计学生类(学号、姓名、年龄、性别、出生日期、身份证号、家庭地址、电话号码),这些都是学生唯一的、固有的属性。而班级名称这个信息是不依赖于、不依附学生的,它也会一直存在下去。程序中讲处处皆对象,它地位和学生类一样,是平等的,所以应该设计为班级类。那么对应数据库也应该设计一张班级表,而不能给学生表简单的增加一个班级名称这样的字段了。反过来再去回味2NF那句话:“所有非主键字段完全依赖于主键”,感觉确实在理。
从数据表设计的角度看,2NF也很有必要。想象一下,下图中班级名称:varchar(30)类型,每插入一个学生记录,占用的字节不大,但是如果数据有1亿条,可以算一下会吃掉多少内存。下表中班级名称重复出现,这种现象被称为数据冗余。

我们完全可以设计两张表:学生表、班级表,通过班级编号,将两张表关联在一起,减少数据冗余,节约内存资源。这里可不能纠结班级编号也重复,否则关系型数据表之间就没有联系了。我们可以减少非必要数据冗余,但不能清除所有的重复数据,这也是主外键关系表的内涵、特色。

3NF:所有非主属性字段对主键不存在传递依赖,即每个属性都跟主键有直接关系而不是间接关系。
2NF和3NF联系与区别:
相同点:通过表格拆分,减少数据冗余
不同点:3NF被拆分下来的第二张表,某两个字段之间一定描述了一种客观事实,它们一一对应。
比如下图学生表:姓名->所在专业->全国专业排名,其中所在专业、全国专业排名,二者短期并不会改变,是一种客观事实(假设全国高校各类专业每20年排名一次)。因此姓名、全国专业排名就间接关系在一起,这样的设计就违反了3NF。
再比如(学号,姓名,年龄,性别,所在院校)--(所在院校,院校地址,院校电话),所在院校->院校地址,两者也是一一映射,一种事实。姓名->所在院校->院校地址,姓名和院校地址也是间接联系的(别钻牛角说学校可能会迁址)。如果院校地址像股票一样随时变化,那就不存在间接关系了,这时就可以用2NF原则来拆分两表了。
上面两个例子确实能说明2NF和3NF的区别、联系,但是我也挺困惑的,是不是只要严格用2NF拆分数据表,3NF就是多此一举了?换句话说,3NF只是2NF的一种特殊情况吧,这样想想那么就不能想当然的依照1NF->2NF->3NF这种关系去设计数据表了。下表也可以用2NF拆分,只不过姓名->所在专业->全国专业排名这三者关系满足3NF关系。
总结:1NF、2NF、3NF不是层层递进关系,1NF->2NF是对的,但2NF包含3NF。

