
数据结构与算法 --- 组数、链表、栈和队列(二)
继数据结构与算法 --- 组数、链表、栈和队列(一)讲解完数组,链表及算法的优化策略之后,接下来继续讲解两种特殊的线性表结构,栈和队列。
栈
对“栈”有一个很形象的比喻,栈就像一摞叠在一起的盘子,放盘子时,只能放在上面,不能将盘子插入到中间的任意位置;取盘子时,只能从最上面取,不能从中间任意位置抽取。
定义
栈:栈是一种受限的线性表,它的原则是后进先出,后进先出,也称为 LIFO(Last In First Out)或 FILO(First In Last Out),它只允许再一端进行插入和删除操作,称之为“入栈”和“出栈”。
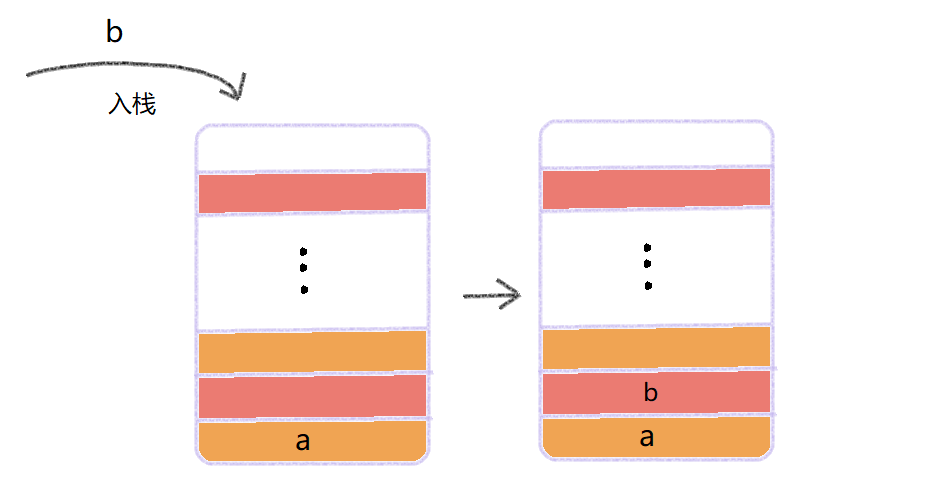
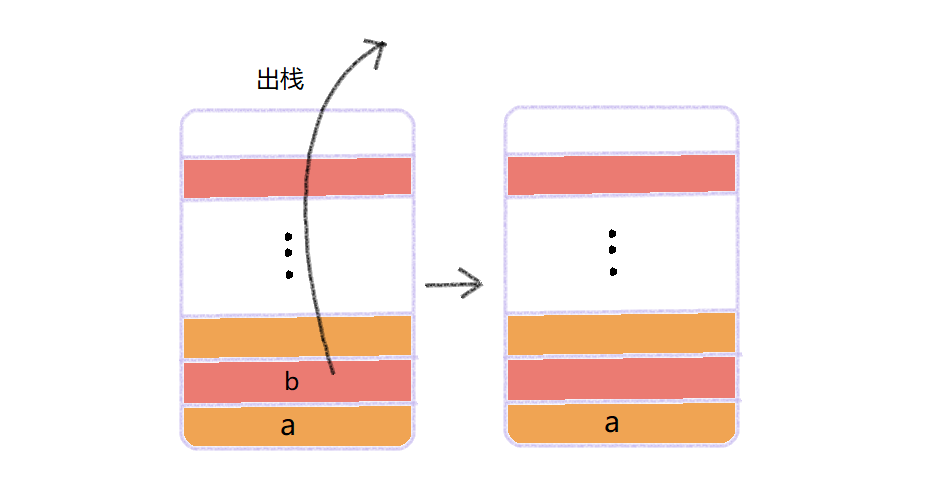
单从功能上讲,“入栈”和“出栈”的操作,数组或链表就可以实现,但是特定的数据结构就是特定场景的抽象,数组和链表的可操作性更好,但是也意味着更容易出错,所以当某个数据集只涉及到在一端插入和删除数据,并且满足先进后出、后进先出的特性的时候,就可以选择“栈”这种数据结构。
当然,都说到了数据和链表就可以实现“栈”的功能,那么用数组实现的栈称之为“顺序栈”,使用链表实现的栈称之为“链式栈”。
栈的时间、空间复杂度
因为栈只有“入栈”和“出栈”操作,无论顺序栈还是链式栈,“入栈”和“出栈”操作都是从结构的一端第一个位置进行操作,所以无论顺序栈还是链式栈,“入栈”和“出栈”操作的时间复杂度都为\(O(1)\)。
在“入栈”过程中,只需要申请一个元素的空间大小,而“出栈”过程中不产生额外空间,所以无论顺序栈还是链式栈,“入栈”和“出栈”操作的空间复杂度都为\(O(1)\)。
顺序栈的扩容
在链式栈中,大小是不受限的,但是顺序栈中,当初始化栈时,一定是事先指定栈大小,这样当栈满之后,就无法在做“入栈“操作,所以就需要考虑动态扩容。
当数组空间不够时,就需要重新申请一块更大的内存空间,将原数组的数据复制过去,这样就实现了一个支持动态扩容的数组。同理,如果要实现一个支持动态扩容的顺序栈,底层依然是依赖这样一个支持动态扩容的数组。
对于这样的支持动态扩容的顺序栈,它的”出栈“和”入栈“时间复杂度又会是多少?
对于出栈操作,不涉及到内存申请和数据移动,所以顺序栈的出栈的时间复杂度仍为\(O(1)\)。
对于入栈操作,分两种情况:
- 当栈中还有未占用空间时,入栈时间复杂度为\(O(1)\)。
- 当栈中没有未占用空间时,就需要重新申请内存和移动数据,这时其时间复杂度就变为了\(O(n)\)。
所以,入栈操作的最好时间复杂度\(O(1)\),最坏时间复杂度则为\(O(n)\),接下来使用摊还分析法计算平均复杂度:
给定条件:
- 当栈空间不够时,重新申请一个大小为原来两倍的数组。
- 为了简化分析,假设只有入栈操作,无出栈操作。
- 将不涉及内存申请和数据移动的操作定义为\(simple\_push\)操作,时间复杂度为\(O(1)\)。
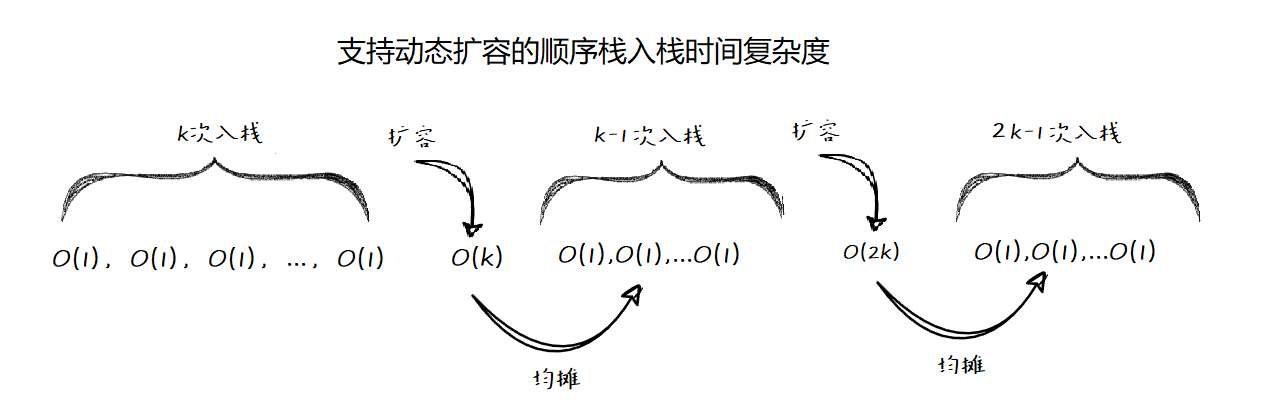
如果当前栈大小为\(k\),且已满,当再有新的数据要入栈时,再申请\(2k\)的内存空间,并做了\(k\)次的数据移动入栈操作,这部分操作的时间复杂度为\(O(k)\),接下来的\(k-1\)次新数据的入栈操作,都是\(simple\_push\)操作,时间复杂度为\(O(1)\),如下图所示:
队列
顾名思义,队列的队就是排队的队,可以将之想想成排队买票,先来的人先买,不允许插队,买完票了就从队首出去,后边新来的人就只能排在队尾。
定义
队列:队列也是一种受限制的线性表,它的原则是先进先出 FIFO(First In First Out),从队首取数据的操作称为“出队”,数据放入到队尾的操作称之为“入队”。
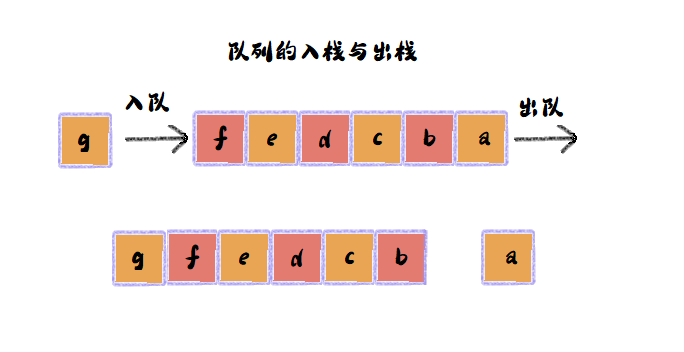
与栈相同,队列也可以基于数组或基于链表实现,所以对应的,队列也分为顺序队列和链式队列。
顺序队列及顺序队列的边界问题
对于栈,数据操作集中在栈顶,因此,只需要一个栈顶指针,但对于队列,数据入队操作发生在队尾,数据出队操作发生在队首,因此,需要两个指针:一个head指针,指向队首,一个tail指针,指向队尾。
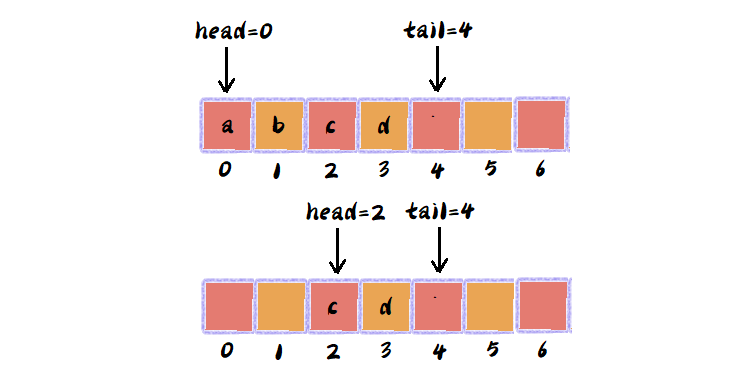
例:有一个顺序队列,当a、b、c、d依次入队后,队列中的head指针指向下标为0的位置,tail指针指向下标为4的位置,当a、b出队,队列中的head指针指向下标为2的位置,tail指针仍然指向下标为4的位置。如下如:
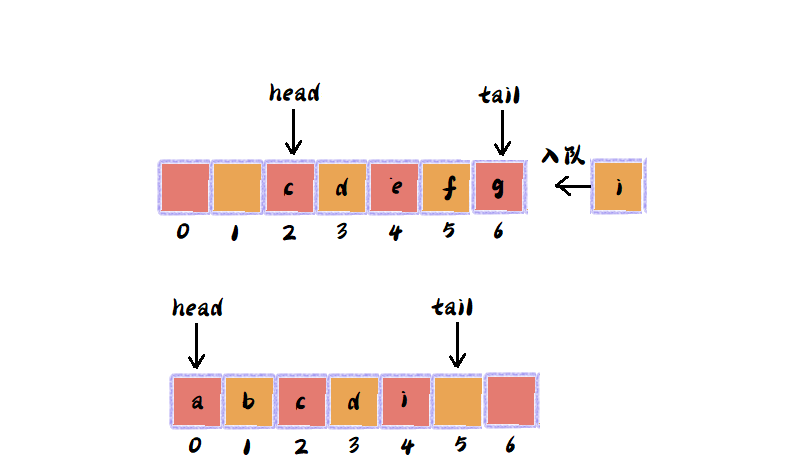
随着不断有数据入队,出队,head指针和tail指针会持续往后移动,当tail指针移动到数组边界时,就无法向队列中添加是数据了,这个问题怎么解决呢?
事实上,数据结构与算法 --- 组数、链表、栈和队列(一)讲述解决数组删除操作会导致数组数据不连续问题,与该问题异曲同工,我们可以在tail指针移动到数组边界时,如果有新的数据要入队,集中触发一次数据移动操作,将head指针到tail指针之间的数据全部移动到数组从0开始的问题,如下图:
链表队列
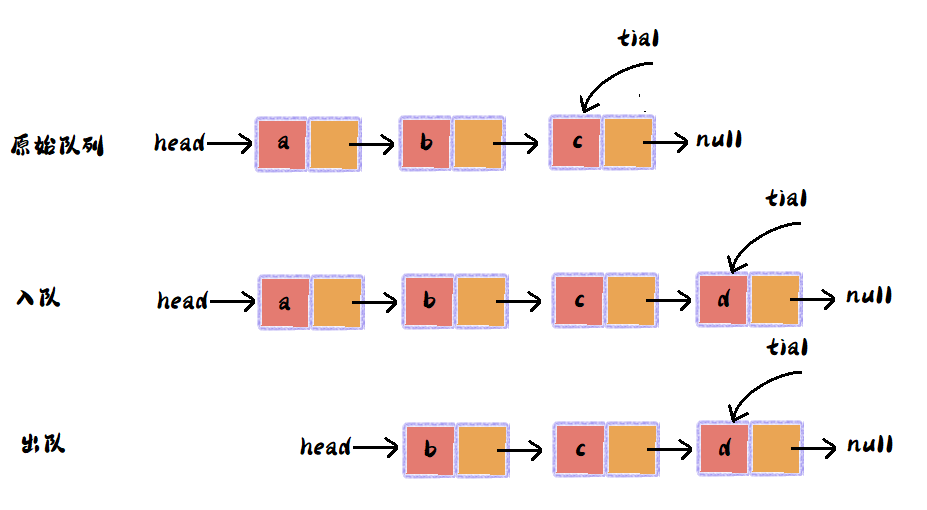
链表队列不存在顺序队列的边界问题,所以链表队列比较简单,如下图:
循环队列
上面的顺序列表中,当tail=n时,需要移动大量数据,就会导致入队操作的性能降低,那么就可以使用循环队列,来避免数据搬移,循环队列就是将首尾相连,形成一个环,如下图:
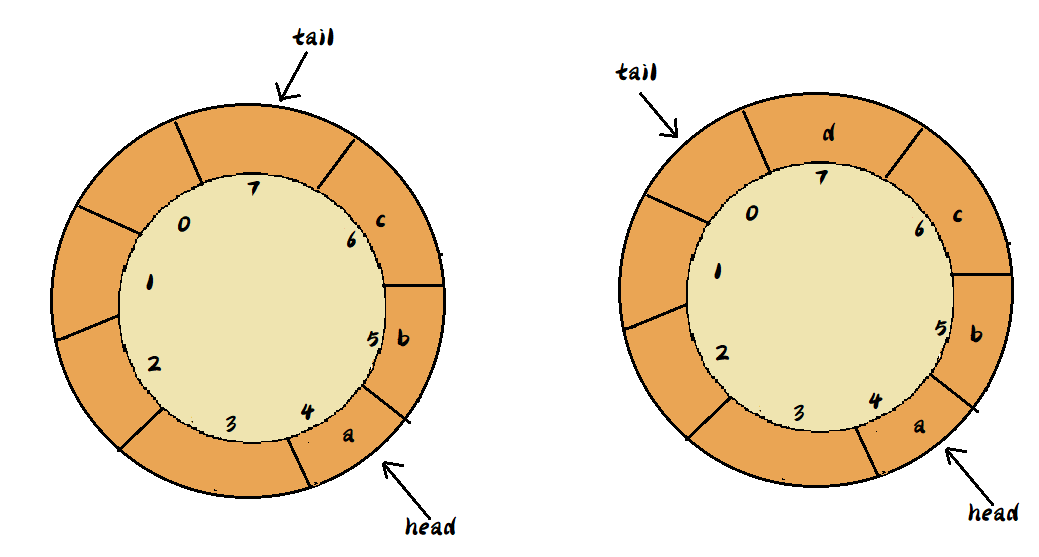
上图中,队列的大小为8,当前head=4,tail=7,当有一个新元素d入队时,放到下标为7的位置,但这个时候,并不把tail更新为8,而是将其在环中后移一位,指向下标为0的位置。
通过这样的方法,就成功避免了在tail=n时的数据移动操作,还需注意的一点时队列空和队列满的判断
- 当队列空时,head=tail。
- 当队列满时,则有(tail+1)% n=head,n为队列长度。例如上图中,队列长度为8,当head指针为4,则能看出,队列满时,tail指针为3,(3+1)% 8=4。
阻塞队列和并发队列
正常业务开发中使用更多的是一些具有某种特性的队列,如阻塞队列,并发队列。
阻塞队列其实就是在队列的基础上增加了阻塞特性,在队列为空的时候,从对首取数据会被阻塞,知道队列中有数据才会被返回;在队列已满时,插入数据的操作会被阻塞,知道队列有空闲位置后在插入数据,然后返回。
这种阻塞队列其实就是常见的“生产者-消费者模型”,这种基于阻塞队列实现的”生产者-消费者模型“可以有效的协调生产和消费的速度。甚至可以多配置多个”消费者“,来应对一个生产者。
在多线程情况下,多个线程同时操作队列,就会存在线程安全问题,如何实现一个线程安全的队列呢?
线程安全的队列又称作并发队列,最简单的实现方式就是在“入队”和“出队”时,进行加“锁”操作,但这会导致同一时刻仅允许一个存或取操作,“锁”的粒度太大会导致并发度太低,实际上,基于数组的循环队列,利用CAS原子操作,可以实现非常高效的无锁并发队列。
参考资料
[1] 数据结构与算法之美 / 王争 著. --北京:人民邮电出版社,2021.6
作者: Niuery Daily
出处: https://www.cnblogs.com/pandefu/>
邮箱: defu_pan@163.com
关于作者:.Net Framework,.Net Core ,WindowsForm,WPF ,控件库,多线程
本文版权归作者所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出 原文链接,否则保留追究法律责任的权利。 如有问题, 可邮件咨询。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号