
架构和项目面试题(new)
Spring Cloud架构
Spring Cloud 和 Dubbo 区别
注册中心
- 底层协议:springcloud基于http,dubbo基于tcp
- 注册中心:nacos/eureka,zookeeper(ap 半数节点可用才行)
- 模型定义:dubbo将一个接口定义一个服务,而springcloud应用定义一个服务
- springcloud是一个生态,dubbo只是SpringCloud只是服务调用一种解决方案
设计一个dubbo的rpc框架:
1.程序启动,读取配置文件(ip,端口),上传注册中心(nacos)
2.本地动态代理发起请求,(类似feign,rabbion负载均衡(hash,轮询,权重))
3.请求的传输网络,使用的网络框架netty,nio通讯
4.请求数据序列化格式,使用Protobuf,fastjson格式
5.接收方根据服务生成动态代理,监听端口,接收请求
spring cloud 的核心组件有哪些?
-
nacos:服务注册于发现
-
Feign:基于动态代理机制,根据注解和微服务,拼接请求 url 地址,发起请求。 将@FeignClient注解服务名 + GetMapping方法拼接起来,成一个api url
-
Ribbon:实现负载均衡,从一个服务的多台机器中选择一台。
1)负载均衡算法原理:为不同的服务,创建了不同的Spring上下文,都存在一个map<服务名称,Spring上下文中>
2)底层原理 @LoadBalanced ,RestTemplate
1)拦截器对 @LoadBalanced修饰的RestTemplate进行拦截
2)解析服务提供者ip地址列表,负载均衡之后
3)确定目标ip和port后,通过Httpclient进行http调用
-
sentinel:提供线程池,不同的服务走不同的线程池,实现了不同服务调用的隔离,避免了服务雪崩的问题。
- 实现限流原理:内部有个滑动时间窗口,每过一秒新增一个窗口,针对于配置了限流或熔断的接口,sentinel会每秒将这些接口调用信息(调用次数,异常次数),在内存中记录统计,然后进行计算,达到阈值就进行熔断或降级
-
springgateway:网关管理,由网关转发请求给对应的服务。id,路由,断言(判断是否满足),过滤器(pre 调用之前 身份认证 限流,post 调用之后 统计一些信息和指标日志)
feign调用过程(如何ok,httpclient调用不同)
feign第一次调用耗时很长问题哦?
原因是ribbon默认是懒加载,第一次调用才会生成相应的组件,如果想解决,改为启动就加载即可
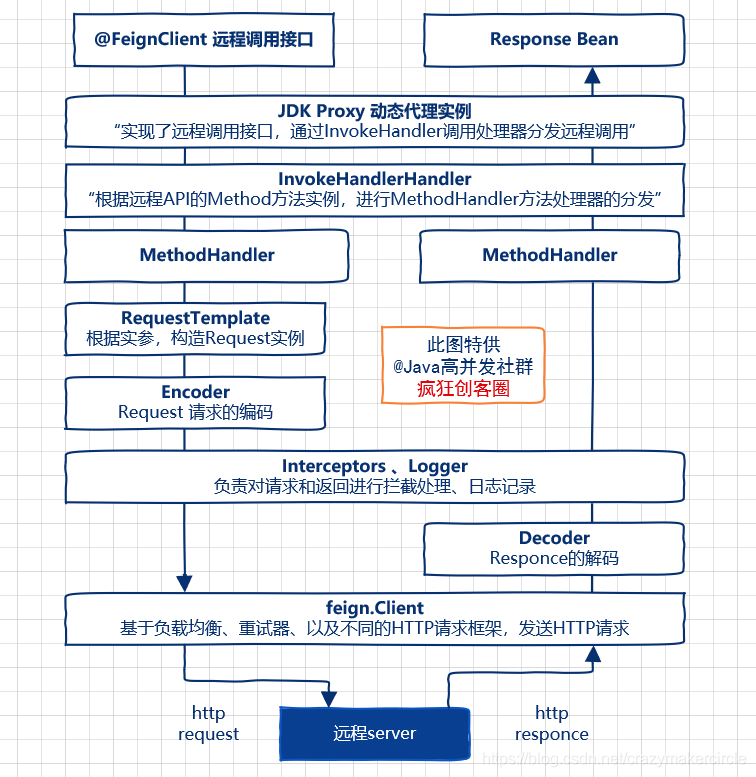
调用执行流程:@FeignClient注解的接口动态代理,feign.Client客户端(ok,LoadBalancer,HttpURLConnnection)成员执行远程调用
- 在微服务启动时,Feign会进行包扫描,对加@FeignClient注解的接口,创建JDK动态代理实例,执行注入到Spring IOC容器中。
- 启动调用时,根据参数构造Request 请求,将请求模板化
- 通过 feign.Client 客户端成员,完成远程 URL 请求执行和获取远程结果
生成动态代理类,核心步骤是定制一个调用处理器,就是实现InvocationHandler 的 invoke(…)
默认的调用处理器 FeignInvocationHandler,在处理远程方法调用的时候,会根据Java反射实例找到dispatch.MethodHandler方法,完成实际的HTTP请求和结果的处理。
public class ReflectiveFeign extends Feign {
//默认Feign调用的处理
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
//...
//首先,根据方法实例,从方法实例对象和方法处理器的映射中,
//取得 方法处理器,然后,调用 方法处理器 的 invoke(...) 方法
return dispatch.get(method).invoke(args);
}
//...
}
- Feign的远程接口的默认代理实现类调用处理器是FeignInvocationHandler,可以替换,如果Feign与Hystrix结合使用,则会替换成 HystrixInvocationHandler 调用处理器类
- 因为FeignInvocationHandler相关的远程调用执行流程,在运行机制以及调用性能上,在熔断和恢复,连接池结束满足不了生产环境的要求
Feign 客户端组件 feign.Client
其核心的逻辑:发送request请求到服务器,并接收response响应后进行解码。
feign.Client 类,是代表客户端的顶层接口,只有一个抽象方法,可以有多个实现类Default,ok等
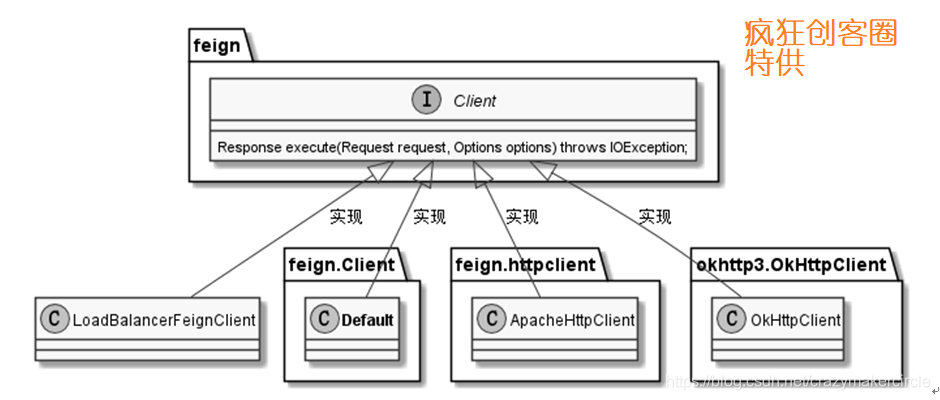
(1)Client.Default类:默认的feign.Client 客户端实现类,内部使用HttpURLConnnection 完成URL请求处理;
(2)ApacheHttpClient 类:内部使用 Apache httpclient 开源组件完成URL请求处理的feign.Client 客户端实现类;
(3)OkHttpClient类:内部使用 OkHttp3 开源组件完成URL请求处理的feign.Client 客户端实现类。
(4)LoadBalancerFeignClient 类:内部使用 Ribbion 负载均衡技术完成URL请求处理的feign.Client 客户端实现类。
feign性能优化:
底层默认是JDK的HttpURLConnection,它是单线程Http请求,不能配置线程池,我们可以使用Okhttp或者HttpClient来发送http请求,因为他们支持线程池
feign实现认证传递
- 继承RequestInterceptor 重写apply方法,然后添加用户信息即可


注册中心
Apache Zookeeper -> CP 保证,数据一致性
1.如果Zookeeper集群中的Leader 宕机,该集群就要进行 Leader 的选举,Zookeeper 集群中半数以上服务器节点不可用,将无法处理该请求。Zookeeper不能保证服务高可用性。
2.重新leader选举时间太长(30~120s),选举期间整个zk集群都是不可用的,这就导致在选举期间注册服务瘫痪,对于电商网站,消费者来说是不能被允许的(淘宝的双十一,京东的618就是紧遵AP的最好参照)。
Eureka -> AP
1.Eureka可以很好的应对因网络故障导致部分节点失去联系的情况,而不会像zookeeper那样使得整个注册服务瘫痪(尽管现在2.0发布了,但是由于其闭源的原因 ,但是目前 Ereka 1.x 任然是比较活跃的)。
Consul:=》CP
raft算法,Consul 的raft协议要求必须过半数的节点都写入成功才认为注册成功 ;在leader挂掉了之后,重新选举出leader之前会导致Consul 服务不可用。
Consul强一致性(C)带来的是:
- 服务注册相比Eureka会稍慢一些。因为Consul的raft协议要求必须过半数的节点都写入成功才认为注册成功
- Leader挂掉时,重新选举期间整个consul不可用。保证了强一致性但牺牲了可用性。
Eureka保证高可用(A)和最终一致性:
- 服务注册相对要快,因为不需要等注册信息replicate到其他节点,也不保证注册信息是否replicate成功
- 当数据出现不一致时,虽然A, B上的注册信息不完全相同,但每个Eureka节点依然能够正常对外提供服务,这会出现查询服务信息时如果请求A查不到,但请求B就能查到。如此保证了可用性但牺牲了一致性。
其他方面,eureka就是个servlet程序,跑在servlet容器中; Consul则是go编写而成。
Nacos:
Nacos是阿里开源的,Nacos 支持基于 DNS 和基于 RPC 的服务发现。Nacos只需要简单的配置就可以完成服务的注册发现,Nacos除了服务的注册发现之外,还支持动态配置服务。
CAP理论
- 一致性(C): 写操作之后,读操作无论哪个节点返回结果一样,多个节点(主从),返回结果都是一样的(强一致性)
- 可用性(A):某节点故障,非故障节点正常返回(返回结果肯定不一样)
- 分区容错性(P):网络分区后(存在网络延迟),系统能正常工作
总结:只有CP(由于网络分区无法保证100%,强一致,那么肯定要拒绝请求,其他节点没同步完之前,拒绝请求,即不可用,CA是互相矛盾),AP(不需要强一致,好理解)情况

Base理论
AP理论的扩展:高并发情况,也允许基本功能可用,不需要实时一致性,只需要最终一致性
- 基本可用(BA):允许损失部分可用性,比如在双11的时候,响应时间增加1~2秒;部分消费者某些功能页面不可用
- 软状态(S):允许系统中数据存在中间状态,即允许不同节点数据副本之间数据同步可以延时(不需要强一致)
- 最终一致性(E):不需要实时一致,但最终数据要保持一致性
nacos 1.x 原理:
1.生产端启动注册到nacos(使用http发送)
2.nacos查询服务提供方列表
3.消费端每10s定时拉取生产者信息(ip,接口等)
4.nacos的心跳机制(5s),检测服务状态,如果检测生产端服务宕机,推送更新消费端(基于UDP协议,集群数据同步任务使用Distro)
nacos配置文件优先级:yaml文件》application文件》自定义共享文件
1.心跳检测
Nacos 1.x 目前支持临时实例使用心跳上报方式维持活性,发送心跳的周期默认是 5 秒,Nacos 服务端会在 15 秒没收到心跳后将实例设置为不健康,在 30 秒没收到心跳时将这个临时实例摘除
2.探活机制
Nacos 2.x nacos服务端启动一个定时任务,每3s执行一次,查询是否有超过20s没有通信的连接,如果有,就会想客户端发送一个请求,进行探活,返回正常即服务正常,否则删除连接
nacos 流程:

扩展**
早期服务之间调用,无注册中心,针对集群通过nginx,配置二级域名,进行转发,需要配置ip等等,非常麻烦
注册与发现:服务启动注册到nacos,消费者启动监听注册中心,拿取服务注册表的信息并缓存到本地,直接通过这些ip:url访问生产者服务器
Euerka:使用一个concurrentHashMap<String,Map<String,Lease>>存储注册表信息,hashmap内存运算,性能高,对于一线互联网公司后端非常多机器实例(几千个实例),频繁上下线,同时concurrent支持线程安全
nacos自动感知,增加减少机器,(nacos-discovery)心跳任务,15s之内没交互,改为非健康,30s踢掉(注册或心跳都是调用对应nacos接口上传机器信息到nacos客户端)
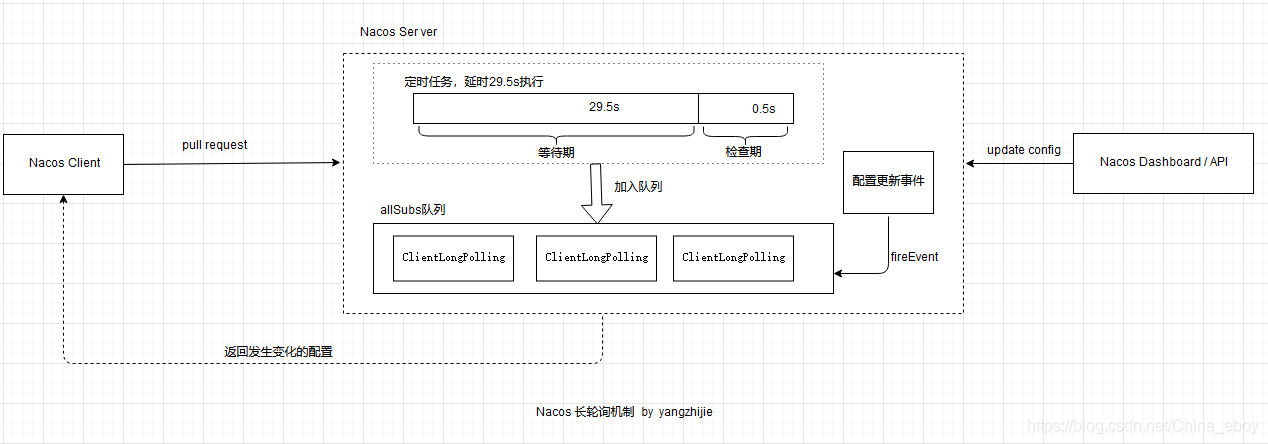
nacos实时刷新原理
nacos是采用了一种特殊的拉模式:
首先客户端发起请求,服务端检查没变更,就发起一个长轮询的任务(30s),将客户端连接放入allSubs队列中等待29.5s,
- 如果29.5s内检测到配置被修改,立马会触发一个事件机制,找到变更的配置项(通过dataId)并返回数据
- 如果29.5s内没检测到配置被修改,那么等待29.5s后触发自动检查,如果没有发生变更,则响应null给客户端
总结:这样既能实时响应更新,又避免了心跳长连接导致的性能问题
Sentinel 中使用的限流算法
- 计数器固定窗口算法:单位时间内计数阈值,比如单位1分钟内阈值100个请求,超过100个的限流
- 存在问题:在上个30s和下个30s都有99个请求,表面上满足1分钟不高过100个请求,实际单位1分钟有199个请求

- 存在问题:在上个30s和下个30s都有99个请求,表面上满足1分钟不高过100个请求,实际单位1分钟有199个请求
- 计数器滑动窗口算法:固定窗口算法的变种,将时间切换更小,比如1分钟分割成5份,时间滑动的,保证每次都满足单位1s,100个请求(每1秒创建一个新窗口)
- 存在问题:虽然比固定窗口优化很多,窗口拆分的越精细越准确(复杂度越高),但是还是没有完全解决固定窗口算法遇到的问题(只能降低问题概率,并不能完全解决)

- 存在问题:虽然比固定窗口优化很多,窗口拆分的越精细越准确(复杂度越高),但是还是没有完全解决固定窗口算法遇到的问题(只能降低问题概率,并不能完全解决)
- 漏斗算法:入口流量不限,漏斗容量固定,流出速率固定,超过桶大小拒绝请求
- 存在问题,因为漏斗流出速率固定,所以不支持突发流出流量

- 存在问题,因为漏斗流出速率固定,所以不支持突发流出流量
- 令牌桶算法:令牌可以放满整个桶(满了丢弃),每当一个请求消耗一个令牌,没有令牌了就无法通过
- 令牌桶限制的是平均流量,对突发流量不限制(有令牌就可以通过),不需要像漏斗算法一样,均匀速率流出

- 令牌桶限制的是平均流量,对突发流量不限制(有令牌就可以通过),不需要像漏斗算法一样,均匀速率流出
Sentinel 熔断过程

熔断和降级比较

服务降级,可以理解为,当预知大流量访问的时候,人工把某些服务设置为静态资源,避免影响一些重要的服务,人工降级,只是针对某些服务
Sleuth +Zinkin来做链路追踪解决方案
Sleuth 在服务跟踪框架为该请求创建唯一的跟踪标识traceId,通过一个traceId将不同服务的请求跟踪信息串联起到一个请求链中,进行链路的跟踪,当请求到达某个接口或服务生成一个spanId,通过计算开始 span 和 结束 span 的时间戳,就能统记出该 span 的时间延迟。


- 整个trace耗时4.154s,这个商品的span耗时4s,问题就在这个span
信息发送给服务端。 发送的方式主要有两种,一种是 HTTP 报文的方式,还有一种是消息总线的方式如 RabbitMQ(异步)。
Gateway中实现服务平滑迁移
网关+nacos+ribbion实现服务平滑迁移:版本更新中,为防止新服务有问题,并确保整体服务正常运作,首先需要将大量请求访问旧的服务,少量请求访问新服务,如果新的服务没问题,然后再慢慢将请求数量平移到服务,通过网关中weight配置即可,然后结合nacos实时刷新(配置放在nacos),实现平滑迁移(k8s的灰度发布也可以,亲和性设置权重)


旧服务:新服务=8:2 -> 0:10
高并发解决方案
背景:充电平台qps一万多,最高每天订单40万
解决方案
1.mq削峰(多个消费端),redis,mysql缓存热点数据,静态资源
2.分布式集群部署,nginx,rabbion负载均衡
3.数据库分库分表,读写分离,优化数据库表设计、索引、sql查询性能等
4.CDN技术,将静态资源分发到离用户较近的节点上,提高资源的访问速度和用户体验。
5.异步处理,短信,邮件发送之类
如何保证发布或节点宕机不影响在线使用?
-
想要的方案:k8s灰度发布,新版本升级完成,旧版本下线,请求自动转移到正常的实例
-
nacos自定义心跳周期时间,缩短的心跳周期(尽快移除不健康实例)
-
Ribbion和Spring Cloud的 请求重试机制解决此问题
spring: application: name: user-service-consumer cloud: nacos: discovery: server-addr: 127.0.0.1:8848 loadbalancer: retry: # 开启重试 enabled: true # 同一实例最大尝试次数,也就是第一次请求失败就转移到其他实例了 max-retries-on-same-service-instance: 1 # 其他实例最大尝试次数,请求其他实例时最大尝试次数。 max-retries-on-next-service-instance: 2 # 所有操作开启重试(慎重使用,特别是POST提交,幂等性保障) retry-on-all-operations: true
Nacos的保护阈值
在Nacos中针对注册的服务实例有一个保护阈值的配置项,0-1之间的浮点数。
保护阈值是⼀个⽐例值(当前服务健康实例数/当前服务总实例数)。
⼀般流程下,服务消费者要从Nacos获取可⽤实例有健康/不健康状态之分。Nacos在返回实例时,只会返回健康实例。
但在⾼并发、⼤流量场景会存在⼀定的问题。比如,服务A有100个实例,98个实例都处于不健康状态,如果Nacos只返回这两个健康实例的话。流量洪峰的到来可能会直接打垮这两个服务,进一步产生雪崩效应。
保护阈值存在的意义在于当服务A健康实例数/总实例数 < 保护阈值时,说明健康的实例不多了,保护阈值会被触发(状态true)。
Nacos会把该服务所有的实例信息(健康的+不健康的)全部提供给消费者,消费者可能访问到不健康的实例,请求失败,但这样也⽐造成雪崩要好。牺牲了⼀些请求,保证了整个系统的可⽤。
项目中难解决的问题,怎么解决的
-
1.jvm调优:watch在线调优加反编译,再加热部署解决问题
-
2.项目维度设计:单表设计 + 水平分表 + 垂直分表 + 继承和泛型(共用实体类,dao等类简化不同表逻辑) ** 解决大数据量问题,java微服务(实现服务的基础技术)+数仓(hadoop+hive) (架构抽象),拆分不同维度很多表(分治),利用java业务和数仓维度设计+继承和泛型切换不同维度表访问,离线和内存计算(分层),不固定时间维度通过日报表统计,固定维度通过对应维度表计算,也可以再增加维度表,兼容可能的所有业务场景(兼容演化),sentinel熔断机制,分布式集群部署,rabbion负载均衡,重试机制,k8s动态扩缩容,监控,上下线节点pod(容错),灰度发布**
-
3.微服务组件扩展应用:
项目启动就加载的属性nacos无法动态刷新,在注入拦截器中,公钥字段在启动阶段就已经加载好,改变nacos+@RefreshScope也无法动态刷新属性
我设置一段时间之后公私钥在nacos动态配置页面手动改变,此时新加密的token是新的公钥才能解密的,在不重启的前提下,需要动态获取nacos上新的公钥,此时需要新加了一个nacos动态监听器,替换服务中公钥,否则解密失败(还是原来的公钥) -
4.aop全局日志切面:
需要对项目中所有新增和修改操作新增日志,给mybatis-plus引入通用crud框架,service和impl继承crud类,在通用框架新增和修改上加切面实现全局日志记录
-
5.mq+redis实现高效解耦消费:
在线拉取电商平台api订单之后,后面新加了一个需求汇总所有的平台订单数据,提供公共api供其他平台调用,由于涉及电商平台非常多,数据量大,又需要考虑实时性,这里巧妙利用mq监听加redis的存放数据,mq的msg是redis的key,在消费端通过msg从redis拿取数据出来,实现redis高效缓存和mq进行异步解耦
-
6.ThreadLocal + 单例:实现单例全局调用和安全
项目亮点
认证,表设计(单表,主键,索引,拆分表),分维度业务设计+继承和泛型,离线和内存计算,设计模式,redis,jvm在线调优,mq+redis,递归区域结构,通用crud架子搭建
1.mybatis-plus + java8流式编程,简洁规范
mybatis-plus:主推单表操作,减少关联sql和嵌套sql导致慢sql,主键引用聚合索引(主键id bigint,充分发挥b+ 范围查找 和 降低索引键大小,降低树高度,减少磁盘io),联合索引(最左原则,相当于多个索引),覆盖索引(查询字段被索引覆盖,避免回表)
针对大数据量表,设计考虑水平拆分,
2.订单表水平拆表,数仓dwd层进行降维合并统计和垂直拆分大字段(1.mycat,2.业务设计查询时按照规定时间进行,3.借助redis存储每个表中首个id和最后一个id(bigint类型递增的)和对应拆分表,经过redis定位表之后再查db,也可以大大降低关联sql带来的问题),
看板用户表垂直分表:用户画像最后只需要将充电次数大于1的用户id和号码导出来
3.数仓+内存+缓存:相对于原充电平台项目,大量内存和离线计算,避免在业务库编写嵌套和关联sql
4.jwt + rsa双对称加密 + md5动态加密,保证用户信息安全,解决单点登录问题,不依赖redis
5.设计模式
单例模式(下一题)或者线程池
AOP切面(通用增删改查架子搭建加切面),实现所有新增和修改方法记录日志 (动态代理),
策略模式+工厂模式(map):解决多个ifelse问题,依据传平台id实现切换调用不同电商平台api业务
https://blog.csdn.net/qq382495414/article/details/116303205
策略模式:用户登录,依据unionid判断来源,走web登录流程,或者app登录流程等
https://www.runoob.com/design-pattern/strategy-pattern.html
装饰者模式:依据请求动态切换不同的数据源 pg,mysql(不过默认使用mysql,如果需要切换直接修改参数即可)
装饰者模式让我们可以有不同的被装饰者,例如FileInputStream包装成缓冲
new BufferedInputStream(new FileInputStream(new File("path")));
也可以对上面代码再进行加工,简单的加密处理 :
new Base64InputStream(new BufferedInputStream(new FileInputStream(new File(""))),0)
原型模式:
**浅克隆,clone方法,克隆对象**
**深克隆,克隆出新的对象,后续值不会跟着改变**,实现 Serializable 接口(fastjson序列号),通过对象的序列化和反序列化实现克隆,可以实现真正的深度克隆(持久化数据和网络传输)
6.ThreadLocal:拦截器解密token获取用户信息使用ThreadLocal,全局拿用户信息,实现单例模式同时保证线程安全情况
7.redis的hash数据结构大量替代string数据结构,减少key使用,进行redis内存优化
8.redis 集群:多主多从,去中心,动态扩容,节点通信选举,故障检测和转移,不依赖sentinel
9.引入了arthas 在线调优工具 + 代码规范
arthas:定位死锁,监控fullgc频率,反编译,热部署,请求追踪trace,watch 监听请求方法的参数和返回结果集,打印出dump进行内存分析
代码规范:不能使用全局hashmap,要使用就使用WeakHashMap(软引用)
嵌套或递归方法不允许太深,防止栈溢出,尽量不使用全局变量,使用局部变量
10.CrudService 通用增删改查架子搭建 + mybatis-plus + swagger+lombok 代码生成工具一键生成
11.针对全国区域这样数据结构,写递归算法,并且将结果封装成树形结果一次性给前端
前端时间维度查询对应表,大大降低代码量
架构师思维
逻辑思维和抽象思维能力是一个架构师最重要的素质
-
1.平衡取舍
一个架构本质上总会有优有劣,它不可能是完美的、普适的,也不存在一个架构在 A 场景能用,在 B 场景也最适用的情况,所以就需要我们准确判断,作出取舍。 我们可以根据具体的业务需求来调整架构,也就是以当前的业务需求,选出最匹配的架构。另外,架构师还需要根据现状衡量好需求和资源、效率和安全、时延和吞吐等等之间的关系,做出判断。 比如对于在线交易系统,可能更重要的是保证它的低时延,因此就可以牺牲一定的吞吐量,而对于离线系统,吞吐量则更重要一些。 选择消息队列,选择rabbit mq 还是kafka2.抽象思维

上图右边的积木城堡就是抽象,它其实还是由若干个子模块组成,这些模块是子抽象单元,左边的各种形状的积木是细节。 架构师先要在大脑中形成抽象概念,然后是子模块分解,然后是依次实现子模块,最后将子模块拼装组合起来,形成最后系统。 数据中台微服务就是一个抽象,分为授权中心,网关,战报模块,客群模块,看板模块各个抽象子模块,通过springboot,java基础,mysql,redis等等具体细节实现子模块springboot,然后子模块组合起来,形成一个微服务数据中台 上述流程中的抽象是在同一个层次上的,比较清晰易于理解,但是没有经验的程序员在实现这个流程的时候,代码层次会跳,比方说主流程到支付卡校验一块,他的代码会突然跳出一行某银行API远程调用,这个就是抽象跳跃,银行API调用是细节,应该封装在PaycardVerification这个抽象里头。 -
分层思维
为了构建一套复杂系统,我们把整个系统划分成若干个层次,每一层专注解决某个领域的问题,并向上提供服务。有些层次是纵向的,它贯穿所有其它层次,称为共享层。分层也可以认为是抽象的一种方式,将系统抽象分解成若干层次化的模块。 spring->springboot->springcloud 微服务分层:授权中心,网关,战报模块,客群模块,看板模块,每个模块代表一层,各自负责自己的任务 数仓分层:ods,dwd,dws,ads,各自负责自己的任务 有些层次是纵向的(aop切面),它贯穿所有其它层次,称为共享层。分层也可以认为是抽象的一种方式,将系统抽象分解成若干层次化的模块。 -
分治思维
对于一个无法一次解决的大问题,我们会先把大问题分解成若干个子问题,如果子问题还无法直接解决,则继续分解成子子问题,直到可以直接解决的程度,这个是分解(divide)的过程;然后将子子问题的解组合拼装成子问题的解,再将子问题的解组合拼装成原问题的解,这个是组合(combine)的过程。 递归也是特殊的一种分治技术,将一个大问题按照递归的方式简单化成很多个维度的子问题(全国区域,树结构) 一个打的需求,划分成多个小的模块,接口,表等等,所有子需求完成,即可 -
容错机制
相比程序员,架构师面对的环境要恶劣的多,因为系统更复杂了,出错的概率也增加了,每个节点、每个功能都有可能出错,所以这就需要架构师为错误而设计(Design For Failure),事先提前做好解决方案。 除了应用出错,还有可能产生数据丢失的情况,这个可以通过备份来预防。 另外,如果出现故障,该怎样做到快速恢复呢?我们现在普遍的做法是不修只换,因为如果要修复一个异常状态,可能修复后还会出现连带问题,而如果能通过技术手段,删除已出现的故障,换一个全新的系统,就能够保证它迅速恢复到正常状态。 熔断器,集群部署,分布式开发,应用降级保证核心业务,上线版本回滚(通过版本号实现上线前后端升级应用),redis宕机rdb恢复数据等等 -
演化
在互联网软件系统的整个生命周期过程中,前期的设计和开发大致只占三分,在后面的七分时间里,架构师需要根据用户的反馈对架构进行不断的调整。我认为架构师除了要利用自身的架构设计能力,同时也要学会借助用户反馈和进化的力量,推动架构的持续演进,这个就是演化式架构思维。 当然一开始的架构设计非常重要,架构定系统基本就成型了,不容马虎。同时,优秀的架构师深知,能够不断应对环境变化的系统,才是有生命力的系统,架构的好坏,很大部分取决于它应对变化的灵活性。所以具有演化式思维的架构师,能够在一开始设计时就考虑到后续架构的演化特性,并且将灵活应对变化的能力作为架构设计的主要考量。 单体架构-》分布式架构-》微服务架构 的演变的过程 架构设计的同时,也需要考虑后期因需求的变化而进行演变和完善 比如:微服务考虑到需求的演变和兼容,微服务分很多子服务,每个服务各种可以采用不同的技术中间件,不同的数据库,甚至不同的语言等,互不影响,均可以兼容 -
总结
1.架构的本质是管理复杂性,抽象、分层、分治和演化思维是架构师征服复杂性的四种根本性武器。 2.掌握了抽象、分层、分治和演化这四种基本的武器,你可以设计小到一个类,一个模块,一个子系统,或者一个中型的系统,也可以大到一个公司的基础平台架构,微服务架构,技术体系架构,甚至是组织架构,业务架构等等。 3.架构设计不是静态的,而是动态演化的。只有能够不断应对环境变化的系统,才是有生命力的系统。
微服务设计原则
- 单一职责,网关(暴露,拦截层),产业链模型(计算层),产业链前台(展示层)
- 与其他服务解耦,互不影响(部署,测试等)
- 通信简单、通用,跨语言,resultful风格,消息队列
- 业务隔离划分,企业模块,围串标模块等
架构师掌握技能
java架构方向,大数据只是扩展技能
cicd Jenkins + git +k8s

-
项目代码通过git推送到gitlab;
-
流水线(Jenkins钩子)从gitlab上面拉取代码下来,在编译、生成镜像,推送到Harbor仓库;
-
容器部署,通过k8s拉取Harbor上的容器启动服务,然后配置网关路由发布;
ddd 领域模型
DDD的全称为Domain-driven Design,即领域驱动设计;
分层架构:UI层、应用层service、领域层(entity,imp业务层)、基础设施层dao等crud操作;
User Interface
负责向用户展现信息,并且会解析用户行为,即常说的展现层。
Application Layer
应用层没有任何的业务逻辑代码,它很简单,它主要为程序提供任务处理。
Domain Layer
这一层包含有关领域的信息,是业务的核心,领域模型的状态都直接或间接(持久化至数据库)存储在这一层。
Infrastructure Layer
为其他层提供底层依赖操作。
**1.失血模型 **
实体类Item,ItemDao,ItemDaoHibernateImpl(基础crud),业务逻辑类service 业务逻辑写在service 替代写在Impl里面
2.贫血模型
实体类只有针对属性的get,set操作,行为被搬到业务类了.这种风格是贫血模型的代表Item,ItemDao,ItemDaoHibernateImpl,ItemManager
3.充血模型
Item:包含了实体类信息,也包含了所有的业务逻辑
ItemDao:持久化DAO接口类
ItemDaoHibernateImpl:DAO接口的实现类
4.胀血模型
Item:包含了实体类信息,也包含了所有的业务逻辑
ItemDao:持久化DAO接口类
敏捷开发
- 1.主张最简单的解决方案就是最好的解决方案。不要过分构建(overbuild)你的软件
- 2.拥抱变化
- 3.允许试错,快速将初步版本给客户看,迅速调整,快速迭代,不断试错,从而找到最合适的功能
- 4.快速迭代
- 5.让测试人员和开发者参与需求讨论
- 6.编写可测试的需求文档
- 7.多沟通,尽量减少文档
- 8.做好产品原型
- 9.及早考虑测试


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人