
java 高级
32.HashMap
32.1 几种形式和比较 keyset,values,entrySet,iterator
1.keyset

2.values

3.entrySet

4.iterator

- keyset性能最差(查询map两遍),其他相差不多(依据业务和数据量时间进行测试)
- values只能获取values
32.2 HashMap原理

- map默认长度为16
- 执行顺序按照取余key进行排序



- 底层优化长度为2^n
- 从0到15,占满了75%即超过默认负载因子,会扩容,每次扩容会产生一个重新排列,这样会导致性能不好(120从8位置变成24的位置...)
- 0.75是经过java开源团队各种计算得出的最优数字,自己设置数字要注意,如果设置为1表示全部占满才扩容,节点碰撞会更多(8位置)。这种碰撞应该尽量避免,否则一个索引存在大量数据,再次碰撞时 大量调用equals方法会很影响效率


- 得出的结果为0,1,4,5,不可能为2,3
- 扩容长度为2的n次幂有点:
- 1.充分利用空间,避免浪费;
- 2.扩容数据迁移时不需要重新hash,在原来位置或原来位置+扩容长度
32.3 ConcurrentHashMap原理:
jdk 1.7 -> jdk 1.8

总结:CAS
-
JDK1.7 ConcurrentHashMap 采用了分段锁技术,其中 Segment 继承于 ReentrantLock。不会像 HashTable 那样不管是 put 还是 get 操作都需要做同步处理,理论上 ConcurrentHashMap 支持 CurrencyLevel (Segment 数组数量)的线程并发。每当一个线程占用锁访问一个 Segment 时,不会影响到其他的 Segment。
-
JDK1.8的实现已经抛弃了Segment分段锁机制,利用CAS+Synchronized(替换ReentrantLock )来保证并发更新的安全。
-
数据结构采用:数组+链表+红黑树,采用红黑树之后可以保证查询效率(
O(logn))。 -
总长度大于64(扩容两次),某个链表碰撞大于8(深度),就会从jdk1.7 数组+链表=》jdk1.8 数组+链表+红黑树
-
速度更快:底层数据结构hashmap/hashset,hash算法,0.75*长度,扩容
-
ConcurrentHashMap,jdk1.7 concurrentLevel=16,段太大可能导致浪费,太小可能每个段使用过多效率低,jdk1.8采用链表+红黑树 ,并且CAS算法,效率大大提高
-
jdk1.8拿掉永久区,取代为MetaSpace 元空间,使用物理内存,空间大大增大,oom发送概率大大降低,同时垃圾回收也大大降低,效率提高
-
jdk 1.7 hashmap插入数据是插入链表的头部(头插法),rehash之后链表逆序了(另一个多线程又还是按照顺序执行),在多线程map扩容情况下有可能出现死循环情况,而jdk 1.8则插入尾部,避免了死循环情况


32.4 树
二叉树

- 二叉树实际是链表+二分查找算法,左边都比右边小
- 时间复杂度,每次父节点下方有两个子节点,2^x=n(树深度 3)计算变成logn
红黑树

33.netty
简介

BIO vs NIO vs AIO

- BIO

客户端一个连接,一个线程,同步阻塞等待 - NIO

理论基础:客户端与服务端建立连接之后,并不是时刻处于活动状态active,非活动状态就不需要占用资源,处理更多的并发(轮询)



- buffer缓冲区实现非阻塞功能
- selector选择器监控通道,发现有事件就会去读取数据
NIO 三大核心原理示意图

- Buffer类

- Channel


- Selector


Netty 线程模型
1.传统阻塞IO模型
- 一个客户端对应一个独立线程完成任务(读,处理,返回),并且保证长连接,高并发情况,创建大量线程,占用大量资源
2.Reactor单线程模型
- 基于线程池复用线程资源非阻塞操作,一个Reactor单线程监听多个客户端连接,不必为每个连接创建线程(只需一个handler等待)-》将任务分发给后续程序处理即可
3.基于主从reactor多线程模型改进
- 多个客户端对应一个reactor主线程(selector监听,acceptor创建连接),负责建立连接
- 一个reactor主线程分发任务给多个reactor子线程,
- reactor子线程加入连接队列监听,并创建handler事件处理
- handler读取数据分发给worker线程进行业务处理,获得结果返回handler -》客户端
4.netty模型
-
在主从reactor基础上,从一个reactor主线程变成多个reactor主线程
-
传统阻塞I/O
一个阻塞对象,一个线程,监听一个客户端连接

-
Reactor
一个阻塞对象,监听多个客户端连接,交由对应线程处理


**单线程 **
- 1.一个Reactor单线程对应多个客户端连接
- 2.将来连接Accept和业务处理Hanfder分离


多线程

主从多线程
- 1.一个Reactor单线程对应多个客户端连接
- 2.将来连接Accept和Hanfder分离
- Reactor主线程有多个Handler,并且Handler只响应事件,分发给worker线程池处理业务
- worker线程池处理完之后,回传到Hander,然后send回client
- 5.将handler从主线程中分离到子线程(可以有多个)中


相对单Reactor 多线程,主线程只做连接,将hander等处理交由子线程进行处理

Protocol Buffers
Netty 自带解码器:StringDecoder 字符串解码,ObjectDecoder 对象解码器



netty模仿Dubbo实现RPC


37.负载均衡(非重点)
37.1 nginx服务端负载均衡:传统负载均衡,手动配置ip,通过nginx轮询ip进行负载均衡,但是添加新的服务机需要手动新增ip配置,不太理想

nginx 部署应用,反向代理(一个域名配多个ip),负载均衡,限流,分发算法
37.2 分发算法有:
- 轮询(默认)
- weight(权重) 1:2
- ip_hash,请求者ip的hash值,实现同一ip在固定的机器上,解决session问题
- url_hash(第三方),根据请求的url的hash值将请求分到不同的机器中,缓存高
- fair(第三方),响应时间短的分发的请求多
轮询和权重适合静态页面,不适合动态页面 ip_hash 适合动态页面
37.3 基于请求头分发
- 1.基于host分发 多集群,多个反向代理,多个upstream
- 基于开发语言分发
- 基于浏览器分发
- 基于源ip分发
注册中心客户端负载均衡:自动监听服务器和自动推送信息

Nginx转发不同服务器实现负载均衡,网关集群部署需要有nginx反向代理转发
cdn(content delivery network) 内容分发网络:静态文件,图片,视频,js代码...
cdn,选择离你最近网络cdn获取缓存资源,除了第一个用户需要从总部拿取资源缓存到最近cdn节点(时间比较慢),以后的用户获取资源都是用缓存获取,自己推送到cdn,用户第一次也很快,但是会有冗余,有些用户并不需要的资源
数据库设计:
1.关系型数据库:
字段,分表,分库,索引,关联等等
集群:主从分离,增加子节点,增加读的性能,但从主节点同步到从节点有一定的延时性,如果某些功能 不允许出现延时,那么就指定从主节点读取,或者从缓存中读取
提升写的性能:垂直分表(分片,大的字段分离),每个表都有主从集群节点,水平分表(分片)
2.NoSQL 非关系型数据库:键值对方式mogongdb,redis
37.4.算法思想

随机


- 随机算法,Random随机获取ip
- 权重随机,权重值为8,那么重复保存8条此ip值,随机几率就提高8倍(如果权重值很大,那么集合就越大,循环性能就越差)
- 范围算法,依据机器权重划区域,如果随机值小于5则选择A机器,6-8选择B机器

37.5轮询
同理随机算法,比较得出性能高效的方法:



-
linux每次请求都会有一个requestId,自增的,有可能非常大,此处模拟requestId,使用hash取余让它的值落在范围区间之内
如果出现AAAAABC,这样对A服务器性能是不好的,理想情况是AABAACA -
平滑加权轮询算法:
动态权重:currentweight

-
AABACAA 获得的结果
37.6.哈希
共享session问题,集群情况下用户如果第二次访问,nginx转发到第三台服务机,由于没session,需要强制登录




- 一个客户端ip将转化成hashcode存到指定服务器,同一个客户肯定只会访问某一台机![]
- 需要利用一个排序的存储,treeMap 红黑树
(https://img2020.cnblogs.com/blog/1999208/202105/1999208-20210527101614105-1147448490.png) - 哈希环 + 红黑树 实现 哈希负载均衡算法
- 如果hash值大于最大值,那么返回最小值,环形结构
负载均衡算法或者hash环等等,都是将具体节点转换成范围节点
38.Dubbo
http,socket,tcp都属于rpc协议


模拟http协议源码调用
还有dubbo协议等
39.zookeeper
分布式协调器,分布式系统,存储数据,注册中心,管理数据在内存中
文件系统的数据结构:
数据结构:树形节点存储;
持久化节点;
临时节点,session超时时间,临时节点和sessionid绑定,如果挂掉或关闭,ping不通,或超时,会删除临时节点
持久化顺序节点;
临时顺序节点;
命令:
create (-e) /zp 创建一个节点(默认持久化节点,-e 临时节点)
create -s /zp/xx- :创建持久化顺序节点
get -s /zp
set /zp "aa"
create /zp/sub 持久化创建子节点,临时节点不能拥有子节点
get -w /zp : 数据修改,进行监听(仅一次),配置中心修改config,统一监听动态刷新配置文件(类似:nacos)
ls -w /zp :对某个目录进行监听
客户端监听机制:对子节点进行监听,节点数据修改,自动监听到事件
注册中心:服务端新加服务器会在注册中心创建节点并同步信息,客户端对服务目录进行监听,会动态感知,加入到本地缓存,实现客户端负载均衡


多个线程竞争获取锁(创建节点,一个节点唯一性),如果成功完成业务处理,并释放锁(删除节点),如果失败,监听等待释放锁,监听到释放锁,然后又一起竞争锁
问题:羊群效率?
1000个请求,只有一个成功,其他请求都需要监听等待,时间复杂度高
第一次 1个成功 999监听,第二次 1个成功 998监听 ...
解决方案:使用临时顺序节点
每次每个节点只监听它上一个节点的就可以了(/lock 容器节点),第一个节点index=0直接获得锁

问题:中间节点断了怎么办?
中间节点销毁,改监听此节点前一个节点
Nginx 反向代理:
# 向80端口发送请求,自动反向代理到http://myapp服务器,此时baidu1,baidu2,baidu3都可能收到请求(轮询)
http{
upstream myapp {
server www.baidu1.com
server www.baidu2.com
server www.baidu3.com
}
server{
listen:80:
locaiton / {
proxy_pass http://myapp
}
}
}

利用curator实现分布式锁,将扣减库存并发请求串行化
RabbitMQ

MQ防重复消费
幂等性(同样的请求来很多次,确保对应的数据是不会改变的,只消费一次,如何避免消息的重复消费)
解决方案:
- 基于数据库的唯一键来保证重复数据不会重复插入多条,消费一次插入表中,唯一性保证无法再次插入(唯一ID + 指纹码机制)
- 乐观锁,每次插入或更新判断版本是否符合预期,符合才操作
- redis保持数据,消费的时候判断是否存在,如果存在就重复消费
MQ防消息丢失
生产者 -》MQ服务器-》消费者
- 生产者:异步confirm模式,mq服务器成功接收到消息返回ack=true,否则ack=false(事务消息,性能不佳)
- MQ队列:设置消息(队列、Exchange)持久化,防止宕机导致丢失(极端情况,持久化还没完成宕机,只有持久化到磁盘才通知生产方ack)
- 消费者:一般设置手工确认ack机制,确保消费成功才ok

- 生产者重发消息,如果未接收到MQ的confirm会将消息保存到消息DB中,用分布式定时任务不断重发消息
- MQ重发机制,MQ未收到消费者的ack确认,会重发给消费端,为预防阻塞,如果超过3次,就日志记录下来手动处理
RabbitMQ三种机制来保证消息的成功投递(confirm)(mq返回生产者投递成功消息),成功消费(ack)(消费者手工ack返回mq消费成功消息),和消息丢失(return)(生产者投递失败情况,死信队列保证消息不丢失)的处理
1、RabbitMQ的ACK机制
ACK机制是rabbitmq保证消息成功消费的机制,默认应该是自动签收的,也就是消息被队列取出即视为已消费,但是往往业务流程里面会存在必须等业务处理完成才能是已签收,或者处理业务的过程中发生了异常,不能签收,所以ACK机制可以保证这个问题。
1、首先要将签收设置为非自动签收
2、然后消费者消费消息,业务处理完成后,手动回应服务端,已签收
重点在这里
// 成功签收
channel.basicAck(envelope.getDeliveryTag(), false);
// 未成功签收,第三个参数标识:是否重回队列,设置为true,则会重回到队列,如果设置为false则需要自己处理,写日志或其他方式
channel.basicNack(envelope.getDeliveryTag(), false, true);
public static void main(String args[]) throws Exception {
// 1、获取连接工厂
ConnectionFactory connectionFactory = RabbitmqConnectionFactory.getConnectionFactory();
// 2、创建连接
Connection connection = connectionFactory.newConnection();
// 3、创建通道
Channel channel = connection.createChannel();
// 4、创建队列、交换机,并绑定
channel.exchangeDeclare(EXCHANG_NAME, BuiltinExchangeType.TOPIC, true);
channel.queueDeclare(QUEUE, true, false, false, null);
channel.queueBind(QUEUE, EXCHANG_NAME ,ROUTING_KEY);
// 5、创建消费者
MyConsumer consumer = new MyConsumer(channel);
channel.basicConsume(QUEUE, false, consumer);
//autoAck 是否自动确认消息,true自动确认,false 不自动要手动调用,建立设置为false
//channel.basicAck(envelope.getDeliveryTag(), false);
// 第三参数:是否重回队列,设置为true,则会重回到队列
//channel.basicNack(envelope.getDeliveryTag(), false, true);
}
2、RabbitMQ的Confirm机制
confirm机制机制是保证消息成功投递到了服务端,通过回调通知生产者是否收到了消息,重点在生产者这里,要设置消息确认,然后监听回调。
public static void main(String args[]) throws Exception {
// 1、获取连接工厂
ConnectionFactory connectionFactory = RabbitmqConnectionFactory.getConnectionFactory();
// 2、创建连接
Connection connection = connectionFactory.newConnection();
// 3、创建通道、并指定消息确认模式
Channel channel = connection.createChannel();
// 设置消息确认模式
channel.confirmSelect();
// 5、发送消息
String msg = "this is confirm message !";
channel.basicPublish(EXCHANG_NAME, ROUTING_KEY, null, msg.getBytes());
// 6、添加消息确认监听
channel.addConfirmListener(new ConfirmListener() {
// 消息确认
@Override
public void handleAck(long l, boolean b) throws IOException {
System.out.println("--------handle Ack---------");
}
// 消息未确认
@Override
public void handleNack(long l, boolean b) throws IOException {
System.out.println("--------handle No Ack---------");
}
});
}
3、RabbitMQ的Return机制
return机制是保证消息不丢失,有些时候我们生产的消息没有投递到任何队列,或者队列名称、交换机、路由错了,导致没有投递到队列里面,这个时候return监听机制就能获取到未被成功投递的消息,然后做业务处理,生产消息的时候要设置消息确认模式,然后添加return监听器,设置mandatory为true,如果为false,那么broker端自动删除该消息。
public static void main(String args[]) throws Exception {
// 1、获取连接工厂
ConnectionFactory connectionFactory = RabbitmqConnectionFactory.getConnectionFactory();
// 2、创建连接
Connection connection = connectionFactory.newConnection();
// 3、创建通道
Channel channel = connection.createChannel();
// 设置消息确认模式
channel.confirmSelect();
// 添加return监听
channel.addReturnListener(new ReturnListener() {
@Override
public void handleReturn(int i, String s, String s1, String s2, AMQP.BasicProperties basicProperties, byte[] bytes) throws IOException {
System.err.println("消息投递失败!!!");
}
});
// 4、发送消息
String msg = "this is return msg !";
// mandatory, 设置为true,则监听器会接收到路由不可达的消息, 然后进行处理,如果设置为false,那么broker端自动删除该消息。
channel.basicPublish(EXCHANG_NAME, ROUTING_KEY, true,null, msg.getBytes());
}
rabbitmq开放端口:
- 5672: rabbitMq的编程语言客户端连接端口
- 15672:rabbitMq管理界面端口
- 25672:rabbitMq集群的端口

Exchange(交换机)只负责转发消息,不具备存储消息的能力,因此如果没有任何队列与Exchange绑定,或者没有符合路由规则的队列,那么消息会丢失!
RabbitMQ 怎么实现延迟消息队列?
Rabbit MQ死信队列、延时队列
TTL:一条消息或队列中所有消息的最大存活时间
死信队列:不希望消息被丢弃或手动干预而配置的保底方式
- 1.消息被消费方否定确认,使用channel.basicNack或channel.basicReject,并且重发属性requeue= false
- 2.消息在队列中存活时间超过设置的TTL时间
- 3.消息队列中消息数量超过最大队列长度
延时队列:借助普通队列 + 死信队列实现
设置TTL属性的普通队列,不监听消费,让它超时进入死信队列,只监听死信队列里的消费即可实现延时队列
还可以用rabbitmq-delayed-message-exchange 插件实现延时队列
场景:定时关单
- 订单创建同时发送消息给延时队列,
- 延时队列在30分钟未付款就经死信路由到死信队列,
- 订单系统监控死信队列,收到消息就关单并库存释放

顺序消息
一个Queue对应一下Consumer,把需要保证顺序的message都发送到一个queue当中,关闭autoack,prefetchCount=1,每次只消费一条信息,处理过后进行手工ack,然后接收下一条message,只是由一个Consumer进行处理,是可以保证顺序消费的
问题:一个消息队列多个消费者监听,consumer从MQ里面读取数据是有序的,但是每个consumer的开始执行时间或执行完成时间是不固定的,无法保证先读到消息的consumer一定先完成操作
解决方案1
- 1、发送的顺序消息,必须保证在投递到同一个队列,给每条消息加个序号,接收到多条消息之后,首先不是进行逻辑处理,而是直接分别入库,把第一条消息入库的同时,发送一个延迟消息(例如5分钟,用来保障所有的消息都接受到,进行统一处理),监听到延迟消息之后,根据sessionId和size查出一共多少条消息,然后根据消息顺序序号去处理
解决方案2
- 拆分多个queue,每个queue一个consumer,就是多一些queue而已,确实是麻烦点;这样也会造成吞吐量下降,可以在消费者内部采用多线程的方式取消费。
解决方案3
- 发送mq消息的时候,同组内上个消息id设置到当前消息的消息头中。
- 消费者接收到mq消息时,尝试从消息头中获取“同分组内上一个消息的消息id”。
- 获取到“同分组内上一个消息的消息id”,则查询消费记录,看是否消费过该消息id的消息。消费过,则允许进入mq消息处理逻辑,并插入消费记录(插入消费记录,是幂等操作);未消费过,则休眠指定时间,抛出ImmediateRequeueAmqpException,让消息回到requeue,待下次消费。
/**
* 发送消息到queue
*
* @param groupName 消息分组,同个分组内的消息顺序消费
* @param queue 队列
* @param msgBody 消息体
* @return 消息id
*/
void sendToQueueSequentially(String groupName, String queue, Object msgBody);
vhost
rabbitmq的vhost相当于迷你版rabbitmq,里面有独立的权限系统,它作为权限隔离的手段,比如,不同的应用可以跑在不同的vhost中(同一个rabbitmq)
rabbitmq默认没限制,但可以手动设置queue数量和容量
KafKa

设计原则
- 高吞吐、低延迟:非常快,几十万/s,最低延迟几毫秒;
- 高伸缩性:每个主题(topic) 包含多个分区(partition),主题中的分区可以分布在不同的主机(broker)中;
- 持久性、可靠性:Kafka 能够允许数据的持久化存储,消息被持久化到磁盘,并支持数据备份防止数据丢失,Kafka 底层的数据存储是基于 Zookeeper 存储的,Zookeeper 我们知道它的数据能够持久存储;
- 容错性:允许集群中的节点失败,某个节点宕机,Kafka 集群能够正常工作;
- 高并发:支持数千个客户端同时读写。
- 消息系统,日志收集,kafka流式处理+集合flink(实时统计和大屏)
数据保留的策略?
- 按照过期时间保留
- 按照存储的消息大小保留。
时间和大小不论那个满足条件,都会清空数据
kafka读取性能影响因素:
- cpu 性能瓶颈
- 磁盘读写瓶颈
- 网络瓶颈
集群注意点:
- 最好不要超过 7 个,因为节点越多,消息复制需要的时间就越长,吞吐量就越低。
- 集群数量最好是单数,因为超过一半故障集群就不能用了,设置为单数容错率更高。
为何如此之快
- 顺序读写(避免了随机磁盘寻址的浪费),接近内存;
- 零拷贝(避免了内核之间的切换);
- 消息压缩(批处理数据压缩减少 I/O 延迟);
- 分批发送(将数据记录分批发送)。
Linux中的零拷贝
应用程序跟操作系统共享缓冲区,它们之间不需要再互相拷贝了
应用程序数据-》复制到内核缓冲区-》复制到socket缓存区-》复制到网卡
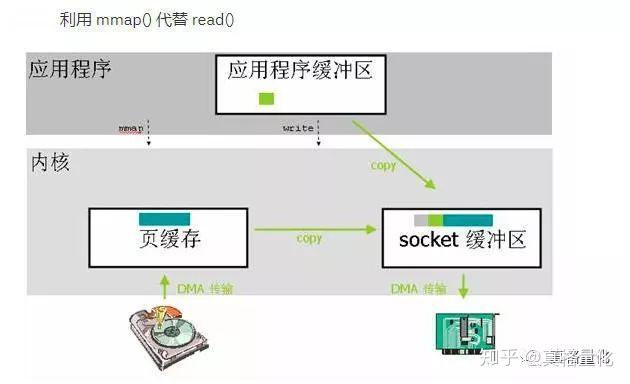

- mmap方式,用户空间(文件映射)和内核共享数据,Java对mmap的实现是MappedByteBuffer类,在内存中文件读写
- sendfile方式 DMA将数据拷贝到内核缓冲区,数据被拷贝到socket缓冲区,接下来DMA再将数据拷贝到网卡设备。不需要将数据拷贝或者映射到应用程序地址空间中去,适用于应用空间不需要对访问数据进行处理情况。FileChannel的transferTo()和transferFrom(),将数据从一个channel传输到另一个channel
- DMA无需CPU的参与就可以让外设和系统内存之间进行双向数据传输的硬件机制
基本概念和架构
1.Producer 发布的消息在分区partition上,partition算法,随机或哈希。(分区索引值 = 消息记录主键的哈希值取绝对值 % 分区)
2.Consumer
3.Topic:主题,理解为一个队列
4.Consumer Group (CG):消费者组,一个topic可以有多个CG。topic的消息会复制到所有的CG,但每个partion只会把消息发给该CG中的一个consumer(防止重复消费)。
实现广播:只要每个consumer有一个独立的CG就可以了(在不同cg,都可以消费)。
实现单播:只要所有的consumer在同一个CG(只有一个consumer可以消费)。
5.Broker :一台kafka服务器就是一个broker。一个集群由多个broker组成。
(1)Topic 与broker
首先,一个broker可以容纳多个topic,同一个kafka集群可以共同拥有一个topic,而同一个topic又拥有不同的分区,分布在不同的borker上,也就是不同的机器上,所以,分区是分布式的,则数据也是分布式的,kafka就是分布式模式。


- 同一个topic可以在同一集群下的多个Broker中分布。
- 发布的消息在分区partition上
- topic的消息会复制到所有的CG,但每个partion只会把消息发给该CG中的一个consumer(防止重复消费)
- 消费者和分区建立连接,这个分区的内容只能是由这个消费者消费
(2)消费者组、消息、分区
第一,同一个消费者组只能有一个消费者去消费(防重复消费)。
第二,消费者组以分区为单元,就相当于消费者和分区建立某种socket连接,进行传输数据,所以,一旦建立这个关系,这个分区的内容只能是由这个消费者消费。
(3)为什么说kafka是分布式模型呢?
Kafka是一个分布式系统,用Zookeeper来管理、协调Kafka集群中的各个代理(Broker)节点。当Kafka集群中新添加一个代理节点,或者某一台代理节点出现故障时,Zookeeper服务将会通知生产者应用程序和消费者应用程序去其他的正常代理节点读写。
6.Partition:分区,为了实现扩展性,一个大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)。kafka只保证按一个partition中的顺序将消息发给consumer,不保证一个topic的整体(多个partition间)的顺序。每个partition有多个副本分布在不同的broker中。
7.Offset:偏移量,kafka的存储文件都是按照offset.kafka来命名,例如你想找位于2049的位置,只要找到2048.kafka的文件即可。当然the first offset就是00000000000.kafka。

每个partition在存储层面是一个append log文件,发布到此partition的消息会追加到log文件的尾部,为顺序写入磁盘。每条消息在log文件中的位置成为offset(偏移量),offset为一个long型数字,唯一标记一条消息。
每个消费者唯一保存的元数据是offset值,这个位置完全为消费者控制,因此消费者可以采用任何顺序来消费记录。
follower如何与leader同步数据
Kafka的复制机制既不是完全的同步复制,也不是单纯的异步复制。
-
完全同步复制要求All Alive Follower都复制完,这条消息才会被认为commit,这种复制方式极大的影响了吞吐率。
-
而异步复制方式下,Follower异步的从Leader复制数据,数据只要被Leader写入log就被认为已经commit,这种情况下,如果leader挂掉,会丢失数据,
-
kafka使用ISR的方式很好的均衡了确保数据不丢失以及吞吐率。Follower可以批量的从Leader复制数据,而且Leader充分利用磁盘顺序读以及零拷贝机制,这样极大的提高复制性能,内部批量写磁盘,大幅减少了Follower与Leader的消息量差。
分区中的所有副本统称为AR(Assigned Repllicas)。所有与leader副本保持一定程度同步的副本(包括Leader)组成ISR(In-Sync Replicas),ISR集合是AR集合中的一个子集。消息会先发送到leader副本,然后follower副本才能从leader副本中拉取消息进行同步,同步期间内follower副本相对于leader副本而言会有一定程度的滞后
消息是否会丢失和重复消费
要确定Kafka的消息是否丢失或重复,从两个方面分析入手:消息发送和消息消费。
1、消息发送
Kafka消息发送有两种方式:同步(sync)和异步(async),默认是同步方式,可通过producer.type属性进行配置。Kafka通过配置request.required.acks属性来确认消息的生产:
- 0---表示不进行消息接收是否成功的确认;
- 1---表示当Leader接收成功时确认;
- -1---表示Leader和Follower都接收成功时确认;
综上所述,有6种消息生产的情况,下面分情况来分析消息丢失的场景:
(1)acks=0,不和Kafka集群进行消息接收确认,则当网络异常、缓冲区满了等情况时,消息可能丢失;
(2)acks=1、同步模式下,只有Leader确认接收成功后但挂掉了,副本没有同步,数据可能丢失;
2、消息消费
Kafka消息消费有两个consumer接口,Low-level API和High-level API:
Low-level API:消费者自己维护offset等值,可以实现对Kafka的完全控制;
High-level API:封装了对parition和offset的管理,使用简单;
如果使用高级接口High-level API,可能存在一个问题就是当消息消费者从集群中把消息取出来、并提交了新的消息offset值后,还没来得及消费就挂掉了,那么下次再消费时之前没消费成功的消息就“诡异”的消失了;
解决消息丢失
- 同步模式下,确认机制设置为-1,即让消息写入Leader和Follower之后再确认消息发送成功;
- 异步模式下,为防止缓冲区满,可以在配置文件设置不限制阻塞超时时间,当缓冲区满时让生产者一直处于阻塞状态;
消息重复
将消息的唯一标识保存到外部介质中,每次消费时判断是否处理过即可(幂等性)。乐观锁多版本控制,分布式锁
消息顺序性
kafka每个partition中的消息在写入时都是有序的,消费时,每个partition只能被每一个group中的一个消费者消费,保证了消费时也是有序的。
整个topic(多个partition)不保证有序。如果为了保证topic整个有序,那么将partition调整为1
如果自己设计消息队列,怎么设计

40.Redis
c语言实现
redis基本命令:

lpush list a b c //从左放元素
lrange list 0 3/-1(所有) //c b a 展示元素
lpop list //c 从左弹出第一元素
rpop // a 从右边弹出
blpop list 0/expiretime //阻塞从左弹出队列,如果0,如果list无数据,一直阻塞直到有数据
lindex...索引
lpush list a b c d e //从左放元素
ltrim list 0 2 //压缩数据 list变成 a b c 其他数据没有了,只保留热点数据
相对于java自带的数据和结构,redis是分布式数据结构,可以在集群上使用,很多计数,比如访问次数,计算使用redis更方便,比起通过db实现
String数据结构
命令和场景:



incr item:01 // 执行一次加1,计算点击次数,分布式用redis替代java
redis中 key 是string类型,1 bype = 8 bit , 8byte 2^8 =256
SDS simple dynamic string
String类型:redis的value指向一个redisObject对象,依据存储数据类型进行变化
- value 整数 底层int,
- 字符则 embstr,
- 超过44则为raw
- embstr原理:cpu cache区一次读64byte - redisobject本身占用16byte - sds_type_8占用4byte,只要数据不大于44 byte,那么就可以放在同一个object,需要要另外*ptr指向另一块空间,减少一次磁盘io
- int原理,将数字变成长整型 8个 byte,比较如果再2^ 8之内,则直接将指针赋值,而不是地址,不需要另外开辟空间
redis链表加数组实现海量数据存储,hash运算放入对应数组节点,如果出现hash冲突,hash值相同则头插法实现插入(key原理和hashmap jdk1.7类似)
list数据结


quicklist双端链表 + ziplist压缩列表
quicklist双端链表,每个节点都是一个quicklistNode双向链表,里面存储压缩列表,每个节点指向一个压缩列表,将整个ziplist切分成小份,同时quicklist的head指向头节点,tail指向尾节点,这样可以找到所有的数据
- 单个ziplist>8KB,分列生成新节点,数据存入新节点
优点:节省空间

默认数据节点规则

- 每个ziplist 最大为8kb
- 当数据非常大的时候,quicklistNode非常多,数据存储很零散,这时候设置压缩深度,0=不压缩,1=除了第一个和第二个,最后一个和最后第二个不压缩,中间全部压缩到一起

hash 数据结构
命令和场景:

dict字典,k-v结构,数据小使用ziplist数据存储,ziplist元素个数>512 或 单个元素>64byte 时用hashtable

- redis conf 文件中可以修改阈值
- hash和string,hash不能设置过期时间,string存数据会导致冗余并且可能扩容,hash则不会通过指针指向另一块区域
- 当冲突时,通过数组转链表(链表指针法,注意头插法)和扩容解决hash冲突
set 数据结构

spop表示执行完之后从List中剔除,例如抽了1等奖用户不能再抽2等奖


命令和场景:

抽奖小程序
sadd key 用户 //添加用户
scard key //统计用户个数
smembers key //展示所有用户
sismember key //某人是否在里面
spop key 3 // 随机抽取三个人中奖
其他共同朋友圈,差集朋友,并集
value为null的字典,整数那么intset数据结构存储,元素个数>512 或不能用整数存储 则 用hashtable

sadd a-set 1 2 3 4
sadd b-set a b c d
type a-set // set
object encoding a-set //intset
object encoding b-set //hashtable
zset 数据结构
命令和场景:




zset字典 +跳表(skiplist),元素个数>128 或 单元素>64byte 都用skiplist
跳表数据结构:zskiplist节点:索引 + 数据(list是一个双向链表),优点:大数据情况下,查找效率提升明细
redis计算千万级别用户每日登录情况,以及连续登录用户,或至少一天登录?
使用 bitmap 进行统计


-
依据分值进行排序(顺/倒序),做排行榜功能
-
两个entry存一个元素,元素 + score
-
底层数据结构,一个dict字典<key,value>,一个跳表

-
跳表时间复杂度为logN,类似于二分查找,没加一层索引层节点个数减半


-
跳表数据结构 zskiplist
- zskiplistNode节点:索引 + 数据 (元素+分值+索引层层高+头尾指针),包含头尾指,针,level直接的跨度span(比如查明某个元素排名),list是一个双向链表
- length 元素个数
- level 层高(最高的层高)
- header存储层之间的关系,不存数据
- 索引层层高使用幂次定律(升一层1/4 X 1/4 X ..)计算,实现层级越高节点越少(概率越小,类似二分查找),尽量保证节点都在底层,log n 的复杂度
优点:大数据情况下,查找效率提升明细
缺点:设计索引层等会需要耗费一些资源
radis计算千万级别用户每日登录情况,以及连续登录用户,或至少一天登录
使用 bitmap 进行统计,set bit-key,它的数据结构是一个2^32-1bit的数组(512 M)字符串最大值,存放1/0数字,如果登录设置为1即可,可以存放4亿多用户数,连续登录只需要将两天用按位与 “&” 运行即可如果结果为1则表示连续登录,月活则保持30个bitmap,然后进行与运算
redis 扩展
如何保证Redis和数据库的一致
更新操作不可行,更新缓存,数据库更新失败,那么他们就不一致了,同理
无法保证完全消除数据一致性问题
1.先删缓存,再写数据库,高并发环境,删除缓存还没有写数据库,此时没缓存了,读取的脏数据到缓存中
解决方案:
-- 写操作不频繁场景适合
- 不删缓存,将缓存修改为特殊值(-999),客户端读取缓存发现默认值,就休眠一会再查Redis,问题,特殊值有侵入性,如果写操作较多,休眠时间多次重复,对性能有影响
- 延时双删(业界常用),先删缓存,然后写数据库(没更新完,另一个线程查询旧数据并同步到缓存,不一致),休眠一会,再次删除缓存(删脏缓存),写操作频繁,还是会有脏数
-- 始终只能保证一定时间内的最终一致性
2.先写数据库,再删缓存,如果数据库写完,缓存删除失败或还没来得及删,数据不一致
- 给缓存设置一个过期时间。问题:过期时间内,缓存不会更新
- 引入MQ重试机制,保证原子操作,数据库写入,MQ保证一定删除缓存,某个时间内不一致
- 删除麻烦,就把热点数据缓存设置永不过期,只是在value加一个逻辑过期时间,另起一个后台线程,对于已逻辑过期缓存,进行删除
PV、UV、IP分别是什么意思?
- PV(Page View)访问量, 即页面浏览量或点击量
- UV(Unique Visitor)独立访客,统计1天内访问某站点的用户数
- IP(Internet Protocol)独立IP数,是指1天内多少个独立的IP浏览了页面,即统计不同的IP浏览用户数量
官方命令网址:http://redis.cn/commands.html
Scan命令
Redis Scan 命令用于迭代数据库中的数据库键。
SCAN 基于游标的迭代器,每次被调用之后, 都会向用户返回一个新的游标, 用户在下次迭代时需要使用这个新游标作为 SCAN 命令的游标参数, 如果新游标返回 0 表示迭代已结束。
SCAN cursor [MATCH pattern] [COUNT count]
- cursor - 游标。
- pattern - 匹配的模式。
- count - 指定从数据集里返回多少元素,默认值为 10 。

(如果没外网,查看帮助)
redis 四种特殊的数据结构
-
help @命令
-
bloomFilter 布隆过滤器 位数组 + hash函数,缓存穿透判断key,底层bitmap 位图
bf.add key element 添加 bf.exists key element 判断是否存在 bf.madd key element1 element2 ... 批量添加 bf.mexists key element1 element2 ... 批量判断 -
HyperLogLog(超级日志) 计算页面的UV,替代set实现去重和计数(内存消耗),不精确的去重计数方案(误差值在 0.81% 左右),HyperLogLog 只占用 12KB 的内存
pfadd key element 添加 pfcount key 计算 pfmerge destkey sourcekey1 sourcekey2 ... 合并
-
bitmap 统计用户上班天数
setbit key index 0/1 设置某位的值 getbit key index 获取某位的值 bitcount key start end 获取指定范围内为1的数量,start 和 end是指的字符位置不是比特位置 bitpos key bit start end 获取第一个值为bit的从start到end字符索引范围的位置 bitop and/or/xor/not destkey key1 key2 对多个 bitmap 进行逻辑运算。

-
GEO/GeoHash(地理索引) 计算附近的人,附近的商店,具体原理是将地球看成一个平面,并把二维坐标映射成一维(精度损失的原因)
geoadd key longitude latitude element(后面可配置多个三元组) 添加元素 geodist key element1 element2 unit 计算两个元素的距离 geopos key element [element] 获取元素的位置 geohash key element 获取元素hash georadiusbymember key element distanceValue unit count countValue ASC/DESC [withdist] [withhash] [withcoord] 获取元素附近的元素 可附加后面选项[距离][hash][坐标] georadius key longitude latitude distanceValue unit count countValue ASC/DESC [withdist] [withhash] [withcoord] 和上面一样只是元素改成了指定坐标值
-
Stream
消息ID的序列化生成 消息遍历 消息的阻塞和非阻塞读取 消息的分组消费 未完成消息的处理 消息队列监控
redis中实现消息队列的几种方案
-
基于List的 LPUSH+BRPOP 的实现
1.使用rpush和lpush操作入队列,blpop和brpop操作出队列。 队列为空时,lpop和rpop会一直空轮训,消耗资源;所以引入阻塞读blpop和brpop(b代表blocking),阻塞读在队列没有数据的时候进入休眠状态,一旦数据到来则立刻醒过来,消息延迟几乎为零。 2.空闲连接的问题。如果线程一直阻塞在那里,Redis客户端的连接就成了闲置连接,闲置过久,服务器一般会主动断开连接,减少闲置资源占用,这个时候blpop和brpop或抛出异常,所以在编写客户端消费者的时候要小心,如果捕获到异常,还有重试。 -
PUB/SUB,订阅/发布模式
SUBSCRIBE,用于订阅信道 PUBLISH,向信道发送消息 UNSUBSCRIBE,取消订阅 1.此模式允许生产者只生产一次消息,由中间件负责将消息复制到多个消息队列,每个消息队列由对应的消费组消费。 2.典型的广播模式,一个消息可以发布到多个消费者 3.生产者只生产一次消息,由中间件负责将消息复制到多个消息队列,每个消息队列由对应的消费组消费。若客户端不在线,则消息丢失,不能寻回,不适合做消息存储,擅长处理广播,即时通讯,即时反馈的业务 -
基于Sorted-Set的实现
Sortes Set(有序列表),zset 去重加有序(score)。内部实现是“跳跃表”。 有序集合的方案是在自己确定消息顺ID时比较常用,使用集合成员的Score来作为消息ID,保证顺序,还可以保证消息ID的单调递增。制作一个有序的消息队列了。 优点 就是可以自定义消息ID,在消息ID有意义时,比较重要。 缺点 缺点也明显,不允许重复消息(因为是集合),同时消息ID确定有错误会导致消息的顺序出错。 -
基于Stream类型的实现

Stream为redis 5.0后新增的数据结构。支持多播的可持久化消息队列,实现借鉴了Kafka设计。
1.它有一个消息链表,将所有加入的消息都串起来,每个消息都有一个唯一的ID和对应的内容。消息是持久化的。每个Stream都有唯一的名称即Redis的key,首次使用xadd指令追加消息时自动创建。
2.每个Stream都可以挂多个消费组,每个消费组会有个游标last_delivered_id在Stream数组之上往前移动,表示当前消费组已经消费到哪条消息了。
3.每个消费组(Consumer Group)的状态都是独立的,相互不受影响。同一份Stream内部的消息会被每个消费组都消费到。
4.同一个消费组(Consumer Group)可以挂接多个消费者(Consumer),这些消费者之间是竞争关系**,任意一个消费者读取了消息都会使游标last_delivered_id往前移动。
5.消费者(Consumer)内部会有个状态变量pending_ids(PEL),消息ID列表,保存未被ack的消息,只有ack了,才去掉,防止消息丢失(如果一值没ack且消费者组很大会导致内存放大)
redis客户端

- redisTemplate,redis的key序列化不要用java的,因为会有些xxx,0、。等特殊字符序列化问题,使用redis自己的StringRedisSerializer,value用JsonRedisSerializer
@Configuration
public class RedisConfig {
@Resource
private RedisConnectionFactory factory;
@Bean
public RedisTemplate<String, Object> redisTemplate() {
RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setValueSerializer(new JsonRedisSerializer<>(Object.class));
return redisTemplate;
}
}
Redis事务
ACID
- 原子性:一起执行,一起不执行
- 一致性:保证数据一致性,失败也会恢复执行
- 隔离性:单线程执行,不存在事务冲突
- 持久性:AOF,RDB
redis不支持事务回滚,但会检查命令语法错误,不支持检查运行时错误(比如空指针,1/0等),不会回滚
- watch,乐观锁,cas监控key被修改或删除,后续事务不会被执行,直到exec
- multi,开启事务,总是返回ok,此事务没执行完毕,其他命令都不会执行,会放到一个队列中,直到exec命令调用才会执行
- exec,按照命令执行顺序执行所有事务命令块并返回值,当被打断,返回空值nil
- discard,清空事务队列,放弃执行事务
- unwatch,取消watch对所有key的监控
redis事务原理:执行multi命令时候,后续操作缓存起来,没执行,等exec,就全部会执行,所以这就是为什么事务不回滚原因
redis集群
- 主从模式
- 哨兵模式,在主从基础上加了个故障转移(主节点挂了切换到从节点),实现高可用
- Redis Cluster 服务端分片 哈希槽,默认16384个槽,通过hash将数据分片,每个节点均分哈希槽区间的数据,互为主从,每个节点为主,相邻节点是它的从节点,主从不保证强一致性,扩容时把旧节点数据迁移一部分到新节点(3个节点每个5000个槽,扩容1个节点,每个节点分1250给新节点即可)
哈希,分布式寻址,每台机器保存一部分槽,找某个key的槽,找到哪台服务器
redis集群不可用场景
1.当主、从节点都挂了,且cluster-require-full-coverage=yes(主节点宕机,故障转移时候,整个集群不可用,如果设置为no,只影响它负责槽,不影响其他主节点),会导致不可用
2.集群半数宕机(因为选举投票需要半数以上才能通过)
宕机还会导致部分数据只写入主节点,没能同步到从节点(异步进行的),导致用户查询不到
redis主从复制
执行slaveof命令或设置slaveof选项,服务器复制数据
全量复制:
- 主节点bgsave命令fork子进程将RDB持久化到磁盘(整个数据快照,非常消耗cpu)
- 网络传输给从节点,从节点清空老数据,载入RDB文件是阻塞,没无法响应客户端其他命令;
- 如果从节点bgrewriteaof,也会带来额外消耗
增量复制:
- 复制偏移量,主从之间会维护一个复制偏移量
- 复制积压缓冲区,主节点内部维护一个固定长度、先进先出队列,当offset超过缓冲区长度,无法部分复制,只能全量复制
- 服务器运行id,每个redis节点都有其运行ID,主节点将id发给从节点,当从节点断开连接就依据id进行关联主节点,如果id相同,表示主从节点之前同步过,尝试继续部分复制,如果不相同,表示主从节点已经切换了,那么只能全量复制
总结:首次全量同步,后续都是增量同步,但如果偏移量超过缓存区或从节点存主节点id不匹配也会是全量同步
查看和设置内存大小?
redis.conf文件或info命令查看内存大小maxmemory(byte),64位不限大小(32位 3G),一般设置物理内存3/4

-
设置内存可以修改配置文件或命令设置

-
info memory命令:used_memory_human:26.55M //数据占用了多少内存
内存打满会如何?

- redis内存淘汰策略,默认使用noeviction,不进行删除,内存打满会直接oom,命令执行失败
- key过期策略
- 定期删除(redis的每个值设置过期时间),过期立即删除会使内存干净,但导致一直需要消耗cpu资源(内存友好,cpu不友好)
- 惰性删除,过期但需要被访问才进行删除(或手动flushdb命令),可能导致大量过期但未被删除的key(cpu友好,内存不友好)
- 总结:执行删除太多太久会影响退化定时,太少太短则像惰性一样浪费内存,所以要合理设置执行时长和执行频率
- 但还是可能存在定期和随机没能删除的数据,所以有了六种淘汰策略!
1、volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
2、volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
3、volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
4、allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰
5、allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
6、no-enviction(驱逐):禁止驱逐数据
-
两个维度:所有key或设置了过期的时间的所有key,lru(时间),lfu(频率),random(随机),ttl(将要过期的key),noevication(不删除key)
一般配置 maxmemory-policy allkeys-lru //key最近最久未使用 配置文件或命令:config set maxmemory-policy allkeys-lrulinkHashMap本身能满足lru算法,自带排序和过期淘汰最久未使用数据
幂等性
- 唯一性id,数据库或redis分布式锁
- 版本控制乐观锁 version
- 状态控制,比如已支付状态必须从未支付状态过来
Redis 和 memcache 有什么区别?
- 存储方式:memcache 把数据全部存在内存之中,断电后会挂掉,数据不能超过内存大小;Redis 有部份存在硬盘上,这样能保证数据的持久性。
- 数据支持类型:memcache 对数据类型支持相对简单;Redis 有复杂的数据类型。
- value 值大小:Redis 最大可以达到 512mb;memcache 只有 1mb。
Redis 为什么是单线程的?
因为 cpu 不是 Redis 的瓶颈,Redis 的瓶颈最有可能是机器内存或者网络带宽。既然单线程容易实现,而且 cpu 又不会成为瓶颈,那就顺理成章地采用单线程的方案了。
关于 Redis 的性能,官方网站也有,普通笔记本轻松处理每秒几十万的请求。
而且单线程并不代表就慢 nginx 和 nodejs 也都是高性能单线程的代表。
Redis基于Reactor模式多路复用技术,
Redis线程模型
- 基于Reactor(响应式)模式,文件事件处理器(file event handler),它是单线程,所以Redis是单线程模型
- 采用IO多路复用监听多个Socket,Socket事件类型不同来选择对应处理器处理事件
- 优点,纯内存操作,基于非阻塞IO多路复用,避免多线程频繁切换上下文带来消耗
总结:业务简单,适合用单线程,而很复杂的业务比如需要IO等待的,使用多线程
线程安全,Redis 的多线程部分只是用来处理网络数据的读写和协议解析(网络通信过程捕获网络中的数据信息,将数据包解码),执行命令仍然是单线程顺序执行。
redis 6.0 支持多线程
未默认开启,在conf文件进行配置
io-threads-do-reads yes
io-threads 线程数
官方建议:4 核的机器建议设置为 2 或 3 个线程,线程数一定要小于机器核数
缓存穿透,缓存雪崩,缓存击穿
缓存穿透是指恶意查询一个不存在的数据,由于缓存无法命中,直接访问DB, 解决:null空结果也进行缓存,但它的过期时间会很短,最长不超过五分钟。
- 采用布隆过滤器白名单,将可能存在数据hash到一个足够大的bitmap中一定不存在数据肯定被拦截掉(虽然存在误判,可以控制误判 hash值相同,本身不相同)
缓存雪崩是指在我们设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到DB,DB瞬时压力过重雪崩。解决:原有的失效时间基础上增加一个随机值,每一个缓存的过期时间的重复率就会降低。
- redis宕机,redis集群,保证高可用
- redis刚启动,还没有缓存,缓存预热,启动服务之前先写一个接口,将数据放到缓存中
缓存击穿是指对于一些设置了过期时间的key,key在大量请求同时进来之前正好失效(启动还没有缓存的时候,称为热加载),那么所有对这个key的数据查询都落到db(或者本身key就没有缓存,突然100万高并发请求过来了,都还没来得及生成缓存,db承受),我们称为缓存击穿
- 热点数据可以改,永不过期
分布式锁主流的实现方案:
- 基于数据库实现分布式锁
新建一张表id,lock,createdate,lock唯一标志,1000个请求过来,只有一个请求插入成功,插入成功的这笔才能获取锁执行业务,其他请求等这个请求处理完成释放锁,反常重试获取才能执行
- 基于缓存(Redis等)
setnx执行成功,获取锁,才能执行业务逻辑,成功释放锁,其他请求抢锁资源
-
基于Zookeeper
每一种分布式锁解决方案都有各自的优缺点: -
性能:redis最高
-
可靠性:zookeeper最高,自动释放锁(临时节点,端口连接自动释放)
这里,我们就基于redis实现分布式锁。

实现原理:借助于redis中的命令setnx(key, value),key不存在就新增,存在就什么都不做。同时有多个客户端发送setnx命令,只有一个客户端可以成功,返回1(true);其他的客户端返回0(false)。
问题1:setnx刚好获取到锁,业务逻辑出现异常(或宕机),导致锁无法释放
解决:设置过期时间,自动释放锁。
- 首先想到通过expire设置过期时间(缺乏原子性:如果在setnx和expire之间出现异常,锁也无法释放)
- 在set时指定过期时间(推荐)
问题2:多线程情况可能会释放其他服务器的锁
解决:setnx获取锁时,设置一个指定的唯一值(例如:uuid);释放前获取这个值,判断是否自己的锁
为了确保分布式锁可用,我们至少要确保锁的实现同时满足以下四个条件:
-
互斥性。在任意时刻,只有一个客户端能持有锁。=》lock
-
不会发生死锁。即使有一个客户端在持有锁的期间崩溃而没有主动解锁,也能保证后续其他客户端能加锁。=》设置过期时间
-
解铃还须系铃人。加锁和解锁必须是同一个客户端,客户端自己不能把别人加的锁给解了。=》UUID
-
加锁和解锁必须具有原子性(要么都成功,要么都失败)reddssion。=》lua脚本
-
看门狗机制(锁续命机制源码):

-
如果存在key再设置过期时间
-
每(1/3 * 30s )10s执行一次


//
1.设置过期时间;2.设置必须解锁;3.设置只能解除自己的锁;4.设置还未执行完程序给将要过期锁自动续命
try{
Rlock redissonLock = redissonLock(lockKey);
redis.locksonLock.lock();=》//setIfAbsent(lockKey,id,30)
//默认续期30s
...
}finally{
redisonLock.unlock();
}

实际的核心代码,其实就是一段lua脚本
-
判断key是否存在,不存在设置,并设置过期时间(默认 30s)
-
问题:如果设置锁和设置超时时间没有同时成功,会导致死锁
解决:redis是c语言编写的,c语言执行保证此段lua脚本具有原子性(相当于这里是一句代码),这段lua脚本要么都执行成功,要么都不成功
看门狗机制(锁续命机制源码):
- 如果存在key再设置过期时间
- 每(1/3 * 30s )10s执行一次
从cap角度解析redis和zookeeper锁异同:
zookeeper主从结构:cp数据一致性,半数节点同步成功,才会告知leader成功,主从节点切换,拥有最新数据的节点才能成为leader节点
redis主从切换导致锁丢失:主节点获得锁(获取成功)还未同步到从节点就宕机,此时锁丢失了,而且从节点还能再次获得这个锁
解决方案:Redlock:半数节点加锁成功才算成功,很少用可能有bug,还不如zookeeper稳定(借鉴zookeeper)

分布式锁导致的性能下降问题(同步串行化):
- 异步消息队列中执行
- 分段锁,非加锁段位不受加锁影响,提升性能越多即分段越细,最多达到每一个Key一个段位,(如果某个段位减库存不够,合并其他段位减库存)
集群环境下分布式锁可能问题
只能删除自己的锁,解锁在finally中防异常,设置过期时间防止宕机不释放锁, 防止主机宕机锁未复制到从机,RedLock + Redisson
redis的bigkey问题:
即某一个key的value过于大(一般指超过10kb,String的话,单个value太大,或元素个数太多(对象)),
- 因为redis执行命令是单线程的,拿取这个大key时间过长,阻塞后续请求,影响性能
- 内存空间使用不均匀
解决方案:分段存储,分多个key即可
解决redis的重复key问题:
- 1.业务隔离,使用不同redis库
- 2.key命名,业务模块 + 系统名 + key
- 3.锁,针对多个客户端并发写key,顺序2-》3-》4,正确结果是4,但有可能并发情况导致结果是2,此时可以使用分布式锁,或者乐观锁,通过时间戳,时间戳,找最大时间戳的值
如何提高缓存命中率(缓存范围越大越多)
1.提前加载缓存(预热)
2.增加缓存存储空间,能缓存数据越多
3.调整缓存类型,比如(key,name,value),如果使用string,那么序列号对象只能每个都一样才命中,而使用hash,可以单独比较name,即可命中
Redis 支持的 Java 客户端都有哪些?
支持的 Java 客户端有 Redisson、jedis、lettuce 等。
jedis 和 Redisson 有哪些区别?
- jedis:提供了比较全面的 Redis 命令的支持。
- Redisson:实现了分布式和可扩展的 Java 数据结构,与 jedis 相比 Redisson 的功能相对简单,不支持排序、事务、管道、分区等 Redis 特性。
Redis 持久化有几种方式?
Redis 的持久化有两种方式,或者说有两种策略:
开放默认端口:6379
1.配置参数,指定时间内更改次数超过阈值会执行快照
save 900 1
save 300 10
save 60 10000
2.手动执行bgsave/save 显示触发生成快照(save执行期间会导致redis不可用)
3.持久化过程,是通过fork子进程来完成的,不影响redis使用,如果此时候新来的属性修改,此时通过copyandwrite(从子进程中copy出来,再另一块空间修改,子进程部分只读)使得变量是保持只读属性的,不会影响子进程中的变量,
-
RDB(Redis Database):指定的时间间隔能对你的数据进行快照存储。

-
只要有临时文件rdb,重写redis数据马上恢复过来
-
保存全量数据,数据大很消耗性能
-
到一个存储点才备份,最后一次丢失
-
AOF(Append Only File):每一个收到的写命令都通过write函数追加到文件中。


-
不存在最后一次丢失问题
-
占用更多磁盘,io读取操作
-
记录每个写操作,将所有之前数据重新写一遍,再追加,rdb记录了所有的数据,直接恢复
AOF的追写策略(命令):建议使用每秒同步一次(everysec)策略。
混合持久化

实际场景中:RDB+AOF混合,定时RDB,在下一次RDB之前,则采用AOF追加写入方式, 而宕机启动的时候使用RDB方式加载整个快照,之后就用AOF方式进行追加

redis阻塞场景

redis快的原因
- 存内存操作
- 单线程操作,避免上下文切换
- 渐进式rehash(扩容),例如需要将10000的A数组进行扩容并移到新数组B,每个客户端请求移动一点,以大化小(虽然需要的数据在A、B数组都查(没移完))
- 缓存时间戳,将系统时间定时任务拿到并缓存起来,不需要每次都去调用系统
Redis 如何做内存优化?
1.缩减键值对,key满足业务,越短越好,value用高效序列化工具:protostuff,kryo,字符串也序列化
2.对象共享池,Redis内存维护一个[0-9999]的整数对象池,不需要另外创建和内存开销,尽量使用整数对象以节省内存
3.尽量使用Redis的hash,hash存储数据比单独每个字符串每个key存储更节约内存
Redis 常见的性能问题有哪些?该如何解决?
- 主服务器写内存快照,会阻塞主线程的工作,当快照比较大时对性能影响是非常大的,会间断性暂停服务,所以主服务器最好不要写内存快照,让从库持久化。
- Redis 主从复制的性能问题,为了主从复制的速度和连接的稳定性,主从库最好在同一个局域网内。
Redis 6有哪些方面的提升?
- 基于内存而且使用IO多路复用技术,单线程速度很快
- 引入多线程用以优化某些操作(删除大键值对,具体命令UNLINK、FLUSHALL ASYNC 和 FLUSHDB ASYNC)
- 读写网络占用大量cpu时间,多线程模式会使得性能很大提升,执行命令仍然是单线程,不需要去控制 key、lua、事务,LPUSH/LPOP 等等的并发问题。
41.分布式事务
2PC预提交锁定所有资源
TCC加了中间状态try,cancel,不锁定资源
TA直接执行完毕并记录undolog日志,方便回滚还原,只锁定涉及的资源
3PC新增超时机制abort,询问canCommit(如果不满足,后续不需要执行),以及commit阶段超时未接收指令自动提交(自带undolog回滚),只锁定涉及的资源(某几条记录)
2PC 两阶段提交(atomikos框架),协议(XA/JTA)
预提交 -》提交

-
预提交,提交阶段,sql执行完毕并锁定所有服务资源,等待协调器通知提交/回滚(通知失败(概率很小),重试预提交是否成功,否就预提交失败)
-
极端,一直执行失败:log日志记录,定时任务补偿,人工处理
2PC 两阶段补偿型方案TCC(Try-Confirm-Cancel)
try(预操作,比如冻结库存) -> commit -> cancel(不管try失败还是commit失败,马上cancel)


- 对比2PC,TCC虽然开发api更多(每个api需要开发 try api,confirm api,cancel api),但是锁粒度减小了(锁定执行服务资源),并且执行完可以释放锁资源(库存服务更新到冻结状态,不锁定资源),对于整个系统,高并发场景,大大提高了并发能力

3PC 两阶段提交
准备阶段 -》预提交阶段(undo和redo信息记录到事务日志中) -》提交阶段(如果无法及时接收到协调者的doCommit或者rebort请求时,会在等待超时之后,会继续进行事务的提交)

三阶段提交升级点(基于二阶段):
- 引入超时机制,中断,
- 新增准备阶段(canCommit询问参与者是否都能正常执行,减少会续阻塞)。
在preCommit和doCommit阶段,如果协调器接受到no或超时没接收都会下发中断abort指令
在doCommit阶段,如果参与者无法及时接收到来自协调者的doCommit或者rebort请求时,会继续进行事务的提交(cancommit和precommit都成功了,参与者人为大概率是成功的)。
总结:相对于2PC,3PC主要解决的单点故障问题,并减少阻塞,因为一旦参与者无法及时收到来自协调者的信息之后,他会默认执行commit。而不会一直持有事务资源并处于阻塞状态。但是这种机制也会导致数据一致性问题,因为,由于网络原因,协调者发送的abort响应没有及时被参与者接收到,那么参与者在等待超时之后执行了commit操作。
1.消息事务+最终一致性
基于消息中间件的两阶段提交往往用在高并发场景下,将一个分布式事务拆成一个消息事务(A系统的本地操作+发消息)+B系统的本地操作,其中B系统的操作由消息驱动,只要消息事务成功,那么A操作一定成功,消息也一定发出来了,这时候B会收到消息去执行本地操作,如果本地操作失败,消息会重投,直到B操作成功,这样就变相地实现了A与B的分布式事务。

虽然上面的方案能够完成A和B的操作,但是A和B并不是严格一致的,而是最终一致的,我们在这里牺牲了一致性,换来了性能的大幅度提升。当然,这种玩法也是有风险的,如果B一直执行不成功,那么一致性会被破坏,需要人工干预,具体要不要玩,还是得看业务能够承担多少风险。
适用于高并发最终一致
2.分布式事务框架-seata
Seata有3个基本组件:
- Transaction Coordinator(TC):事务协调器,维护全局事务的运行状态,负责协调并驱动全局事务的提交或回滚。
- Transaction Manager(TM):事务管理器,控制全局事务的边界,负责开启一个全局事务,并最终发起全局提交或全局回滚的决议。
- Resource Manager(RM):资源管理器,控制分支事务,负责分支注册、状态汇报,并接收事务协调器的指令,驱动分支(本地)事务的提交和回滚。
全局事务与分支事务:

Seata管理分布式事务的典型生命周期:
seata:事务协调器,分支事务都上传协调器,统一决断,AT模式,失败回滚undolog日志,AP一致性要求非常高,牺牲性能,蚂蚁金额这样金额系统
- TM 向 TC 申请开启一个全局事务,全局事务创建成功并生成一个全局唯一的 XID。
- XID 在微服务调用链路的上下文中传播。
- RM 向 TC 注册分支事务,将其纳入 XID 对应全局事务的管辖。
- TM 向 TC 发起针对 XID 的全局提交或回滚决议。
- TC 调度 XID 下管辖的全部分支事务完成提交或回滚请求。
回滚策略:每次分支事务提交都插入操作日志到undolog中,也不锁定数据库资源,如果最后结果时回滚的话,每个微服务依据每个undolog日志回滚自己数据库数据即可
seata支持多种分布式事务解决模式,包括AT、TCC、SAGA、XA等。(XA模式开发中)
AT:两阶段演变,用户无需关心分布式事务的提交与回滚,事务问题交由seata进行管理,实现了无侵入的分布式事务解决方案
一阶段
seata会解析业务SQL,解析找到要更新的业务数据,并保存为前置快照,然后执行业务SQL,并把更新后的数据保存为后置快照(插入日志)。最后生成行锁。以上操作均在同一个数据库事务中保证了原子性。
二阶段
提交:全局事务成功提交则只需要删除快照数据和行锁,完成数据清理
回滚:数据校验,避免出现脏写,然后通过前置快照进行数据还原,最后删除快照信息和行锁,完成数据清理(通过 XID 和 Branch ID 查找到相应的 UNDO LOG 记录)

TCC模式:两阶段补偿方案,对应方法是Try、Confirm及Cancel,需要自己实现接口,对代码的侵入性比较强,同时需要考虑并发控制和异常控制
42.线程池
内置方法
- newSingleTheadPool 单线程池 核心和最大线程都是1,有界队列(阻塞队列LinkedBlockingQueue)
- newFixedTheadPool 多线程池 核心线程和最大线程数是n,有界队列
- newCacheThreadPool 缓存线程池 核心线程为0,最大线程无限大,同步队列(不能存任务),极端情况,一个任务一个线程,不停的创建线程,导致cpu达到100%
推荐:Excutor自定义线程池,依据任务的数量,自定义设置核心线程数,最大线程数,队列大小,非核心线程有效时间,时间单位,拒绝策略
具体核心线程数选择:CPU密集型 和 IO密集型
CPU密集型
任务需要大量的运算,CPU一直全速运行,cpu算力已经达到最大化(通过多线程),此时应该尽可能少的线程数量(减少切换带来消耗),设置线程数 = CPU核数。
// System.out.println(Runtime.getRuntime().availableProcessors());
IO密集型
网络、磁盘 IO (与DB、缓存),任务线程并不是一直在执行任务,大部分时间都在等待IO操作上,此时充分利用cpu资源,使用多线程可以大大的加速程序运行(比如100个线程,50个在等待浪费,还有50个可以有效利用)
- 尽可能多的线程,如CPU核数*2
- 参考公式:CPU核数 /(1 - 阻系数)
比如8核CPU:8/(1 - 0.9)=80个线程数
阻塞系数在0.8~0.9之间
线程增长策略
ThreadPoolExecutor 最全参数的构造方法:
corePoolSize:核心线程数;
maximumPoolSize:线程池的最大线程数;
keepAliveTime:核心线程数之外的线程,最大空闲存活的时长;
unit:keepAliveTime 的时间单位;
workQueue:线程池的任务等待队列;
threadFractory:线程工厂,用来为线程池创建线程;
handler:拒绝策略,当线程池无法处理任务时的拒绝方式;
案例

- 由于队列是阻塞队列并且默认大小是 Integer.MAX_VALUE即无界队列,所以非核心线程可能永远无法用到,这也是为啥线程池默认方法定义核心和最大线程都是同一个值原因
线程池中线程的增长策略相关参数
- corePoolSize:核心线程数
- maximumPoolSize:最大线程数;
- workQueue:等待任务队列;

- 注意只有队列满的时候才会创建非核心线程,但是一个能够满的队列,它的前提是必须是一个有界队列。
- 如果没有配置拒绝策略默认就会抛出RejectedExecutionException 异常
线程回收策略
线程池中线程的收缩策略,和以下几个参数相关:
- corePoolSize:核心线程数;
- maximumPoolSize:线程池的最大线程数;
- keepAliveTime:核心线程数之外的线程,空闲存活的时长;
- unit:keepAliveTime 的时间单位;
当线程数超过核心线程数且处于空闲状态,且空闲时间超过 keepAliveTime&unit 配置的时长,非核心线程会被回收,核心线程不会回收(线程池无法区分哪些线程是核心或非核心线程,他只控制数量达到 corePoolSize数)
核心线程数中的线程,通过 allowCoreThreadTimeOut(true) 方法设置,在核心线程空闲的时候,一旦超过 keepAliveTime&unit 配置的时间,也将其回收掉( keepAliveTime 不能为 0。)。
查缺补漏
等待队列还会影响拒绝策略
如果是无界队列,非核心线程永远用不到,拒绝策略永远不会执行。
工作线程数量达到核心(最大)线程数,等待队列也满了,拒绝策略才能生效。
核心线程数可以被「预热」
线程池中的线程默认是根据任务来增长的,但可以提前准备好线程池的核心线程,来应对突然的高并发任务,例如在抢购系统中就经常有这样的需要。
prestartCoreThread() 或者 prestartAllCoreThreads() 来提前创建核心线程,这种方式被我们称为「预热」。
对于需要无界队列的场景,怎么办?
需求是多变的,我们肯定会碰到需要使用无界队列的场景,那么这种场景下配置的 maximumPoolSize 就是无效的。可以参考 Executors 中 newFixedThreadPool() 创建线程池的过程,将 corePoolSize 和 maximumPoolSize 保持一致即可。
核心线程数=最大线程数,只有增长到这个数量才会将任务放入等待队列,来保证我们配置的线程数量都得到了使用。
线程池是公平的吗?
不公平的。
不提线程池中线程执行任务是通过系统去调度的,这一点就决定了任务的执行顺序是无法保证的,这就是是非公平的。另外只从线程池本身的角度来看,我们只看提交的任务顺序来看,它也是非公平的。
首先前面到的任务,如果线程池的核心线程已经分配出去了,此时这个任务就会进入任务队列,那么如果任务队列满了之后,新到的任务会直接由线程池新创建线程去处理,直到线程数达到最大线程数。
那么此时,任务队列中的任务,虽然先添加进线程池等待处理,但执行任务是,先核心线程任务,然后非核心线程任务,之后才是等待队列中的任务
总结
增长策略。默认情况下,线程池是根据任务先创建足够核心线程数的线程去执行任务,当核心线程满了时将任务放入等待队列。待队列满了的时候,继续创建新线程执行任务直到到达最大线程数停止。再有新任务的话,那就只能执行拒绝策略或是抛出异常。
收缩策略。大于核心线程数 && 当前有空闲线程 && 空闲线程的空闲时间大于 keepAliveTime 时,会对该空闲线程进行回收,直到线程数量等于核心线程数为止。
总之要谨记,慎用无界队列。
提交任务优先级:先核心线程,然后阻塞队列,满了,然后才创建最大线程;
执行任务优先级:先核心线程任务,然后非核心线程任务,之后才是阻塞队列中的任务
扩展
调度线程池

满二叉树,父节点比左右节点小,大
堆适于找最大或者最小值;适于插入或删除重排,所以堆适用于优先队列
四大拒绝策略
- AbortPolicy : 抛出异常
- CallerRunsPolicy : 丢回调用者(不会丢弃任务,性能可能会急剧下)
- DiscardOldestPolicy : 丢给最先执行线程
- DiscardPolicy : 丢弃
springboot中线程池类


-
ThreadPoolTaskExecutor springboot中线程池类
-
queueCapacity:阻塞(缓存)队列 ,设置大小
-
动态调整线程数量:线程池中线程数量超过核心线程数,终止空闲时间超时的线程
扩展
-
ArrayBlockingQueue(有界队列):规定大小的BlockingQueue,其构造必须指定大小。其所含的对象是FIFO顺序排序的,方便查询和更新。
-
LinkedBlockingQueue(无界队列):大小不固定的BlockingQueue,若其构造时指定大小,生成的BlockingQueue有大小限制,不指定大小,其大小有Integer.MAX_VALUE来决定。其所含的对象是FIFO顺序排序的,方便删除和新增。
-
PriorityBlockingQueue(优先队列):类似于LinkedBlockingQueue,但是其所含对象的排序不是FIFO,而是依据对象的自然顺序或者构造函数的Comparator决定。
-
SynchronizedQueue(同步队列):特殊的BlockingQueue,对其的操作必须是放和取交替完成。
-
ArrayBlockingQueue跟LinkedBlockingQueue的区别
-
1.队列中的锁的实现不同
ArrayBlockingQueue中的锁是没有分离的,即生产和消费用的是同一个锁;
LinkedBlockingQueue中的锁是分离的,即生产用的是putLock,消费是takeLock
2.在生产或消费时操作不同
ArrayBlockingQueue基于数组,在生产和消费的时候,是直接将枚举对象插入或移除的,不会产生或销毁任何额外的对象实例;
LinkedBlockingQueue基于链表,在生产和消费的时候,需要把枚举对象转换为Node
进行插入或移除,会生成一个额外的Node对象,这在长时间内需要高效并发地处理大批量数据的系统中,其对于GC的影响还是存在一定的区别。 3.队列大小初始化方式不同
ArrayBlockingQueue是有界的,必须指定队列的大小;
LinkedBlockingQueue是无界的,默认是Integer.MAX_VALUE。可以指定队列大小,从而成为有界的。
注意:
- 在使用LinkedBlockingQueue时,若用默认大小且当生产速度大于消费速度时候,有可能会内存溢出
- 入队操作,LinkedBlockingQueue的消耗更大
并发编程
多线程
互斥 多个线程争抢资源 锁
单机锁 lock.synchronized
分布式锁 redis,zk,resission,mysql
同步 多个线程协同工作 (信号量)
ReetrantLock java层面
synchronized c++ 代码 看不了源码
jclasslib 插件看字节码
方法级:
-
1.static synchronized void count() //静态方法锁这个方法所属的Class对象
-
2.synchronized void count() 非静态方法锁这个方法所属对象
-
字节码结果:其中两个monitorexit相当于

try{
lock.lock();
...
1/0; //防止异常跳出导致未释放锁
...
lock.unlock();
}catch{}finally{
lock.unlock();
}
代码块:
-
3.synchronized(A.class)
-
4.synchronized(new Object)
43.Apache ShardingSphere
https://hucheng.blog.csdn.net/article/details/107528635
ShardingSphere介绍

- 垂直分库和分表,库按业务划分,表按照大字段或非必须字段划分,结构是不一样的
- 水平分库和分表,它们都是按照数据来进行划分,比如1-10000,10001-20000,表结构是一样的,数据不一样
- 集群或读写分离,库,表,数据源都一样
实际应用:
- 数据库设计的时候就考虑垂直分库和垂直分表
- 随着数量增多,先考虑缓存处理,读写分离,索引,如果还不能解决才考虑用水平分库和水平分表
问题:
- 跨节点连接查询问题(分页,查询)
- 多数据源管理问题
Sharding-JDBC
4.0.0版本


- 轻量级java框架,增强的jdbc驱动
- 简化分库分表之后数据相关的操作
水平分表场景
配置Sharding-JDBC 表分片策略



- 数据按照要求进行分片

一个实体类Course对应两张表course_1,course_2,会导致报错,需要设置下

新增和查询(奇数id)都是按照奇偶策略进行的
# 配置真实数据源
spring.shardingsphere.datasource.names=ds0,ds1
# 配置第 1 个数据源
spring.shardingsphere.datasource.ds0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds0.jdbc-url=jdbc:mysql://localhost:3306/ds0
spring.shardingsphere.datasource.ds0.username=root
spring.shardingsphere.datasource.ds0.password=
# 配置第 2 个数据源
spring.shardingsphere.datasource.ds1.type=com.zaxxer.hikari.HikariDataSource ...
# 配置 t_order 表规则
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes
=ds$->{0..1}.t_order$->{0..1}
//t_order表名,ds库名 ds0,ds1 ,t_order0,t_order1
# 配置分库策略
spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-column=user_id
spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-algorithm-name=database_inline
# 配置分表策略
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-column=order_id
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-algorithm-name=table_inline
# 省略配置 t_order_item 表规则...
# ...
# 配置 分片算法
spring.shardingsphere.rules.sharding.sharding-algorithms.database_inline.type=INLINE
spring.shardingsphere.rules.sharding.sharding-algorithms.database_inline.props.algorithm-expression=ds_${user_id % 2}
spring.shardingsphere.rules.sharding.sharding-algorithms.table_inline.type=INLINE
spring.shardingsphere.rules.sharding.sharding-algorithms.table_inline.props.algorithm-expression=t_order_${order_id % 2}
水平分库场景



- 可以设置库中所有表设置满足表分片策略,或指定表分片策略
垂直分库
专库专表


- 解决多数据源问题
- 操作User实体类只访问user库DB
公共表


读写分离
- ShardingJdbc依据sql中insert,update拦截跳转执行主数据库
- 然后主从数据库通过binlog日志实现数据同步

- 配置binlog日志,主从配置等



Sharding-Proxy



-
透明化的数据库代理端(类似mycat),默认3307端口
-
修改文件server.yaml(公共源),config-shading.yaml 分库分表,一库多表


mysql -P3307 -uroot -p //连接到Sharding proxy
- 操作Sharding proxy表,默认数据库中所有表(比如两张表)也修改,方便的实现Sharding proxy分表分库,读写分离等操作
读写分离配置
- 修改conf中config-master-yaml文件修改

分页
水平分表,查询100000之后10条数据
SELECT * FROM t_order ORDER BY id LIMIT 0, 1000010 //原始做法
1.采用流式处理 + 归并排序的方式来避免内存的过量占用。由于SQL改写不可避免的占用了额外的带宽,但并不会导致内存暴涨, 由于每个结果集的记录是有序的,因此ShardingSphere每次比较仅获取各个分片的当前结果集记录 10条 ,驻留在内存中的记录仅为当前路由到的分片的结果集的当前游标指向,即 只有 20条。
对于本身即有序的待排序对象,归并排序的时间复杂度仅为O(n),性能损耗很小。
2.其次,ShardingSphere对仅落至单分片的查询进行进一步优化。 落至单分片查询的请求并不需要改写SQL也可以保证记录的正确性,因此在此种情况下,ShardingSphere并未进行SQL改写,从而达到节省带宽的目的。
3.分页方案优化
由于LIMIT并不能通过索引查询数据,因此如果可以保证ID的连续性,通过ID进行分页是比较好的解决方案:
SELECT * FROM t_order WHERE id > 100000 AND id <= 100010 ORDER BY id
或通过记录上次查询结果的最后一条记录的ID进行下一页的查询:
SELECT * FROM t_order WHERE id > 100000 LIMIT 10
总结
Sharding-Sphere 与mycat区别?
- Sharding proxy相当于一个数据库代理层,它实现了将多个库表整合
- Sharding proxy 水平分表之后数据分片(1-10000,10001-20000...),进行分页查询时,由于设置主键id是自增,

44.布隆过滤器
Redis当中有一种数据结构就是位图,布隆过滤器其中重要的实现就是位图的实现
本质上布隆过滤器是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。

- 查询和插入都是经过多个hash函数,得到的值放到多个bit位
- 设计多个hash函数,bit位置二进制都为1才表示“你好”存在

-
多个数据经过hash值可能都为1,我们无法确定bit=2位置1是表示哪个数据,所以不能进行删除数据,因为比如想删除你好,可能hello的bit也在2,也会被删除
-
优点,计算哈希值,插入二进制数组下标,占用空间非常小(bitmap),查询和插入数据非常快,时间复杂度是O(K),K表示多个hash函数,如果一个hash函数就是O(1)
-
保密性非常好,存储都是二进制数据
-
缺点,无法进行删除操作,存在误判情况,比如你好和hello的hash结果下标都是2,此时只有数组中只有“你好”,但是hello哈希下标也是2,所以会存在误判情况,认为数组中存在“hello”

布隆过滤器的如何删除
如果要删除掉一个元素是不能直接把1改成0的,可能导致误删其他数据,最简单的做法就是加一个计数器,每个位不存在就是0,存在几个元素就存具体的数字如果要存具体的数字比如说2(10),那就需要2位了,所以带有计数器的布隆过滤器会占用更大的空间。
- google Bloom 封装了布隆过滤器,可以设置误判,比如原有1000000个数,在插入100000个数,设置误判率为0.01,查询得出误判率为1031接近0.01,但是如果设置误判率无限小,那么此时运算时间会非常久,性能更差

如果发生过多的哈希碰撞,就会影响到判断的准确性,所以为了减少哈希碰撞,我们一般会综合考虑以下2个因素:
1、增大位图数组的大小(数组越大,占用内存越大)。
2、增加哈希函数的次数(多次hash运算,cpu消耗更多,时间更长)。
误判率原理:
- 误差率越小,占用空间越大,hash函数越多,每个hash函数算法不一样,算出来的hash位置也是不同的,hash函数越多,算出来位置越多,数据不同,但hash值相同的概率就越低,误差率减小,但hash值也增多,那么占用二进制下标也增多,所以内存也会增多
防止缓存穿透:

- 判断key如果存在布隆过滤器中就拦截,否则没有就设置为null
白名单

- (1) key在布隆过滤器白名单才允许通过,所有的参数都需要放入布隆过滤器和redis中
- 缺点:(4) 表示db中也无key,属于布隆过滤器误判,会导致穿透缓存和DB,但是误判概率是非常小的
- 使用场景

黑名单

- 与白名单很相似,差别就是布隆过滤器中存在,直接拦截返回,还有如果redis和db中都不存在,直接加入到布隆过滤器黑名单中
- 缺点:黑名单最开始是没有数据的,只有断定为非法请求key才会存入黑名单中,所以最开始请求key会缓存穿透到DB
- 使用场景

bitmap 位图运算
背景:一个数字,64位机器上,需要8个byte存储,64个bit(进制位),而bitmap上只需要一个bit即可存放
问题:40亿数据中找一个数据,限制在1G内存中
hashmap中运算,一个数字(long,double)类型,对应8个byte,需要32G内存
如果字符串,一个字符一个byte,页需要4G
bitmap 则只需要 0.5G
bitmap := make([]int,40*100000000/64+1)
bitmapIndex = value /64 //数组下标 比如50 ,第0个数组
bitmapOffset = value % 64 //第几个bitmap 下标为50设置为1
bitmap存储在long数组中,数组中每个元素都是64位二进制数组,bitmap子集(word),bitmap最初有4个word,数据增多会扩充,word存储范围是64,超过0—63会放入word1,当word3放满会扩充
详细地址:https://www.sohu.com/a/300039010_114877
45.面试总结
redis缓存穿透 设置null,布隆过滤器?
-
槽:哈希,分布式寻址,每天机器保存一部分槽,找某个key的槽,找到哪台服务器
-
redis线程模型,nio多路复用
-
redis事务命令,不做回滚
-
非关系型数据库 redis
-
微服务答题各个组件,应该依照需求,慢慢推出什么组件
-
项目流程,经验,数据流程,个人难忘的问题处理
-
MySql采用的算法原理
二分查找(binary search)、二叉树查找(binary tree search),b+树查找算法 -
REDIS缓存穿透,大量设置null会有什么问题,布隆过滤器
:最常见的则是采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被 这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。另外也有一个更为简单粗暴的方法(我们采用的就是这种),如果一个查询返回的数据为空(不管是数据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。 -
sleep和wait的区别
1、sleep是Thread的静态方法,wait是Object的方法
2、sleep不会释放锁,只是暂时让出cpu资源,到达时间继续执行; wait会释放锁,但调用它的前提是当前线程占有锁(即代码要在synchronized中),notify唤醒或达到超时时间自动唤醒,并且需要重新获取到对象锁资源后才能继续执行。
3、它们都可以被interrupted方法中断。4 Thread.Sleep(0)的作用,就是触发操作系统立刻重新进行一次CPU竞争,wait(1000)表示将锁释放1000毫秒,设置超时时间自动唤醒,如果没有需要其他线程notify唤醒


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人