python3实战之字幕vtt与字母srt的相互转换
关于
- 0.本文将介绍一个字幕格式vtt与srt相互转换的py脚本。
- 1.代码大部分出自: https://www.cnblogs.com/BigJ/p/vtt_srt.html
- 2.但是自己针对上面的代码做了修改和增加。原始代码不支持批量转换,改为增加支持批量转换:
- 2.1 支持批量转换
- 2.2 还可以继续完善功能,比如用格式:
python3 XXX.py [源文件格式] [源目标文件路径] [目标文件输出路径]
目前还不支持这个格式,后面再做优化。以后再做吧
我的测试环境
- os: ubuntu
Linux xxxx-virtual-machine 5.4.0-47-generic #51-Ubuntu SMP Fri Sep 4 19:50:52 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux
- python3
Python 3.8.2
用法
1. vtt -> srt
找一个适合你的文件夹,下面的这些操作都是基于这个文件夹:
- 1.1 创建目录vtt和srt
- 1.2 将vtt文件放入vtt目录,
- 1.3 创建main.py文件,文件内容最后一个章节的源码 。
- 1.4 将vtt2srt_exec()添加到代码if name == 'main':的下一行
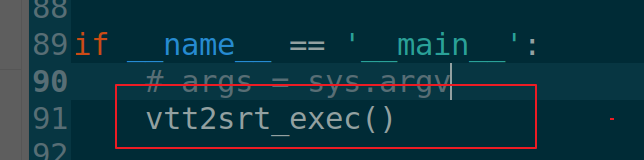
- 1.5 执行代命令
python3 main.py
- 1.6 打开srt目录,查看输出。
2. srt -> vtt
- 用法与 章节1类似。
- 不同的是:
- 1.4步骤替换为:srt2vtt_exec()添加到代码if name == 'main':的下一行 、
- 1.6步骤替换为: 打开vtt目录查看输出。
完整源码
import os
import sys
import re
def get_file_name(dir, file_extension):
f_list = os.listdir(dir)
result_list = []
for file_name in f_list:
if os.path.splitext(file_name)[1] == file_extension:
result_list.append(os.path.join(dir, file_name))
return result_list
def vtt2srt(file_name, output_dir):
content = open(file_name, "r", encoding="utf-8").read()
# 删除WEBVTT行
content = content.replace("WEBVTT", "", 1)
content = content.replace("Kind: captions", "", 1)
content = content.replace("Language: en-GB", "", 1)
# 替换“.”为“,”
content = re.sub("(\d{2}:\d{2}:\d{2}).(\d{3})", lambda m: m.group(1) + ',' + m.group(2), content)
# content = content.replace(",", ".")
output_file = output_dir + file_name[file_name.rfind("/"):]
output_file = os.path.splitext(output_file)[0] + '.srt'
open(output_file, "w", encoding="utf-8").write(content)
def srt2vtt(file_name):
content = open(file_name, "r", encoding="utf-8").read()
# 添加WEBVTT行
content = "WEBVTT\n\n" + content
# 替换“,”为“.”
content = re.sub("(\d{2}:\d{2}:\d{2}),(\d{3})", lambda m: m.group(1) + '.' + m.group(2), content)
# output_file = os.path.splitext(file_name)[0] + '.vtt'
output_file = output_dir + file_name[file_name.rfind("/"):]
output_file = os.path.splitext(output_file)[0] + '.vtt'
open(output_file, "w", encoding="utf-8").write(content)
# to get all .vtt files from cur_path
def file_name(file_dir, file_ext):
L=[]
for root, dirs, files in os.walk(file_dir):
for file in files:
if os.path.splitext(file)[1] == file_ext:
L.append(os.path.join(root, file))
return L
def vtt2srt_exec():
# 1.to get current directory
cur_path = os.getcwd() + "/vtt"
# 2. output folder
output_dir = os.getcwd() + "/srt"
if (False == os.path.exists(output_dir, ".vtt")):
os.mkdir(output_dir)
# 3. to convert
name_list = file_name(cur_path)
for file_vtt in name_list:
vtt2srt(file_vtt, output_dir)
def srt2vtt_exec():
# 1.to get current directory
cur_path = os.getcwd() + "/srt"
# 2. output folder
output_dir = os.getcwd() + "/vtt"
if (False == os.path.exists(output_dir)):
os.mkdir(output_dir)
# 3. to convert
name_list = file_name(cur_path, ".srt")
for file_srt in name_list:
srt2vtt(file_srt, output_dir)
if __name__ == '__main__':
# args = sys.argv
vtt2srt_exec()

