【数据分析师 Level 1 】9.MySQL简介
主流的关系型数据库
-
Oracle :运行稳定,可移植性高,功能齐全,性能超群,适用于大型企业
-
DB2:速度快,可靠性好,适用于海量数据,恢复性极强,适用于大中型企业
-
MySQL:开源、体积小、速度快,适用于中小型企业
-
SQL server
MySQL发展历程
最早是由瑞典MySQL AB公司开发,仅供内部使用,2000年基于GPL协议开放源码,2008年MySQL AB公司被Sun 公司收购,2009年Sun公司又被Oracle公司收购,有了Oracle公司的技术支持,MySQL在2010年以后发布了多个版本,在各方面加强了企业级的特性。
MySQL 下载与安装
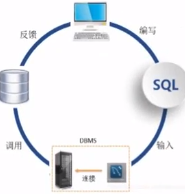
数据库、数据库管理系统和SQL之间的关系
-
数据库是长期存储在计算机内,有组织的,统一管理的相关数据的集合
-
数据库管理系统是用于管理数据库的软件,它对数据库进行统一的管理和控制,以保证数据库的安全性和完整性
-
SQL是一种结构化查询语言(Structure Query Language)它是国际化标准组织(ISO)采纳的标准数据库语言
SQL 分类
-
数据定义语言DDL
-
用来创建、修改、删除数据中的各种对象,包括数据库、表、视图等等
-
用于创建,修改,删除数据库中的各种对象(表、视图、索引等),常用命令有CREATE,ALTER,DROP
-
数据库的增删选查
-
查看数据库:show databases;
-
系统数据库:sys 库:MySQL5.7 增加了 sys 系统数据库,通过这个库可以快速的了解系统的元数据信息。information_schema 库:提供了访问数据库元数据的方式。
-
用户数据库
-
-
创建数据库:create database 数据库名称; 数据库名称不能与SQL关键字相同,也不能重复
-
查看创建好的数据库:show create database 数据库名称; alter database test character set utf8;
-
选择进入数据库:use 数据库名称; use test;
-
删除数据库:drop database 数据库名称; drop database test;
-
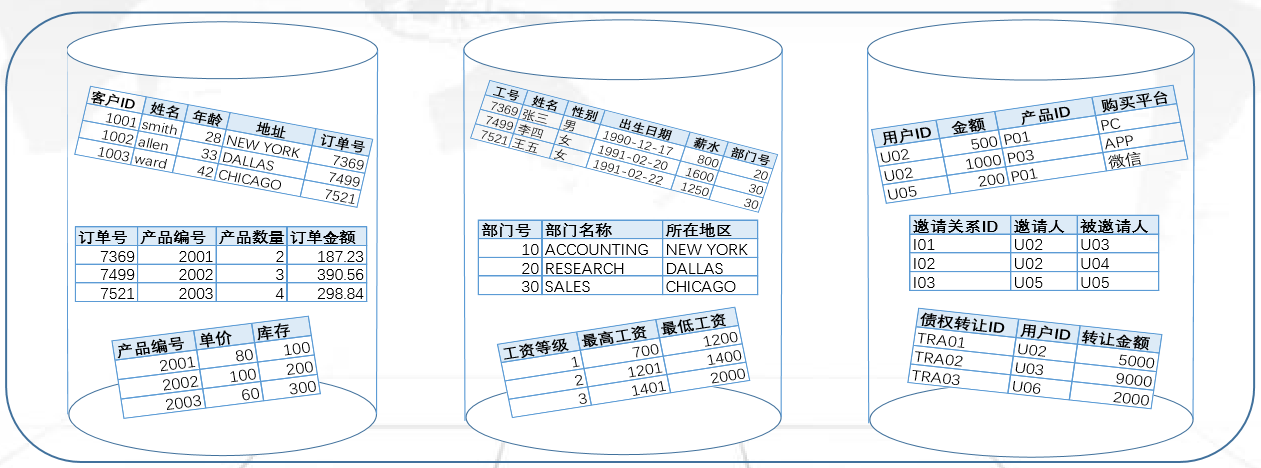
数据库基本结构:
-
-
数据库:组织、存储和管理相关数据的集合,同一个数据库管理系统中数据库名必须唯一
-
表:由固定列数和任意行数构成的数据集,同一个数据库中表名必须唯一
-
列:一个字段,同一个表中列名必须唯一
-
行:一条记录
-
-
-
数据表的增删改查
-
创建表:create table 表名(字段名1 数据类型1 [约束条件1],字段名2 数据类型2
-
建表之前要先选择进入数据库:use test;
-
建表时可以不指定约束条件,但是必须指定字段的数据类型
-
表名不能与SQL关键字相同,同一个数据库下的表名不能重复
-
-
查看创建好的表: show create table 表名; show create table emp;
-
查看当前数据库中所有表: show tables;
-
查看表结构:desc 表名; desc emp;
-
修改表:修改数据库中已经存在的数据表的结构
-
修改表名:alter table 原表名 rename 新表名;
-
修改字段名:alter table 表名 change 原字段名 新字段名 数据类型[ 约束条件];
-
修改字段类型:alter table 表名 modify 字段名 数据类型[ 约束条件];
-
添加字段:alter table 表名 add 新字段名 数据类型
-
修改字段的排列位置
-
将某个字段改为第一列:alter table 表名 modify 字段名 数据类型[ 约束条件] first;
-
将某个字段改到另一个字段后面:alter table 表名 modify 要排序的字段名 数据类型[ 约束条件] after 参照字段;
-
-
删除字段:alter table 表名 drop 字段名;
-
删除数据表: drop table 表名; drop table emp;
-
-
-
数据类型
-
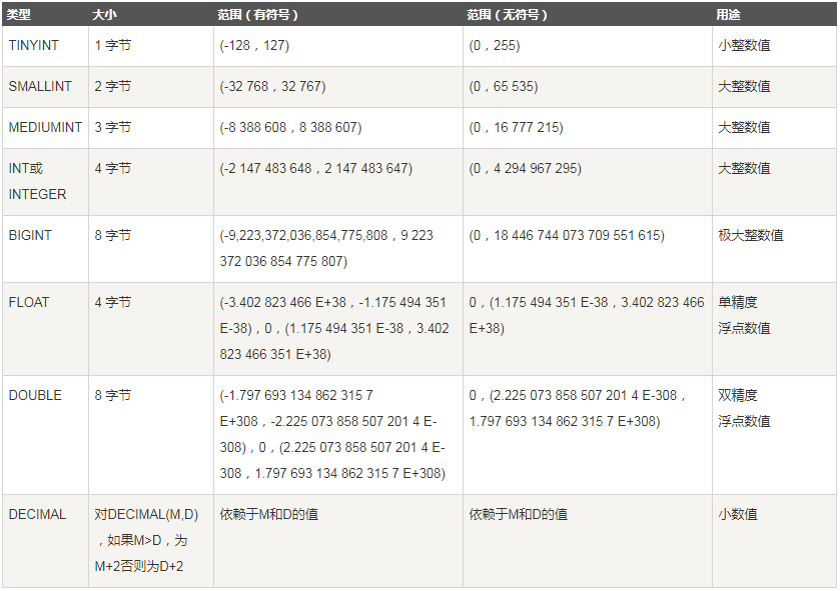
数值型
-
-
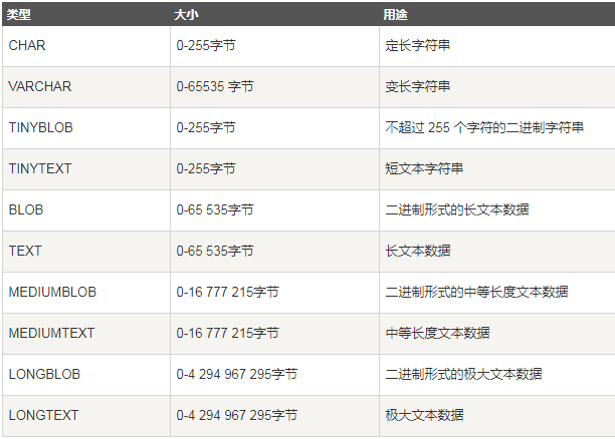
字符串型
-
-
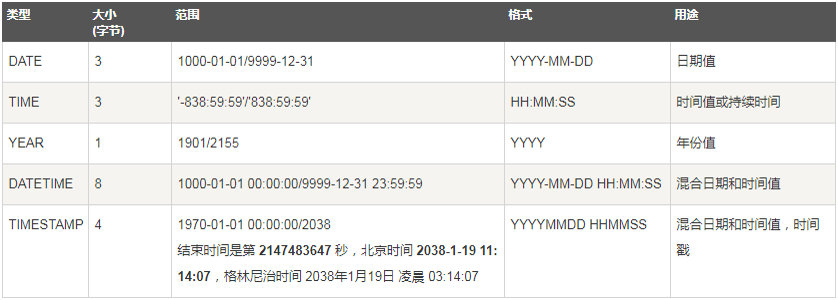
日期时间型
-
-
常用数据类型
-
字符串类型和日期时间类型都需要用引号括起来
-
int:4字节整数值
-
float:单精度浮点型,float(5,2)表示最多5位数,其中有两位小数
-
char:固定长度字符串型,如char(10),‘abc ’
-
varchar:可变长度字符串型,如varchar(10),‘abc’
-
text:长文本字符串型
-
date:日期型,‘yyyy-MM-dd’
-
time:时间型,‘hh:mm:ss’
-
datetime:日期时间型,‘yyyy-MM-dd hh:mm:ss’
-
-
-
数据完整性
-
主体完整性
-
主键约束
-
特点
-
能够唯一地标识表中的一条记录
-
非空不重复,要求主键列的数据必须是唯一的,并且不允许为空
-
可以设置单字段主键,也可以设置多字段联合主键
-
-
添加方法
-
create table 表名(字段1 数据类型 primary key,字段2 数据类型[,…]);
-
create table 表名(字段1 数据类型,字段2 数据类型[,…], primary key(主键字段));
-
create table 表名(字段1 数据类型,字段2 数据类型[,…], primary key(主键字段1, 主键字段2[,…]));
-
-
删除方法
-
alter table 表名 drop primary key;
-
-
-
唯一约束
-
特点
-
要求该列的值必须是唯一的
-
允许为空,但只能出现一个空值
-
-
添加方法
-
create table 表名(字段1 数据类型,字段2 数据类型 unique[,…]);
-
-
删除方法
-
alter table 表名 drop index 唯一约束名;
-
如果单个字段没有指定唯一约束名,则默认的唯一约束名为字段名。
-
如果是多个字段组合为唯一约束时候,默认的唯一约束名为第一个字段的名称。
-
如果指定了约束名,则删除的时候写约束名。
-
-
-
自增字段
-
特点
-
指定字段的数据自动增长
-
配合主键一起使用,并且只适用于整数类型
-
默认从1开始,每增加一条记录,该字段的值会增加1
-
-
添加方法
-
create table 表名(字段1 数据类型 primary key auto_increment,字段2 数据类型[,…]);
-
-
设置自增字段的初始值
-
设置自增字段的初始值:Alter table 表名 auto_increment=n;
-
-
删除方法
-
alter table 表名 modify 字段名 数据类型[ 约束条件];
-
-
-
-
域完整性
-
非空约束
-
特点
-
字段的值不能为空
-
-
添加方法
-
create table 表名(字段1 数据类型,字段2 数据类型 not null[,…]);
-
-
删除方法
-
alter table 表名 modify 字段名 数据类型[ 约束条件];
-
-
-
默认约束
-
特点
-
指定某个字段的默认值,如果新插入一条记录时没有为默认约束字段赋值,那么系统就会自动为这个字段赋值为默认约束设定的值。
-
-
添加方法
-
create table 表名(字段1 数据类型1,字段2 数据类型2 default 默认值[ ,…]);
-
-
删除方法
-
alter table 表名 modify 字段名 数据类型[ 约束条件] ;
-
-
-
-
参照完整性
-
外键约束
-
特点
-
某一表中某字段的值依赖于另一张表中某字段的值
-
主键所在的表为主表,外键所在的表为从表
-
每一个外键值必须与另一个表中的主键值相对应
-
-
添加方法
-
先创建主键所在的主表,再创建外键所在的从表
-
creat table 表名(字段名1 数据类型1,字段名2 数据类型2
-
-
删除方法
-
alter table 表名 drop foreign key 外键约束名;
-
先删除从表,再删除主表。
-
先删除外键约束,再删除表。
-
-
-
-
用户自定义完整性
-
检查约束
-
特点:指定需要检查的限定条件
-
-
-
-
视图
-
视图是存储在数据库中的虚拟表,视图中不保存数据,内部封装了一条SELECT语句,数据来源于查询的一个或多个基本表。
-
创建视图:create view 视图名 as select 查询语句;
-
查看视图结构:desc 视图名;
-
查询视图中的记录:select 字段名1[,字段名2,...] from 视图名[ where 筛选条件];
-
修改视图:create [or replace or alter] view 视图名 as select 查询语句;
-
删除视图:drop view 视图名;
-
-
索引
-
索引的意义
-
用于快速找出在某个字段中有特定值的行。
-
如果不使用索引,MySQL必须从第一条记录开始检索表中的每一条记录,直到找出相关的行,那么表越大,查询数据所花费的时间就越多。
-
-
索引的优缺点
-
优点
-
通过索引对数据进行检索,大大提高了数据的查询效率
-
-
缺点
-
创建索引和维护索引要耗费时间,并且随着数据量的增加所耗费的时间也会增加
-
索引也需要占空间的,创建的索引太多,索引文件也会占用数据库的存储空间
-
当对表中的数据进行增加、删除、修改时,索引也需要动态的维护,降低了数据的维护速度
-
-
-
索引的分类
-
普通索引
-
一个索引只包含一个字段
-
-
唯一索引
-
索引字段的取值不能重复,可以有空值,但空值也只能出现一次
-
-
主键索引
-
索引字段的取值不能为空,也不能重复
-
-
组合索引
-
一个索引包含多个字段
-
只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用
-
-
全文索引
-
仅限MyISAM引擎,只能在CHAR,VARCHAR,TEXT类型的字段上使用
-
通过关键字符,就能找到该字段所属的记录行
-
-
空间索引
-
仅限MyISAM引擎
-
对空间数据类型的字段建立的索引,且要求索引字段的取值不能为空
-
-
-
索引的操作
-
创建索引:create index 索引名 on 表名(字段名);
-
自动创建索引
-
在表中定义了主键约束时,会自动创建一个对应的主键索引
-
在表中定义了外键约束时,会自动创建一个对应的普通索引
-
在表中定义了唯一约束时,会自动创建一个对应的唯一索引
-
-
查看索引:show index from 表名;
-
删除索引:drop index 索引名 on 表名;
-
创建索引的原则
-
需要创建索引的情况
-
主外键和唯一约束的字段自动创建索引
-
频繁作为查询条件的字段应该创建索引
-
查询中排序的字段应该创建索引
-
查询中分组或统计的字段应该创建索引
-
-
不需要创建索引的情况
-
表中记录太少不需要创建索引
-
需要频繁增删改的字段不适合创建索引
-
where子句中用不到的字段不需要创建索引
-
重复值较多的字段不需要创建索引
-
-
-
-
-
-
数据操作语言DML
-
用来对数据库中的表进行更改操作,比如增加数据、删除数据、修改数据等
-
添加数据
-
字段名与字段值的数据类型、个数、顺序必须一一对应
-
指定字段名插入:insert into 表名(字段1[,字段2,…]) values(字段值1[,字段值2,…]), (字段值1[,字段值2,…])[,…]);
-
字段列的数量和值的数量必须相同,且列和值要对应上
-
不指定字段名插入:insert into 表名 values(字段值1[,字段值2,…]), (字段值1[,字段值2,…])[,…]);
-
需要为表的每一个字段指定值,并且值的顺序必须和数据表中字段定义时的顺序相同
-
批量导入:load data infile ‘文件路径.csv’into table 表名 fields terminated by ‘,' ignore 1 lines;
-
路径中不能有中文,并且要用反斜杠
-
-
更新数据
-
update 表名 set 字段名1=字段值1
-
设置数据库安全权限: set sqlsafeupdates=0;
-
-
删除数据
-
delete from 表名[ where 条件字段=条件值];
-
truncate 表名;
-
delete和truncate区别
-
delete可以添加删除条件删除表中部分数据,truncate只能删除表中全部数据。
-
delete删除表中数据保留表结构,truncate直接把表删除(drop)然后再创建一张新表,执行速度比delete快。
-
-
-
-
数据查询语言DQL
-
用来查询数据库表中的记录,由select 组成的查询语句块
-
用来查询数据库表中的记录,基本结构:SELECT <字段名> FROM <表或视图名> WHERE <查询条件>
-
单表查询
-
虚拟结果集
-
select语句执行后服务器会按照要求检索表中数据,并将检索结果发送到客户端,这个以表的形式展示出来的临时结果集,
-
它是存放在内存中,不是在磁盘中的,执行其他操作之后这个结果集就没有了,所以它是临时存在的虚拟结果集,而不是一个真实的表。
-
-
全表查询
-
全表查询:select * from 表名;
-
-
查询指定列
-
查询指定列:select 字段1[,字段2,…] from 表名;
-
-
查询不重复的数据
-
查询不重复的数据:select distinct 字段名 from 表名;
-
-
设置别名
-
当我们的列名或表名很长的时候,可以使用as关键字给一个列或者表添加别名,增强SQL语句的可读性。
-
设置别名:select 字段名 as 列别名 from 原表名 [as ]表别名;
-
-
条件查询
-
条件查询:select 字段1[,字段2,…] from 表名 where 筛选条件;
-
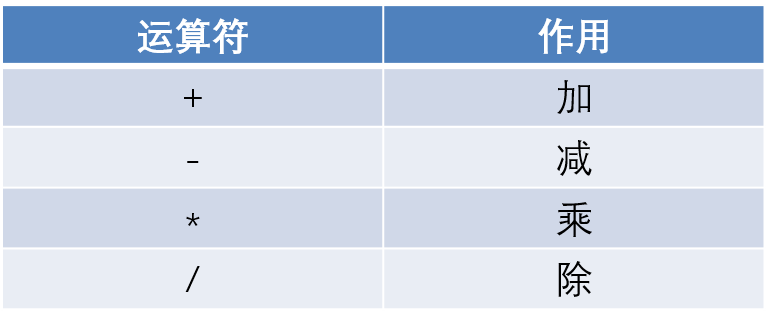
运算符
-
算术运算符
-
-
比较运算符
-

-
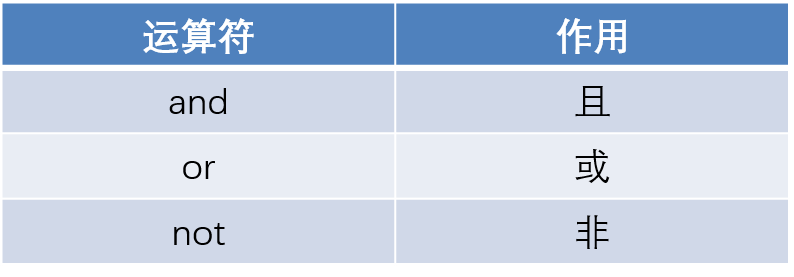
逻辑运算符
-
-
-
-
空值查询
-
空值查询:select 字段1[,字段2,…] from 表名 where 空值字段 is[ not] null;
-
-
模糊查询
-
模糊查询:select 字段1[,字段2,…] from 表名 where 字符串字段[ not] like 通配符;
-
百分号(%)通配符:匹配0个或多个字符
-
下划线(_)通配符:匹配一个字符
-
-
-
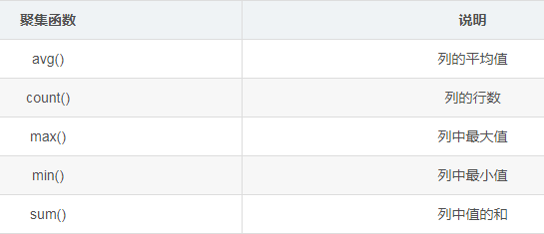
聚合运算
-
聚合运算:将多行数据进行聚集计算为一行
-
聚合函数会对null以外的数据进行聚合运算
-
-
-
-
分组查询
-
分组后筛选
-
查询结果排序
-
限制查询结果数量
-
select语句书写顺序
-
select语句执行顺序
-
-
多表查询
-
连接查询
-
表之间关系
-
一对一
-
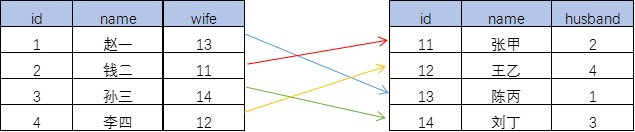
-
一对多
-
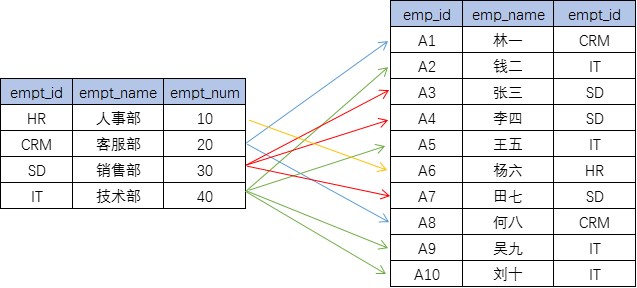
-
多对多
-
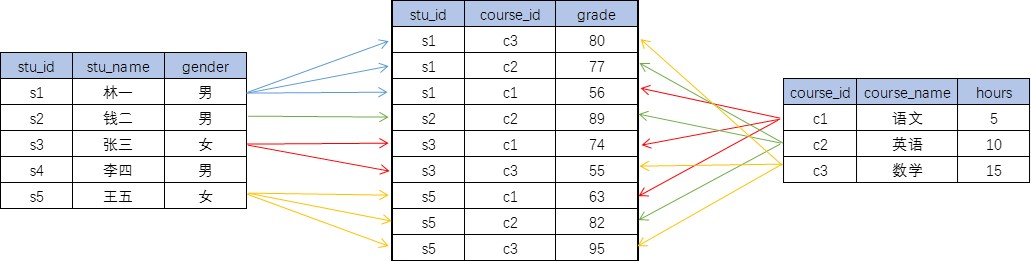
-
-
连接方式
-
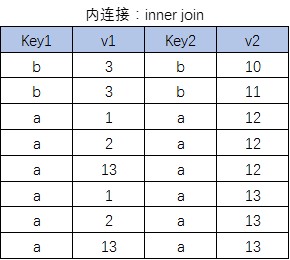
内连接
-
按照连接条件连接两个表,返回满足条件的行
-
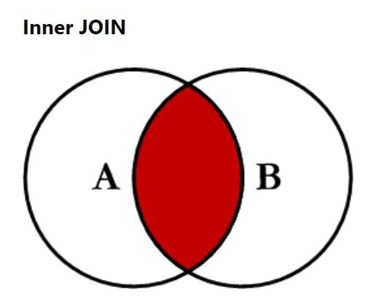
-
select 字段1[,…] from 表1[ inner] join 表2 on 连接条件;
-
-
-
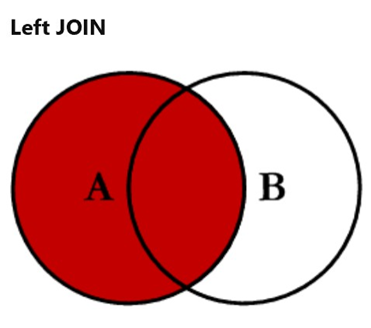
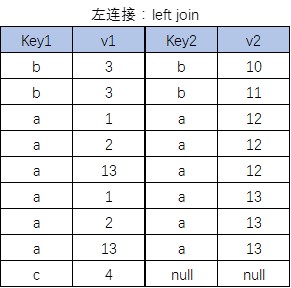
左连接
-
结果中除了包括满足连接条件的行外,还包括左表的所有行
-
-
select 字段1[,…] from 表1 left join 表2 on 连接条件;
-
-
-
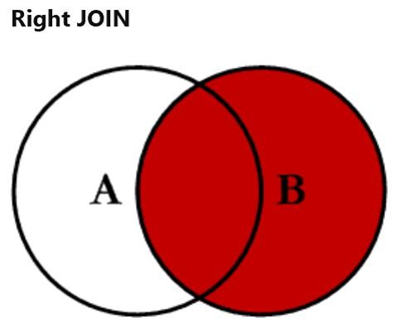
右连接
-
结果中除了包括满足连接条件的行外,还包括右表的所有行
-
-
select 字段1[,…] from 表1 right join 表2 on 连接条件;
-
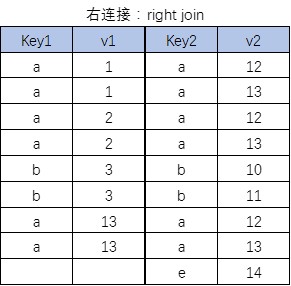
-
-
笛卡尔积
-
假设集合A={a,b},集合B={1,2,3},则两个集合的笛卡尔积为{(a,1),(a,2),(a,3),(b,1),(b,2),(b,3)}
-
select 字段1[,…] from 表1,表2[,…];
-
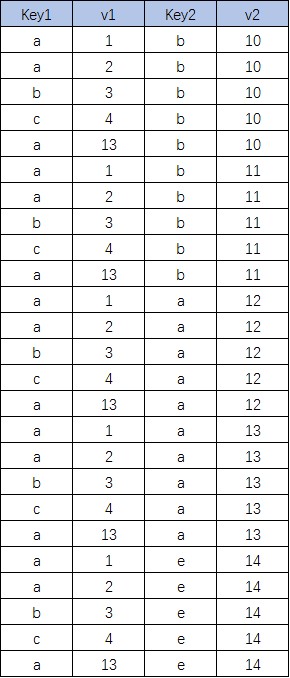
-
消除笛卡尔积:select 字段1[,…] from 表1,表2[,…] where 筛选条件;
-
逐行判断,相等的留下,不相等的排除
-
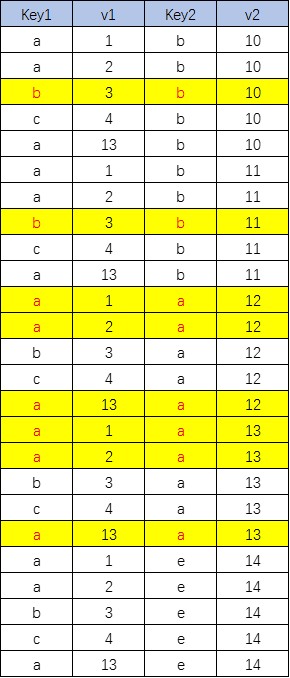
-
消除笛卡尔积
-
-
-
自连接
-
-
连接条件
-
等值连接
-
通过设置表别名,将同一张表虚拟为多张表进行连接
-
表1.key=表2.key
-
-
不等值连接
-
表1.key 比较 表2.key
-
-
-
-
合并查询
-
把多条select语句的查询结果合并为一个结果集
-
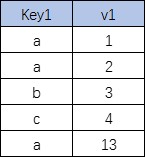
-
被合并的结果集的列数、顺序和数据类型必须完全一致
-
union去重:select 字段1[,字段2,…] from 表名 union select 字段1[,字段2,…] from 表名; select * from t1 union select * from t2;
-

-
union all不去重: select 字段1[,字段2,…] from 表名 union all select 字段1[,字段2,…] from 表名; select * from t1 union all select * from t2;

-
-
-
子查询
-
一个select语句中包含另一个或多个完整的select语句
-
子查询分类
-
标量子查询:返回的结果是一个数据(单行单列)
-
行子查询:返回的结果是一行(单行多列)
-
列子查询:返回的结果是一列(多行单列)
-
表子查询:返回的结果是一张临时表(多行多列)
-
-
子查询常用操作符
-
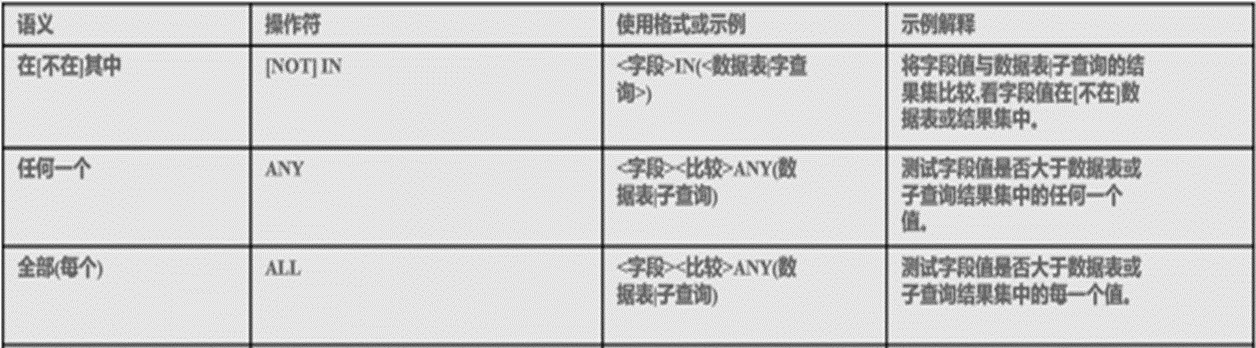
-
-
常用函数
-
字符串函数
-
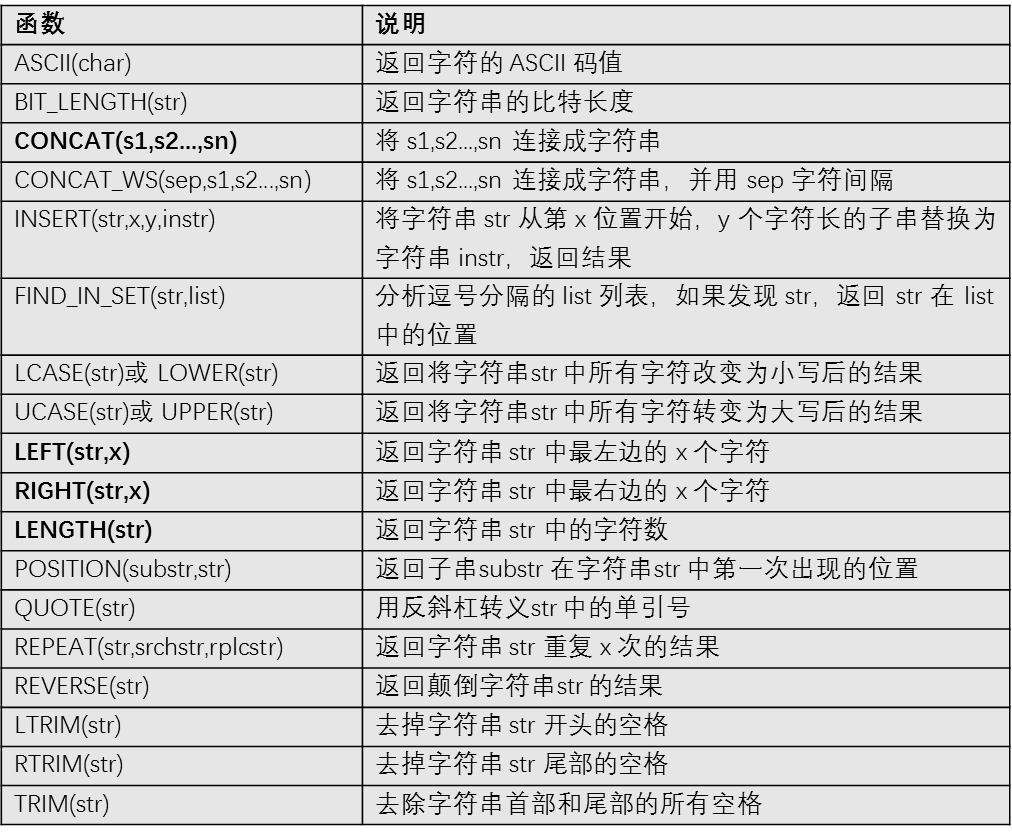
-
数字函数
-
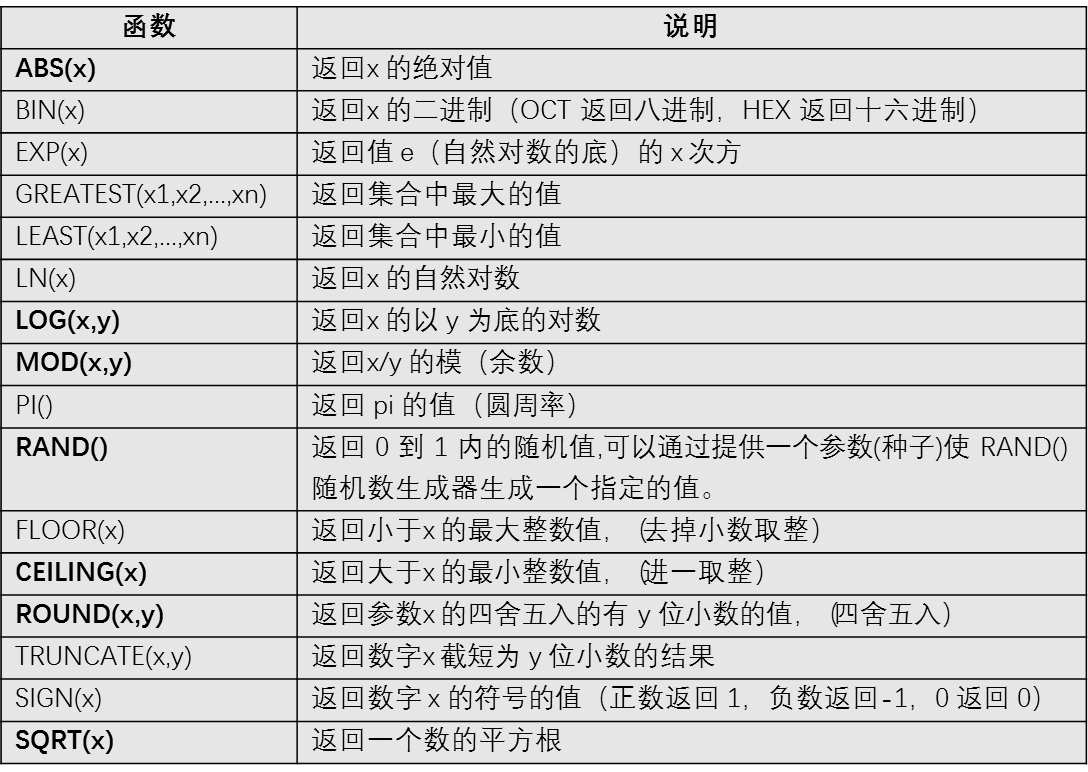
-
日期时间函数
-
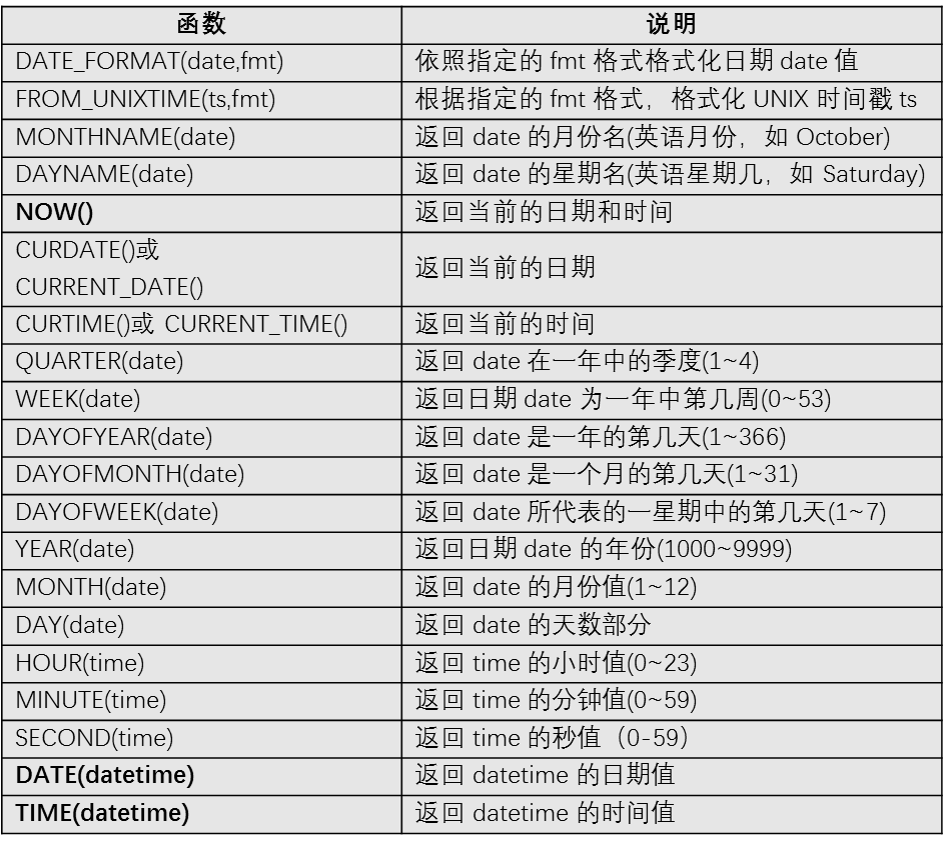
-
开窗函数
-
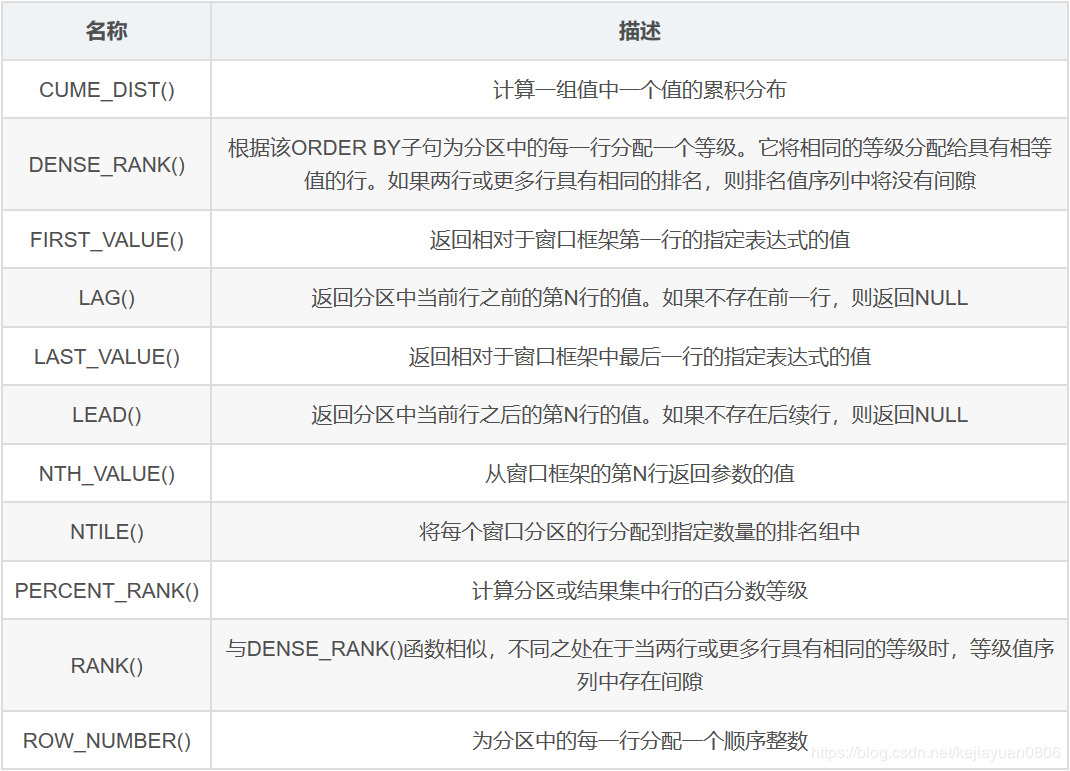
-
-
查询结果保存
-
保存到一个新的表:create table 新表名 as select 查询语句;
-
保存为外部文件:select 查询语句 into outfile 保存路径;
-
-
-
-
数据控制语言DCL
-
用来定义数据库的访问权限和安全级别
用来定义数据库访问权限和安全级别,常用命令:GRANT,REVOKE
-
SQL 书写要求
SQL语句可以单行或多行书写,用分号结尾。
SQL关键字用空格分隔,也可以用缩进来增强语句的可读性。
SQL对大小写不敏感。
用#或-- 单行注释,用/* */多行注释,注释语句不可执行。
MySQL 客户端常用工具
-
MySQLd
-
MySQL 服务核心进程。在 linux 环境下,启动时会被 MySQLd_safe 调用。只有它成功启动, 数据库实例才能正常运作。
-
-
MySQLd_safe
-
MySQL 实例的安全启动脚本,在 unix 和 netware 中推荐使用 MySQLd_safe 来启动
-
MySQLd 服务器。MySQLd_safe 增加了一些安全特性,例如当出现错误时重启服务器并向错误日志文件写入运行时间信息。它是 MySQLd 的守护进程。
-
-
命令行(CMD)
-
图形化工具(IDE)
-
MySQL workbench
-
Navicat
-
SQLyog
-
修改密码
存储引擎
-
InnoDB:事务型数据库的首选引擎,也是MySQL的默认事务型引擎,支持事务安全表(ACID),支持行锁定和外键
-
使用场景:由于其支持事务处理、外键、支持崩溃修复能力和并发控制。
-
如果需要对事务的完整性要求比较高(比如银行),要求实现并发控制(比如售票),那选择InnoDB有很大的优势。
-
如果需要频繁的更新、删除操作的数据库,也可以选择InnoDB,因为支持事务的提交(commit)和回滚(rollback)。
-
-
MyISAM:在Web,数据仓储和其他应用环境下最常使用的存储引擎之一,拥有较高的插入、查询速度,但是不支持事务和外键
-
使用场景:如果表主要是用于插入新记录和读出记录,那么选择MyISAM能实现处理高效率。
-
-
MEMORY:将表中的数据存储到内存中,未查询和引用其他表数据提供快速访问
-
使用场景:如果需要该数据库中一个用于查询的临时表。
-
-
ARCHIVE:仅仅支持最基本的插入和查询,它使用zilib压缩率,在记录被请求时会实时压缩,所以它经常被用来当做仓库使用
-
使用场景:由于高压缩和快速插入的特点Archive非常适合作为日志表的存储引擎,但是前提是不经常对该表进行查询操作。
-

posted on 2020-12-04 15:51 pandaboy1123 阅读(130) 评论(0) 编辑 收藏 举报


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
2019-12-04 CDA 数据分析师 level1 part 4
2019-12-04 CDA 数据分析师 level1 part 3