【数据分析师 Level 1 】7.机器学习的基本概念
1.什么是机器学习
-
机器学习研究如何让计算机不需要明确的程序也能具备学习能力(——Arthur Samuel 1959)
-
一个计算机程序在完成了任务T之后,获得经验E,其表现效果为P,如果任务T的性能表现,也就是以衡量的P,随着E的增加而增加,可以称其为学习(——Tom Mitchell 1977)
虽然机器学习的研究来源于人工智能领域,但是机器学习的方法却应用于数据科学领域,因此,我们将机器学习看作是一种数学建模更合适
机器学习的本质就是借助数学模型理解数据。当我们给模型装上可以适应观测数据的可调参数时,“学习”就开始了,此时的程序被认为具有从数据中“学习”的能力,一旦模型可以拟合旧的观测数据,那么它们就可以预测并解释新的观测数据。

2.模型构建流程
第一步:获取数据
既然我们机器学习是借助数学模型理解数学,那么最重要的原材料就是数据了。获取数据通常指的是获取原始数据,当然这里可以是一手数据,也可以是二手数据,关键看机器学习的学习任务。
“数据决定机器学习结果的上限,而算法只是尽可能的逼近这个上限”,可见数据在机器学习中的作用。那么一般而言对于数据我们有哪些要求呢?
-
数据要有代表性,数据需要包含尽可能多的信息,数据也需要同学习任务有关联性
-
对于监督学习中的分类问题,数据偏斜不能过于严重,不同类别的数据数量不要有数个数量级的差距。
-
需要评估数据样本的量级,估算模型学习对内存的消耗,如果数据量太大可以考虑减少训练样本、降维或者使用分布式机器学习系统。


第二步:获取一个任务
这一步可以同第一步互换顺序,根据实际业务需求,可能会先拿到任务,在寻找合适的数据。
在获取任务之后,需要将任务问题抽象成数学问题,明确我们可以获得什么样的数据,学习的目标是一个什么类型的问题,然后划归为其中的某类问题,比如分类问题、回归问题、聚类问题、降维问题等


第三步:根据数据和算法进行学习
这一部分包含了数据清洗、数据预处理、特征工程三大板块的内容,我们依次来做展开


数据清洗
数据清洗一般根据具体学习任务或者模型需求而有不同的操作方法,因而难以归纳统一的方法和步骤,但是根据数据不同可以给出下面常用的数据清洗方法。
-
缺失值处理
-
大多数情况下,缺失值需要手工填入(即手工清理)。当然,某些缺失值可以从本数据源或其他数据源推导出来,这就可以用平均值、最大值、最小值或更为复杂的概率估计代替缺失的值,从而达到清理的目的
-
-
异常值检测及处理
-
用统计分析的方法识别可能的错误值或异常值,如偏差分析、识别不遵守分布的值,通过常识性规则、业务特定规则等检查数据值
-
-
重复值检测及消除方法
-
数据中属性值相同的记录被认为是重复记录,通过判断记录间的属性值是否相等来检测记录是否相等,相等的记录合并为一条记录(即合并/清除),合并/消除是消重的基本方法
-
数据预处理
这里数据预处理不单单是处理我们不一致、错误或者异常的数据,更重要的是保证数据能正常传入模型中进行学习,并达到预期的效果
预处理的方法涉及很多内容,比如归一化、标准化、连续数值型变量分箱、有序分类变量One-Hot编码、字符型变量数值化等等
特征工程
特征工程包括从原始数据中特征构建、特征提取、特征选择。特征工程做的好能发挥原始数据的最大效力,往往能够使得算法的效果和新功能得到显著的提升,有时能使简单的模型效果比复杂的模型效果好。数据挖掘的大部分时间就花在特征工程上面,是机器学习非常基础而又必备的步骤。
第四步:模型评估
模型效果
使用机器学习进行判断/预测的效果,如果不能接近/超过人类,那就没有意义。
如果人脸识别不能达到几乎100%准确,根本不可能使用人脸识别代替人工检查,所以追求模型预测准确是机器学习的核心目标

运算速度
能够同时处理大量数据,可以在超短时间内极速学习,是机器学习的重要优势,如果机器学习的判断速度不能接近/超越人类,那计算机的判断的优越性就几乎不存在了
模型效果与运算速度往往是此消彼长的,在模型效果不错的情况下保障运算速度较快,是机器学习中重要的一环。
可解释性
机器学习是一门技术,所以大众注定不太能短时间内熟悉它,但是技术人员肩负向老板、客户、同事,甚至朋友解释机器学习在做什么的职责
比如说,在“是否分发信用卡”的问题中,如果算法判断“这个人有违约风险,不发信用卡”,那客户很可能要上门来要解释,这个时候,你能说是“算法判断不通过么”
在解释性需求很强的领域,我们就需要可解释的算法
服务于业务
所有的一切,就是为了服务于业务
只有模型效果优秀,运算速度快,还带有一部分可解释性的算法才是最优秀的算法
3.交叉验证
说到交叉验证不得不提到模型的[泛化能力],而泛化能力涉及了[训练误差]和[测试误差]两个概念
训练误差与测试误差
我们在进行学习算法前,通常会将一个样本集分成训练集(training set)和测试集(testing set),其中训练集用于模型的学习或训练,而后测试集通常用于评估训练好的模型对于数据的预测性能评估。
-
训练误差(training error)代表模型在训练集上的错分样本比率
-
测试误差(empirical error)是模型在测试集上的错分样本比率
泛化能力
训练误差的大小,用来判断给定问题是不是一个容易学习的问题,测试误差则反映了模型对未知数据的预测能力,测试误差小的学习方法具有很好的预测能力,如果得到的训练集和测试集的数据没有交集,通常将此预测能力称为泛化能力(generalization ability)
那么什么是交叉验证呢?
在业务当中,我们的训练数据往往是已有的历史数据,但我们的测试数据却是新进入系统的一系列还没有标签的未知数据。我们的确追求模型的效果,但我们追求的是模型在未知数据集上的效果,在陌生数据集上表现优秀的能力称为泛化能力,即我们追求的是模型的泛化能力
我们认为,如果模型在一套训练集和数据集上表现优秀,那说明不了问题,只有在众多不同的训练集和测试集上都表现优秀,模型才是一个稳定的模型,模型才具有真正意义上的泛化能力。为此,机器学习领域有着发挥神奇作用的技能:【交叉验证】,来帮助我们认识模型

交叉验证的常用方法
交叉验证方法有很多,其中最常用的是k折交叉验证。我们知道训练集和测试集的划分会干扰模型的结果,因此用交叉验证n次的结果求出的均值,是对模型效果的一个更好的度量

4.模型评估
混淆矩阵

混淆矩阵是二分类问题的多维衡量指标体系,在样本不平衡时极其有用。在混淆矩阵中,我们将少数类认为是正例,多数类认为是负例。在决策树,随即森林这些普通的分类算法里,即是说少数类1,多数类是0.普通的混淆矩阵,一般使用(0,1)来表示。混淆矩阵正如其名,十分容易让人混淆,在许多教材中,混淆矩阵中各种各样的名称和定义让大家难以理解难以记忆。这里找出一种简化的方式来显示标准二分类的混淆矩阵。

模型整体效果:准确率
准确率Accuracy就是所有预测正确的所有样本除以总样本,通常来说越接近1越好

捕捉少数类的艺术:精确度,召回率和 F 1 score
精确度Precision 又叫查准率:表示所有被我们预测为是少数类的样本中,真正的少数类所占的比例。精确度越低,则代表我们误伤了过多的多数类。精确度是“将多数类判错后所需付出成本”的衡量
通常做了样本平衡后,精确度是下降的。因为很明显,样本平衡之后,有更多的多数类被我们误伤了,精确度可以帮助我们判断,是否每一次对少数类的预测都精确,所以又被称为“查准率”。在现实的样本不平衡例子中,当每一次将多数类判断错误的成本非常高昂的时候(比如大众召回车辆的例子),我们会追求高精度。精确度越低,我们对多数类的判断就会越错误。当然了,如果我们的目标是不计一切代价捕获少数类,那我们并不在意精确度。

召回率Recall,又称为敏感度(sensitivity),真正率,查全率表示所有真实为1的样本中,被我们预测正确的样本所占的比例。召回率越高,代表我们尽量捕捉了越多的少数类,召回率越低,代表我们没有捕捉足够的少数类
召回率可以帮助我们判断,我们是否捕捉了全部的少数类,所以又叫做查全率
如果我们希望不计一切代价,找出少数类(不如找出潜在犯罪者的例子),那我们就会追求高召回率,相反如果我们的目标不是尽量捕捉少数类,那我们就不需要在意召回率
注意召回率和精确度的分子式相同的(都是11),只是分母不同,而召回率和精确度是此消彼长的,两者之间的平衡代表了捕捉少数类的需求和尽量不要误伤多数类的需求的平衡。究竟要偏向于那一方,取决于我们的业务需求:究竟是误伤多数类的成本更高,还是无法捕捉少数类的代价更高

为了同时兼顾精确度和召回率,我们创造了两者的调和平均数作为考量两者平衡的综合性指标,称之为F 1 measure。两个数之间的调和平均倾向于靠近两个数中比较小的那个数,因此我们追求尽量高的 F 1 measure,能够保证我们的精确度和召回率都比较高,F 1 measure 在[0,1]之间分布,越接近1越好
5.机器学习的分类
有监督学习
指对数据的若干特征与若干标签(类型)之间的关联性进行建模的过程;只要模型被确定,就可以应用到新的未知数据上,这类学习过程可以进一步分为[分类](classification)任务和[回归](regression)任务。在分类任务中,标签都是离散值;而在回归任务中,标签都是连续值。

无监督学习
指对不带任何标签的数据特征进行建模,通常被看成是一种“让数据自己介绍自己”的过程。这类模型包括[聚类](clustering)任务和[降维](dimensionality reduction)任务。聚类算法可以将数据分成不同的组别,而降维算法追求用更简洁的方式表现数据。

半监督学习
另外,还有一种半监督学习(semi-supervised learning),介于有监督学习和无监督学习之间,通常可以在数据不完整的时候使用。
强化学习
强化学习不同于监督学习,它将学习看作是试探评价过程,以“试错”的方式进行学习,并与环境进行交互已获得奖惩指导行为,以其作为评价。此时系统靠自身的状态和动作进行学习,从而改动行动方案以适应环境。

6.常用有监督学习算法
1.KNN算法
一则小故事
在一个酒吧里,吧台上摆着十杯几乎一样的红酒,老板跟你打趣说想不想来玩个游戏,赢了免费喝酒,输了付3倍酒钱,那么赢的概率是多少?
你是个爱冒险的人,果断说玩
老板接着说:你眼前的这十杯红酒,每杯略不相同,前五杯属于【赤霞珠】,后五杯属于【黑皮诺】。现在,我重新倒一杯酒,你需要正确地告诉我他属于哪一类
听完你有点心虚,因为你根本不懂酒,光靠看和尝分辨不出来,不过自己是搞机器学习的,不由多了几分底气,爽快的答应了老板
你没有急着品酒,而是问了老板每杯酒的一些具体信息:酒精浓度、颜色深度等,以及一份纸笔。老板一边倒一杯新酒,你边疯狂打草稿。

很快,你告诉老板这杯新酒是【赤霞珠】
老板瞪大了眼睛,从来没有人一口酒都不尝就能答对,无数人都是反复尝来尝去,最后以犹豫不定猜错而结束
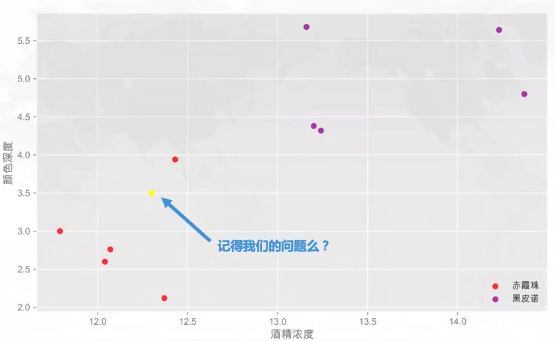
KNN——算法原理描述
k-近邻算法的本质是通过距离判断两个样本是否相似,如果距离够近就认为他们足够相似属于同一类别。
当然只对比一个样本是不够的,误差会很大,我们需要找到离其最近的k个样本,并将这些样本称之为【近邻】(nearest neighbor)
对这k个近邻,查看它们的都属于何种类别(这些类别我们称作【标签】labels)
然后根据“少数服从多数,一点算一票”原则进行判断,数量最多的标签类别就是新样本的标签类别。其中涉及到的原理是“越相近越相似”,这也是KNN的基本假设。
决策树算法
决策树(Decision Tree)是一种实现分治策略的层次数据结构,可以用于分类和回归。我们主要讨论的是分类的决策树。
分类决策树模型表示一种基于特征对实例进行分类的树形结构(包括二叉树和多叉树)。
决策树由节点(node)和有向边(directed edge)组成,树种包含三种节点:
-
根节点(root node):包含样本全集。没有入边,但又零条或多条出边
-
内部节点(internal node):对应于属性测试条件,恰有一条入边,和两条或多条出边。
-
叶节点(leaf node)或终节点(terminal node):对应于决策结果,恰有一条入边,但没有出边

决策树——算法原理概述
决策树学习本质上是从训练数据集种归纳出一组分类规则,也称为“树归纳”,对于给定的训练数据集,存在许多对它无错编码的树。而为了简单起见,我们感兴趣的是从中选出“最小”的树,这里的树的大小用树的节点数和决策节点的复杂性度量,从另一个角度看,决策树学习是由训练数据集估计条件概率模型。基于特征空间划分的类的条件概率模型有无数个,我们选择的模型应该是不仅能对训练数据有很好的拟合,而且对未知数据也有很好的预测。
但是,因为从所有可能的决策树中选取最优决策树是NP完全问题,所以我们必须使用启发式的局部搜索过程,在合理的时间内得到合理的树。
树的学习算法是“贪心算法”,从包含全部训练数据的根开始,每一步都选择最佳划分。依赖于所选择的属性是数值属性还是离散属性,每次将数据划分为两个或n个子集,然后使用对应的子集递归地进行划分,知道所有训练数据子集被基本正确分类,或者没有合适的特征为止,此时,创建一个树叶节点并标记它,这就生成了一颗决策树。
综上,决策树学习算法包含特征选择、决策树的生成与决策树的剪枝。其中,特征选择运用的算法主要包括“信息熵增益”、“信息增益比”、“基尼系数”,分别对应不同的树生成算法ID3、C4.5、CART等
7.常用无监督学习算法
聚类算法
KNN、决策树都是比较常见的机器学习算法,它们虽然有着不同的功能,但却都属于[有监督学习]的一部分,即是说,模型在训练的时候,既需要特征矩阵X,也需要真实标签Y。机器学习当中,还有相当一部分算法属于[无监督学习],无监督的算法在训练的时候只需要特征矩阵X,不需要标签,无监督学习的代表算法有聚类算法、降维算法。


posted on 2020-11-26 11:39 pandaboy1123 阅读(376) 评论(0) 编辑 收藏 举报


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
2019-11-26 【产品经理90天训练课程(一)】
2018-11-26 【leecode】独特的电子邮件地址
2018-11-26 【第七模块】爬虫总结