使用StreamSets从MySQL增量更新数据到Hive
使用StreamSets从MySQL增量更新数据到Hive
我们可以StreamSets实现数据采集,在实际生产中需要批量、实时捕获MySQL、Oracle等数据源的变化数据并将其写入大数据平台的Hive等。这里主要介绍如何使用StreamSets通过JDBC方式实时从MySQL抽取数据到Hive。
StreamSets实现的流程如下:
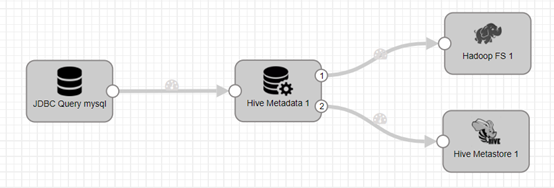
大致的流程如下:
- Reads data from a JDBC source using a query
- Generates Hive metadata and write information fo HDFS
- Updates the Hive Metastore。通俗的讲就是在目标库中创建表。
- Writes to a Hadoop file system。通俗的讲就是把数据写入到目标库的表中。
用到的各组件介绍:
这里除了看组件名称,也注意右上角的字母,有的组件图标很相似,但是功能是不一样的,要选择合适的组件。
第一个组件source, 如下图, Source是JDBC Query Consumer,看其注释:Reads data from a JDBC source using a query,可以知道是从数据库读取数据。
中间的组件,如下图,Hive Metadata,注释:Generates Hive metadata and write information fo HDFS。作用是根据源数据来产生相应的目标数据库的metadata和写入HDFS的需要的信息。
两个目标组件如下图:

目标组件一:Hadoop FS,注释:Writes to a Hadoop file system,是将数据写到HDFS,通俗的讲就是把data写入硬盘或者说Hive表。
目标组件二:Hive Metastore,注释:Updates the Hive Metastore,是将medata写入Hive,通俗的讲就是创建Hive表。
准备StreamSets。
下载StreamSets,一定要下载all版本,大概5.6G,迅雷一晚上下载完。Core版本不包含有些组件,安装不上。
https://archives.streamsets.com/datacollector/3.19.0/tarball/streamsets-datacollector-all-3.19.0.tgz
修改最大打开文件数
使用ulimit -a 可以查看当前系统的所有限制值,使用ulimit -n 可以查看当前的最大打开文件数。新装的linux默认只有1024,当作负载较大的服务器时,很容易遇到error: too many open files或者Configuration of maximum open file limit is too low: 1024。因此,需要将其改大。
使用 ulimit -n 65535 可即时修改,但重启后就无效了。
临时修改:
ulimit -n
ulimit -n 65535
永久修改:
echo ulimit -n 65535 >>/etc/profile
source /etc/profile
解压启动StreamSets。直接解压即可。
tar zxvf streamsets-datacollector-all-3.19.0.tgz
cd /home/cg/streamsets/
bin/streamsets dc
登录。缺省端口18630,原始用户名和秘密均是admin.目前只有251上的streamsets能解密并且写入hive,以此为例。
admin/admin
准备源数据库的表及数据。注意:因为要做增量测试,也就是随时需要向源MySQL中增加数据。
创建表:
drop table streamsetstest;
CREATE TABLE streamsetstest (
id int auto_increment,
no_encrypt varchar(255) NULL,
a nvarchar(255) NULL,
primary key (id)
);
插入数据:
INSERT INTO streamsetstest (no_encrypt,a) VALUES('BWP018930705', 'BWP018930705');
创建Pipeline.
创建一个Pipeline,依次创建所需要的组件,每次保证创建的组件能够连通。
New Pipeline.
登录http://ip:18630/,点击Create New Pipeline
填写Error Records相关的信息
写入Error Records的方式见下图:
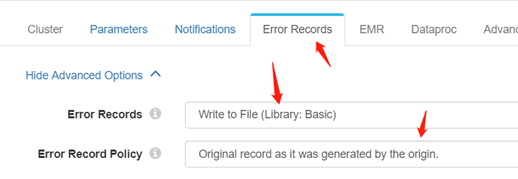
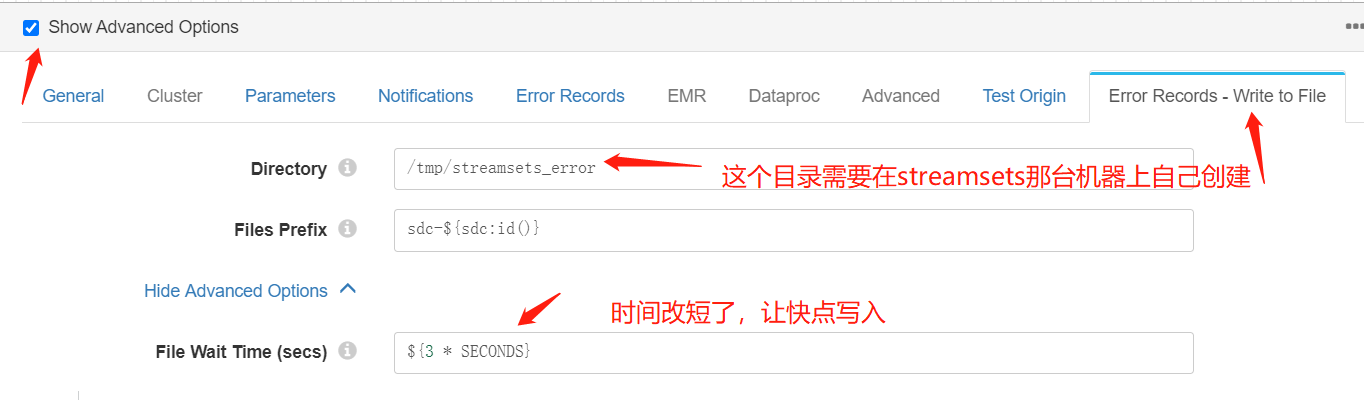
写入Error Records的位置见下图:
创建源组件
我们需要从MySQL或者Oracle中通过JDBC读取数据。可以根据图标和注释来选择合适的组件。
选择JDBC Query Consumer。如果Origin missing-> Select Origin能找到,就这么选择JDBC Query Consumer
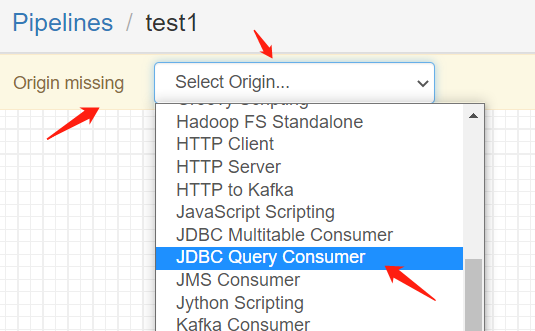
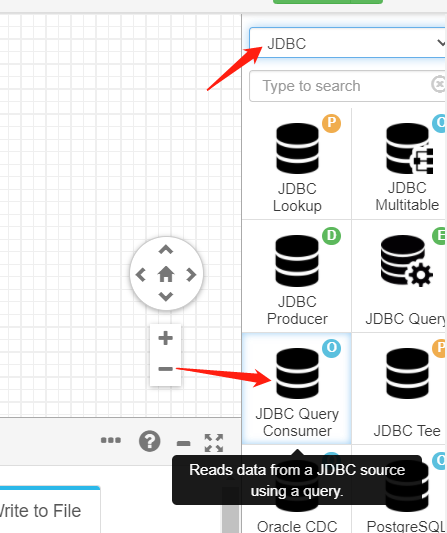
如果找不到,就在右侧Stage选JDBC,找到JDBC Query Consumer
配置JDBC Query Consumer。
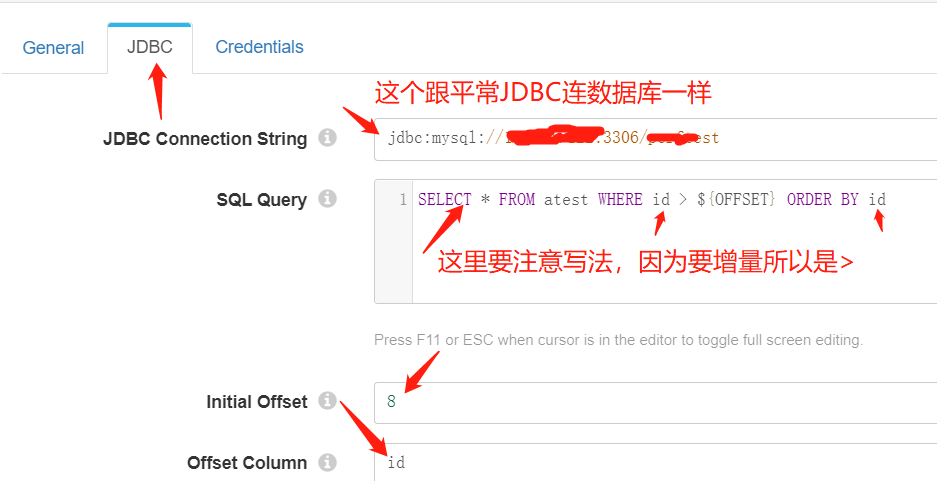
JDBC Connection String,如图,跟通常连JDBC的URL一致,无区别。
SQL Query: 有缺省的模板,需要将table名称改成具体的名称,where虽然能改成<,但是我们只有要测增量,所以最好还是>。注意和Initial Offset、Offset column值得对应关系。
Credential Tab里的配置,输入用户名和密码,无特别需要注意的地方。
JDBC Tab配置如下图:
这个源组件配置完毕之后,点击Preview按钮,看看什么地方有错误
Preview按钮如下图。
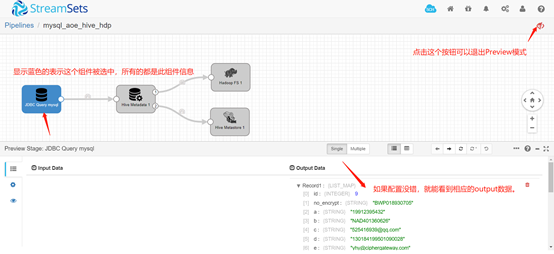
如果配置有错,streamsets会提示,根据提示找到相应的配置项改过来。如果配置没有错,就能看到下图中显示输出的数据。确定没错之后,退出Preview模式即可。
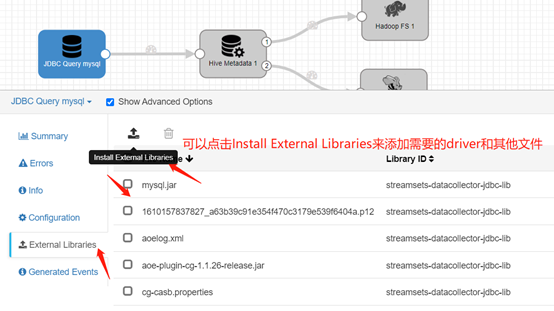
streamsets缺省的JDBC lib里并不含有MySQL的jdbc driver文件mysql.jar,我们需要点击Install External Libraries来添加需要的driver。
配置Hive Metadata组件。
这个组件的作用是Generates Hive metadata and write information fo HDFS。各个Tab里的配置会在下边说明。
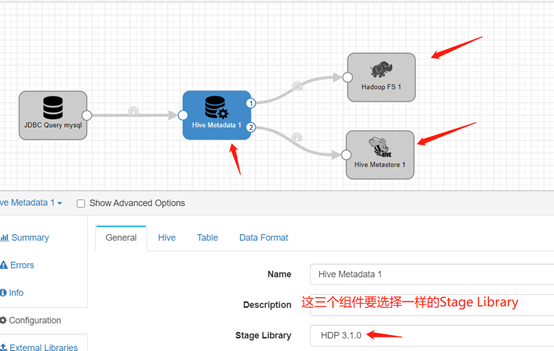
General:对于整个流程里涉及到的三个Hive相关的组件的Stage Library要选一样的,其他的不用管了。
General Tab配置如下图
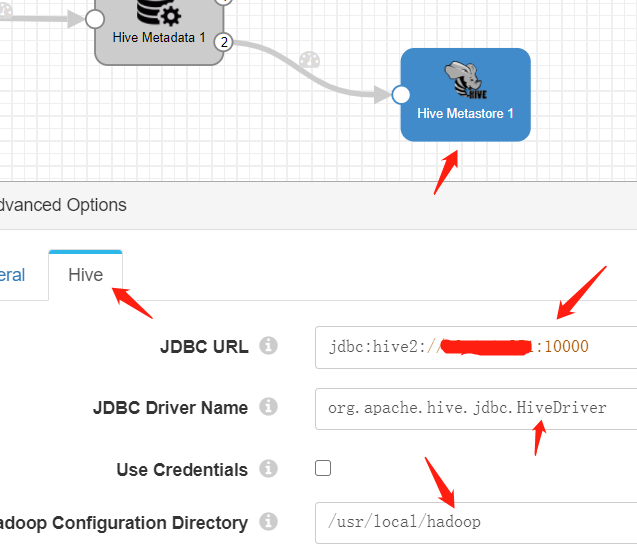
Hive Tab:
JDBC URL,这个没特别需要注意的地方
jdbc:hive2://ip:10000
JDBC Driver Name,也没啥需要特别注意的地方。
org.apache.hive.jdbc.HiveDriver
Use Credentials,这个依赖于Hive本身的配置,如果不需要用户密码,就不用填。如果需要就填上。至于怎么配置hive可以远程匿名访问,可以在网上查,或者见后边的附录。
Hadoop Configuration Directory,这个需要特别注意,这是存放core-site.xml hdfs-site.xml hive-site.xml的配置文件目录。我开始直觉的认为这是hadoop服务器上的directory,实际上不是。我们需要在StreamSets服务器所在的那台机器上创建一个目录,然后从Hadoop那台机器下载那几个文件,放在这个目录里。
Hive Tab配置如下图
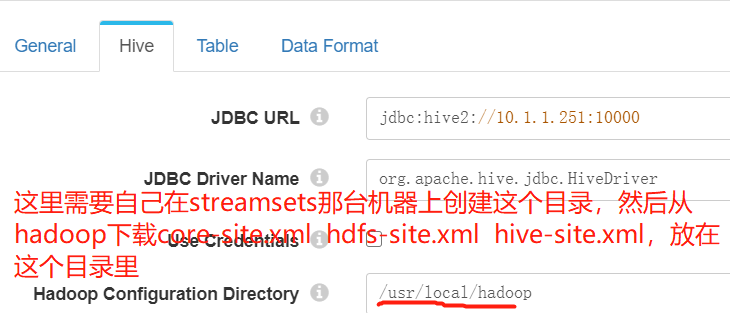
Table Tab:
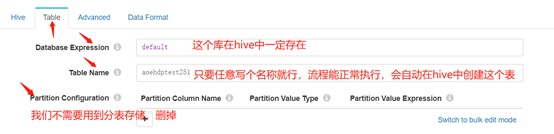
Database Expression:无特别需要注意的地方。这个应该是hive已经存在的数据库名称。
Table Name: 这个不需要在数据库中手动创建此表。如果整个流程没有问题,会自动创建这个表。咱们可以写任何我们想要的表名称。
Partition Configuration: 这里我们不需要分表存储,所以删掉,不用配置此项。
Table Tab配置如下图:
Data Format Tab:
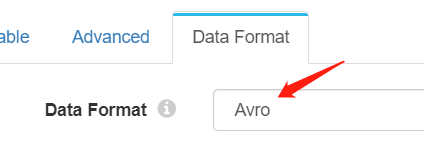
Data Format:选Avro即可。无特别需要注意的地方。
添加目标组件一:Hadoop FS,注释:Writes to a Hadoop file system,是将数据写到HDFS。通俗的讲就是把data写入。
Connection Tab:
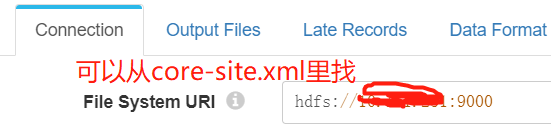
File System URI,
hdfs://ip:9000
这个值可以从hadoop那台机器上的core-site.xml里找。
<property>
<name>fs.defaultFS</name>
<value>hdfs://ip:9000</value>
</property>
Connection Tab 配置如下:
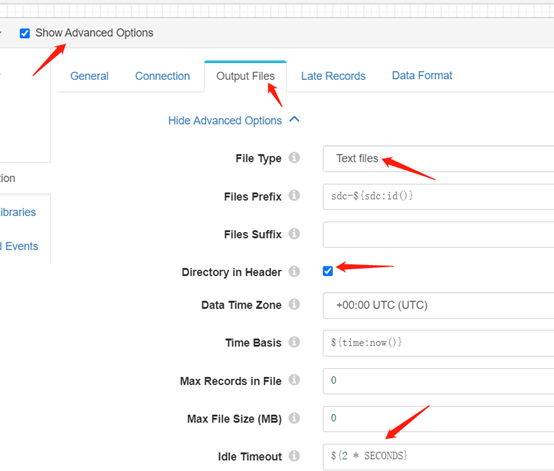
Output Files Tab:
也是需要Show Advanced Options,注意
check上Directory in Header
修改Idle Timeout,缺省的可能是1小时,导致长时间没有写入到Hive。
Output Files Tab配置如下图:
Data Format如下图所示选择即可:

添加目标组件二:Hive Metastore,注释:Updates the Hive Metastore,是将medata写入Hive,通俗的讲就是创建Hive表。
整个组件的配置也没有特别需要说明的地方,一些配置从上个Hive Metastore组件copy过来就行。
遇到的问题及解决方法
远程匿名访问hive
修改core-site.xml加上以下部分,然后重启Hadoop。
远程匿名访问Hive,会直接以root用户访问Hive。
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.sdc.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.sdc.groups</name>
<value>*</value>
</property>
重启Hadoop
cd /usr/local/hadoop-2.10.1/
sbin/stop-all.sh
sbin/stop-all.sh
将数据写入表时遇到如下错误
Permission denied: user=anonymous, access=WRITE, inode="/hive/warehouse":root:supergroup:drwxr-xr-x
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:3
原因是权限问题,根据错误提示,开放相应目录权限。
hadoop dfs -chmod -R 777 /hive/warehouse
hadoop dfs -chmod -R 777 /tmp/hadoop-yarn
简单程序验证Hive是否可远程创建表并插入数据。确保Hive可以远程创建表并插入数据,再在streamsets上试验。
需要用到的jar包如下:大概需要11个包
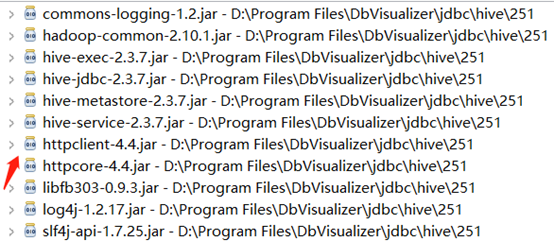
附简单程序,已验证通过。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class HiveConnectionTest {
public static void main(String[] args) throws Exception {
Class.forName("org.apache.hive.jdbc.HiveDriver");
String dropSQL="DROP TABLE streamsetstest";
String createSQL="CREATE TABLE streamsetstest(id int,no_encrypt string,a string)";
//String insterSQL="LOAD DATA LOCAL INPATH '/work/hive/examples/files/kv1.txt' OVERWRITE INTO TABLE javabloger";
String insertSQL="INSERT INTO streamsetstest (no_encrypt,a) VALUES('test1', 'test2')";
String querySQL="select * from streamsetstest";
Connection con = DriverManager.getConnection("jdbc:hive2://ip:10000/default", "", "");
Statement stmt = con.createStatement();
stmt.execute(dropSQL);
stmt.execute(createSQL); // 执行建表语句
stmt.execute(insertSQL); // 执行插入语句
ResultSet res = stmt.executeQuery(querySQL); // 执行查询语句
while (res.next()) {
System.out.println("Result: no_encrypt:"+res.getString(2) +" –> a:" +res.getString(3));
}
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号