软件编写目录规范+正则表达式
软件编写目录规范+正则表达式
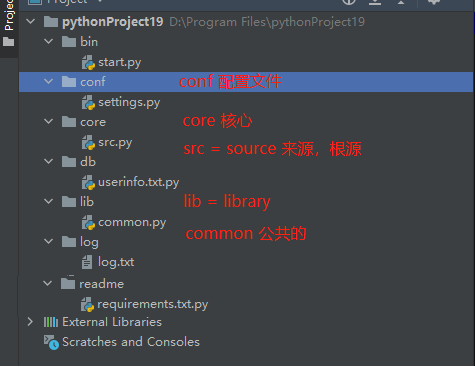
1.软件开发目录规范
正则表达式
地狱-天堂之说,源自老程序员的话,老程序员告诉我们,没有正则表达式就像地狱一般,有了正则表达式我们就像进了天堂一样!!!
正则表达式并不是Python的一部分。正则表达式是用于处理字符串的强大工具,拥有自己独特的语法以及一个独立的处理引擎,效率上
可能不如str自带的方法,但功能十分强大。

2.2 常用的正则匹配工具 
在线匹配工具:1. http://tool.chinaz.com/regex/ 这个用起来相当奈斯,so easy! too happy!
2. http://www.regexpal.com/
2.3 正则表达式基础知识
正则表达式的大致匹配过程是:依次拿出表达式和文本中的字符比较,如果每一个字符都能匹配,则匹配成功;一旦有匹配不成功的字符则
匹配失败。如果表达式中有量词或边界,这个过程会稍微有一些不同,但也是很好理解的,看下图中的示例以及自己多使用几次就能明白。
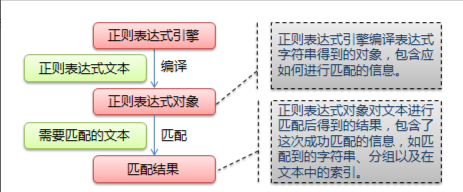
上图:使用正则表达式进行匹配的流程

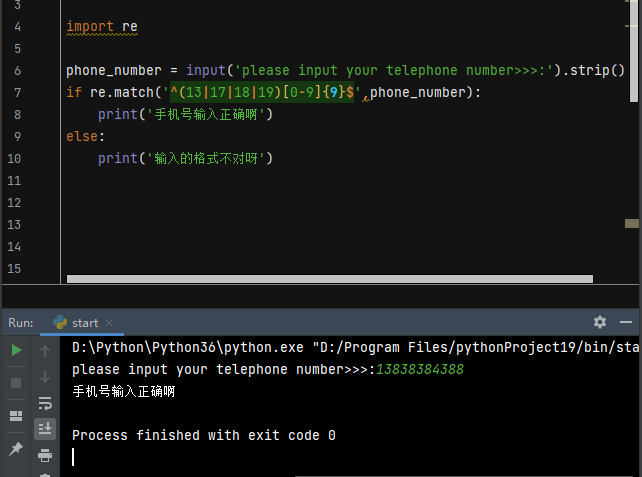
1.必须是11位
2.必须是纯数字
3.必须符合手机号的排布 13 17 18 19
3.字符组

4.特殊符号
| . 句点符 | 匹配除了换行符之外的任意字符 |
| \d | 匹配数字 |
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的结束 |
| PS:^与$结合使用,就是精确的确定两者之间的内容 | |
| a|b | | 竖杠表示 匹配字符a或者字符b |
| () | 表示括号内的表达式也是一个整体 |
| [ 1, 2 ] | 匹配中括号内的字符 |
| [ ^... ] | 匹配除了中括号[]内的其他所有字符 |
5.量词
| * 星号 | 表示重复零次或更多次 |
| + 加号 | 表示重复一次或者多次 |
| ?问号 | 表示重复零次0或者一次 |
| {n} | 表示重复n次 |
| {n,} | 表示重复n次或者更多次 |
| {n,m} | 表示重复n到m次 |
在原生的正则表达式中取消转义推荐使用\(每个\只能取消一个字符的转义)
在python中取消转义推荐使用r'\n\a\t'(也可以使用\)
7.贪婪匹配与非贪婪匹配
1 带匹配的字符串 2 <script>123</script> 3 正则表达式 4 <.*> '''默认贪婪匹配 尽可能多的匹''' 5 将贪婪变为非贪婪 只需要在量词的后面加问号即可 6 <.*?> '''非贪婪匹配 尽可能少的匹 结束条件有左右两边决定'''

