可迭代对象+迭代器对象+异常捕获
可迭代对象+迭代器对象+异常捕获

一、常用内置函数
1. 映射 map()
循环获取列表中每个元素并传递给匿名函数保存返回值

2.拉链 zip()

# for循环先取值 之后再比较大小

上图中,可更换容器类型输出,但是输出后,内存就没有值了,再同容器类型输出就是空的了。
3.最大值、最小值 max() min()



4. 过滤 filter()

5. 归总 reduce()
还可以额外添加元素值


字符串、列表、字典、元组、集合、文件对象都是可迭代对象:



每一次对过程的重复称为一次“迭代”,而每一次迭代得到的结果会作为下一次迭代的初始值,单纯的重复并不是迭代

上图:以每次重新赋值后的index值作为下一次循环中新的索引进行取值,反复迭代,最终可以取尽列表中的值

三、
迭代器对象:即含有__iter__方法 又含有__next__方法,可迭代对象调用__iter__方法会变成迭代器对象(老母猪)。
文件对象本身即是可迭代对象又是迭代器对象,迭代器对象无论执行多少次__iter__方法 还是迭代器对象(本身)
__iter__方法在调用的时候还有一个简便的写法iter(),一般情况下所有的双下方法都会有一个与之对应的简化版本 方法名()

迭代器是Python提供的一种统一的、不 依赖于索引的迭代取值方式,只要存在多个“值”,无论序列类型还是非序列类型都可以按照迭代器的方式取值


四、for循环的本质
有了迭代器后,我们便可以不依赖索引迭代取值了,使用while循环的实现方式如下




for循环又称为迭代循环,in后可以跟任意可迭代对象,上述while循环可以简写为:

五、迭代器的优缺点
基于索引的迭代取值,所有迭代的状态都保存在了索引中,而基于迭代器实现迭代的方式不再需要索引,所有迭代的状态就保存在迭代器中,然而这种处理方式优点与缺点并存
-
优点:
- 为序列和非序列类型提供了一种统一的迭代取值方式;
- 惰性计算:迭代器对象表示的是一个数据流,可以只在需要时才去调用next()来计算出一个值;就迭代器本身来说,同一时刻在内存中只有一个值,因而可以存放无限大的数据流,而对于其他容器类型,如列表,需要把所有的元素都存放于内存中,受内存大小的限制,可以存放的值的个数是有限的。
-
缺点:
- 除非取尽,否则无法获取迭代器的长度;
- 只能取下一个值,不能回到开始,更像是“一次性的”,迭代器产生后的唯一目标就是重复执行next()方法直到值取尽,否则就会停留在某个位置,等待下一次调用next();若是要再次迭代同个对象,你只能重新调用iter()方法去创建一个新的迭代器对象,如果有两个或者多个循环使用同一个迭代器,必然只会有循环能取到值。

六、异常捕获
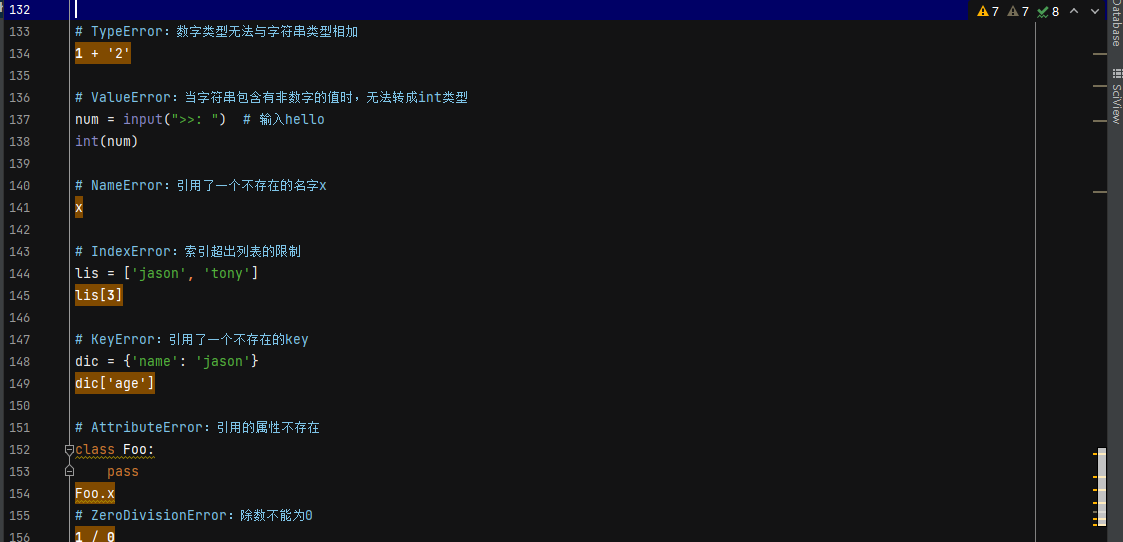
# 什么是异常 代码运行出错会导致异常 异常发生后如果没有解决方案则会到底整个程序结束 # 异常三个重要组成部分 1.traceback 翻到最下面从下往上的第一个蓝色字体鼠标左键点击即可跳转到错误的代码所在的行 2.XXXError 错误的类型 3.错误类型冒号后面的内容 错误的详细原因(很重要 仔细看完之后可能就会找到解决的方法)

# 错误的种类 1.语法错误 不被允许的 出现了应该立刻修改!!! 2.逻辑错误 可以被允许的 出现了之后尽快修改即可 '''修改逻辑错误的过程其实就是在从头到尾理清思路的过程'''
1. 语法错误
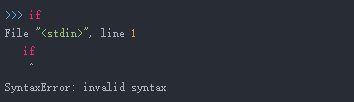
2.另一种就是逻辑错误,出现了之后尽快修改即可
万能公式如下:



1 # 万能异常 2 try: 3 # int('abc') 4 print(name) 5 # l = [11] 6 # l[100] 7 except Exception: 8 print('你来啥都行 无所谓')
1 try: 2 被监测的代码 3 except 错误类型 as e: 4 ... 5 else: 6 被监测的代码不报错的时候执行 7 finally: 8 无论是否报错最终都会执行 9 10 # 断言(了解) 11 name = 'jason' 12 assert isinstance(name,str) 13 14 # 主动报异常 15 raise 错误类型

七、
1 d = {'name':'jason','pwd':123,'hobby':'read'} 2 3 res = d.__iter__() # StopIteration 4 while True: 5 try: t 6 print(res.__next__()) 7 except StopIteration as e: 8 break 9 10 11 for i in d: 12 print(i)
八、


