
pynlpir + pandas 文本分析
pynlpir是中科院发布的一个分词系统,pandas(Python Data Analysis Library) 是python中一个常用的用来进行数据分析和统计的库,利用这两个库能够对中文文本数据进行很方便的分析和统计。
分词系统有好几种,在使用pynlpir时发现有一些不好的地方:
①不能对繁体字正确的分词,如 “台灣” 分出来时 “台” “灣” 两个字,“台湾” 分出来就是 “台湾” 一个地名,然后就调用了另一个分词系统(SnowNLP)先对文本进行了繁简转换。(直接用SnowNLP分词不更方便吗,下次试试)
②pynlpir的License的有效期为一个月,一个月后就要手动更新License文件。比较麻烦,不能实现完全的自动化。
这里分析一个10M左右的TXT文件(一万六千多行),目的和过程:分词→高频词统计→词性分离统计→各词性高频词统计→画统计图直观显示
遇到的问题及解决办法:
①、文本数据比较多,全部读取并统计话费时间太长,并且cpu占用量太高
发现时间上主要浪费在数据的清洗(停用词过滤),pandas对数据的操作十分快,于是就把文本清洗和词频统计分开执行,单独进行数据清洗,清洗后用pandas存入csv文件,词频统计时直接读取文件就行,这样csv文本中虽然有一百多万个词语,读取并处理时也非常快,这样以后处理也可以直接用pandas读取处理后csv文件。
②、多进程的使用
python因为内部有GIL锁,对CPU密集型的不能实现真正意义上的多线程(但对IO密集型的可以大大提高速度,如爬虫),为了提高速度打算用多线程+多进程,可是在多线程中每个线程处理数据的结果不知道怎么汇集到一块,尝试了用Queue队列,可是还不行,然后就直接分两个程序同时跑了,算是代替两个进程吧。
感觉出错的地方是把单行处理的Dataframe结果append到总的Dataframe上,明明两者的列名一样,不知道为什么会添加不上。
文本清洗模块:
把源数据文件手动分成两个同时处理(速度快),一次读取一行创建一个线程对单行进行处理,线程控制在5个,单行处理后的存入总数据, 所有处理完后存入csv文件,文件有两列 词汇--词性。用时20分钟左右。
导入包:
import pynlpir import pandas as pd import threading,time
读入文本、停用词文件,创建保存初始分词数据的Dataframe
f_1 = open(r"停用词.txt", "r") stopwords = f_1.read().splitlines() f_1.close() f = open(r"data_1.txt", "r") pd_root = pd.DataFrame(columns=['词汇', '词性'])
pynlpir.open()
过滤停用词函数:
def stopword_delete(df):
global stopwords
for i in range(df.shape[0]):
if (df.词汇[i] in stopwords) or ("=" in df.词汇[i]) or ("//" in df.词汇[i]):
df.drop(i,inplace=True)
else:
pass
return df
单行处理函数:
def line_deal(line):
global pd_root
line = line.replace(" ", "")
segment = pynlpir.segment(line, pos_names='parent', pos_english=False) #对单行分词
pd_line = pd.DataFrame(segment,columns=['词汇','词性']) #单行datafrrame
pd_line = stopword_delete(pd_line) #过滤停用词
pd_root = pd_root.append(pd_line,ignore_index=True) #把单行信息添加到总的上面
使用多线程读取:
PS:虽然说有GIL锁,但用多线程还是比单线程快
时时打印进程数和读取进度能清楚的知道程序 运行的情况
threads_list = [] #线程列表
thread_max = 5 #最大线程
n=0
for line in f:
p = threading.Thread(target=line_deal,args=(line,))
threads_list.append(p)
p.start()
n=n+1
print('当前进程数'+str(len(threads_list)),'读取到第'+str(n)+'行') #打印当前线程数和读取到的行数
for pro in threads_list:
if pro.is_alive() == True:
continue
else:
threads_list.remove(pro)
if len(threads_list) >= thread_max:
time.sleep(0.03)
else:
continue
f.close() #读取完后关闭文件
打印最清洗并分词后的数据,然后存储到csv文件:
print(pd_root.head(20)) #打印前20个
pd_root.to_csv('clean2.csv',encoding="gbk")
数据统计模块:
读取上个模块存储的数据进行频数、词性统计。用时几秒。
读取处理后的数据:
pd_root = pd.DataFrame(columns=['词汇', '词性'])
df_1 = pd.read_csv("clean1.csv",encoding="gbk").drop(columns='Unnamed: 0')
df_2 = pd.read_csv("clean2.csv",encoding="gbk").drop(columns='Unnamed: 0')
pd_root = pd_root.append(df_1[['词汇','词性']])
pd_root = pd_root.append(df_2[['词汇','词性']])
pd_root = pd_root.dropna(axis=0)
去除一些不想要的词:
words_del = ['击','查看','酒','点','幻灯','图片','没','说','新','长','高','少']
for i in words_del:
pd_root = pd_root[~(pd_root['词汇'] == i)]
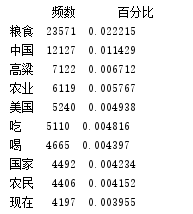
创建词汇-频数库:
pd_word_num = pd.DataFrame(pd_root['词汇'].value_counts())
pd_word_num.rename(columns={'词汇': '频数'})
pd_word_num.rename(columns={'词汇':'频数'},inplace=True)
pd_word_num['百分比'] = pd_word_num['频数'] / pd_word_num['频数'].sum()
print(pd_word_num.head(10))
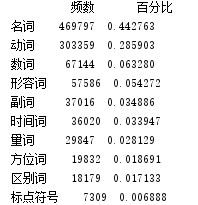
创建词性-频数库:
pd_qua_num = pd.DataFrame(pd_root['词性'].value_counts())
#更改列名
pd_qua_num.rename(columns={'词性':'频数'},inplace=True)
#添加百分比列:词性-频数-百分比
pd_qua_num['百分比'] = pd_qua_num['频数'] / pd_qua_num['频数'].sum()
print(pd_qua_num.head(10))
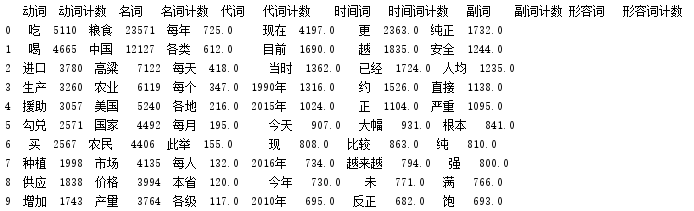
统计几种重要词性的词汇分布:
# 定义6类词性统计数据框
columns_selected=['动词','动词计数','名词','名词计数','代词','代词计数',
'时间词','时间词计数','副词','副词计数','形容词','形容词计数']
pd_Top6 = pd.DataFrame(columns=columns_selected)
for i in range(0,12,2):
pd_Top6[columns_selected[i]] = pd_root.loc[pd_root['词性']==columns_selected[i]]['词汇'].value_counts().reset_index()['index']
pd_Top6[columns_selected[i+1]] = pd_root.loc[pd_root['词性']==columns_selected[i]]['词汇'].value_counts().reset_index()['词汇']
print(pd_Top6.head(10))
提取文本中关键词:
key_words = pynlpir.get_key_words(str, weighted=True) print(key_words)
绘图:
def paint(df,x,y,title):
plt.subplots(figsize=(7,5))
plt.yticks(fontproperties=font,size=10)
plt.xlabel(x,fontproperties=font,size=10)
plt.ylabel(y,fontproperties=font,size=10)
plt.title(title,fontproperties=font)
df.iloc[:10]['频数'].plot(kind='barh')
plt.show()
paint(pd_word_num,"频数","词汇","词汇分布")
paint(pd_qua_num,"频数","词性","词性分布")
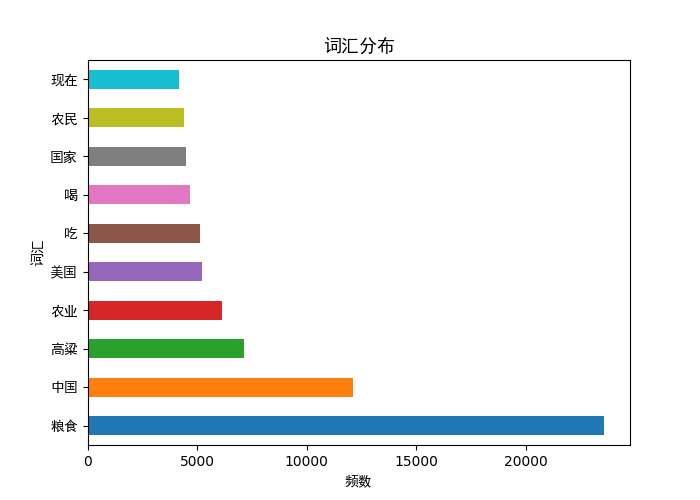
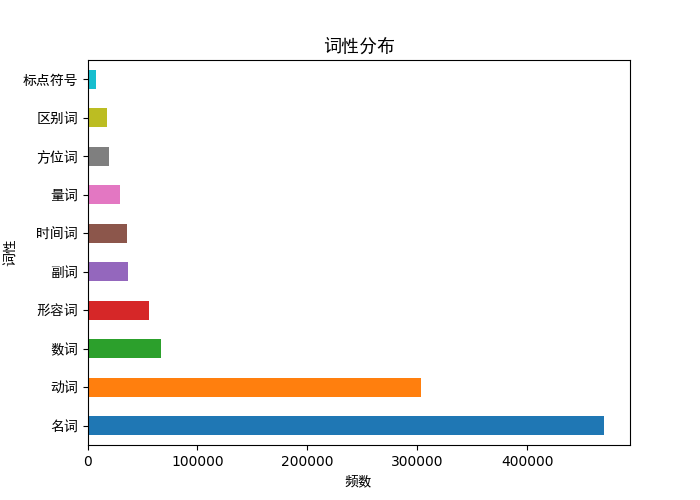
fig = plt.figure(figsize=(10,5))
fig.subplots_adjust(hspace=0.3,wspace=0.2)
for i in range(1,7):
pd_qua = pd_Top6.iloc[:,[(2*i-2),2*i-1]]
pd_qua.columns = [pd_qua.columns[0],'频数']
pd_qua = pd_qua.set_index(pd_qua.columns[0])
print(pd_qua)
ax = fig.add_subplot(2,3,i)
pd_qua.head(10)['频数'].plot(kind='bar')
ax.set_xticklabels(pd_qua.head(10).index,fontproperties=font,size=10,rotation=30)
ax.set_title(pd_qua.index.name,fontproperties=font)
fig.tight_layout()
fig.show()

生成词云:
font_wc= r'C:\Windows\Fonts\msyhbd.ttc'
word_list = []
word_list.extend(pd_Top6.形容词[:10])
word_list.extend(pd_Top6.名词[:20])
word_list.extend(pd_Top6.动词[:20])
word_list.extend(pd_Top6.代词[:10])
word_list.extend(pd_Top6.时间词[:10])
myText=' '.join(word_list)
print(myText)
# 设置词云属性,包括设置字体、背景颜色、最大词数、字体最大值、图片默认大小等
wc = WordCloud(font_path=font_wc, max_words=200,max_font_size=150,
background_color='white',colormap= 'autumn',scale=1.5,random_state=30,width=800,height=600)
wc.generate(myText)
plt.imshow(wc)
plt.axis('off')
plt.show()

待优化、待提高:
1、各模块、各函数的封装,可以创建类对象而不是多程序分别执行。
2、数据清洗,“imgsrc=”、“title=”.... 被分到名词那里去了。
3、检查数据处理后正确性、完整性,因为发现有时候多次处理后的结果不一样。(可以先用小数据分析)
4、可视化方面待提高,给人最直观的信息。(另外最后一张图代码上应该有问题)
心得分享:
1、常见的问题需要把原因了解透,这样以后就能正确的排除错误而不是遇到错误就百度,比如文件、字符串编
如有错误,欢迎指正
更新(原文中已更改):
待优化、待提高部分:
① 仍没把各部分封装到一个程序中。
② 修改了过滤停用词函数,影响分析的内容。
③ 程序如果没有错误,不会影响数据的完整性。
④ 增加词云,提高可视化。
发现原来文章中的一些错误:
① pandas中dataframe的遍历速度很快,如果清洗后的数据在分析时仍有频率高但是不想要的词语,可以再次遍历dataframe进行去除。
② 因为处理数据的方法一样,在CPU使用率一样的情况下,加线程控制与不加线程控制的速度一样,加线程控制只是不让CPU频率一直过高。
③一个严重的错误,我在处理的时候为了看到处理进度处理到每行就打印行号,每个print都会消耗时间,所以总的处理时间要比最后计算的时间少。
