

5个PyCaret的常见误解
作者|Moez Ali
编译|VK
来源|Towards Data Science

PyCaret
PyCaret是Python中的一个开源、低代码的机器学习库,它自动化了机器学习工作流。它是一个端到端的机器学习和模型管理工具,可以加快机器学习实验的周期,并使你更有效率。
与其他开放源代码机器学习库相比,PyCaret是一个低代码库,可以用很少的代码来替换数百行代码。这使得实验具有指数级的速度和效率开发。
compare_models比你想的要好
当我们在2020年4月发布了PyCaret的1.0版本时,compare_models函数会比较库中的所有模型,以返回平均的交叉验证性能指标。在此基础上,你可以使用create_model来训练性能最好的模型,并获得可用于预测的训练模型输出。
这种行为后来在版本2.0中进行了更改。compare_models现在根据n_select参数返回最佳模型,该参数默认设置为1,这意味着它将返回最佳模型(默认情况下)。
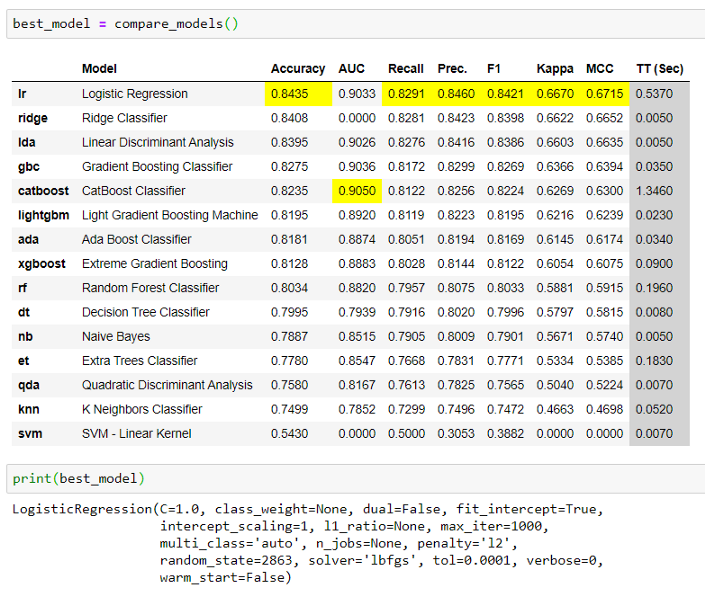
通过将默认的n_select参数更改为3,可以获得前3个模型的列表。例如:
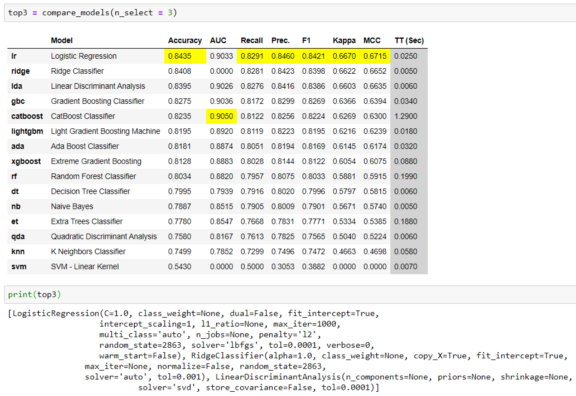
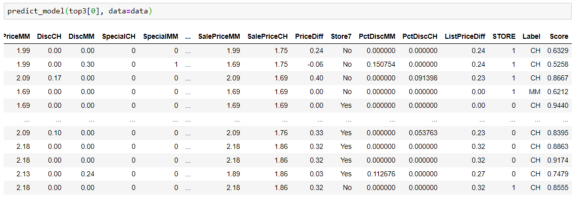
返回的对象是经过训练的模型,实际上不需要再次调用create_model来训练它们。如果你愿意,你可以使用这些模型来生成诊断图,甚至可以将它们用于预测。例如:
你认为你只限于scikit-learn模型
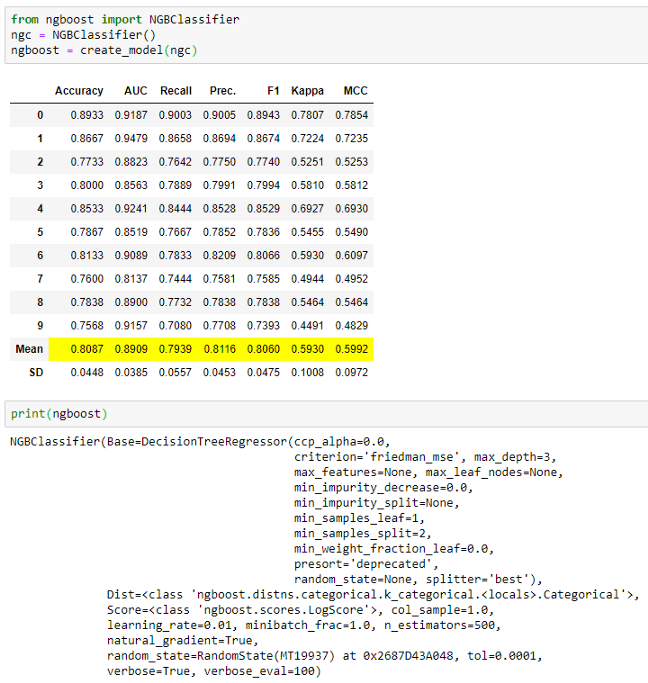
我们收到很多请求,要求在模型库中包含非scikit-learn模型。很多人没有意识到你不仅仅局限于默认模型。create_model函数除了接受模型库中可用的模型ID之外,还接受未经训练的模型对象。
只要你的对象与scikit learn-fit/predict-API兼容,它就可以正常工作。例如,我们只需导入未经训练的NGBClassifier,就可以从ngboost库中训练和评估NGBClassifier :
你也可以把未经训练的模型传递到compare_models 的include参数中,这样它就可以正常工作了。
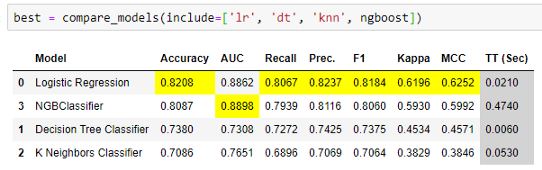
注意,包含的参数包括模型库中三个未训练模型的ID,即Logistic回归、决策树和K近邻,以及ngboost库中的一个未训练对象。另外,请注意,索引表示在include参数中输入的模型的位置。
你不知道的pull
PyCaret中的所有训练函数(create_model、tune_model、ensembly_model等)都会显示一个分数网格,但不会返回分数网格。因此,你不能将分数网格存储在DataFrame. 但是,有一个名为pull的函数允许你这样做。例如:
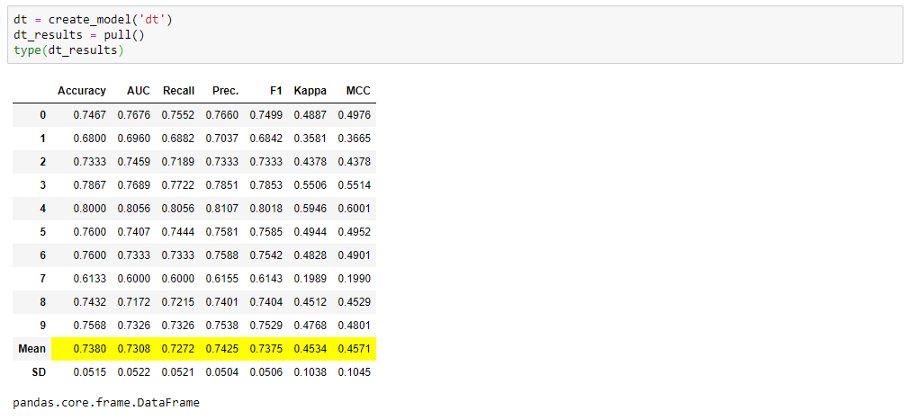
当你使用predict_model函数时,这也适用于保存分数网格。

现在你可以像pandas一样访问度量了。例如,你可以创建一个循环来训练具有不同参数的模型,并使用以下简单代码创建一个比较表:
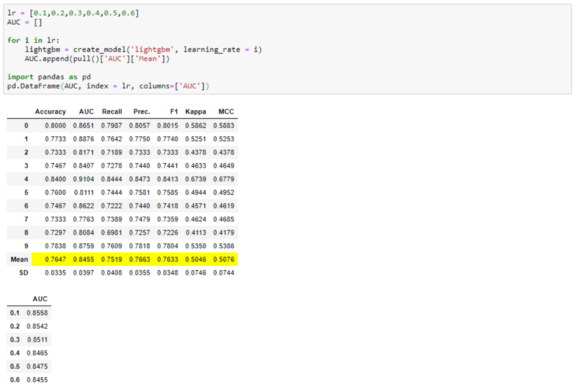
你认为PyCaret是个黑匣子,其实不然。
另一个常见的困惑是,所有的预处理都是在幕后进行的,用户无法访问。因此,你无法审核运行设置函数时发生的情况。这不是真的。
PyCaret get_config和set_config中有两个函数,允许你访问和更改后台的所有内容,从训练集到模型的随机状态。只需调用help(get_config)即可查看get_config函数的文档,查看哪些变量可供你访问:
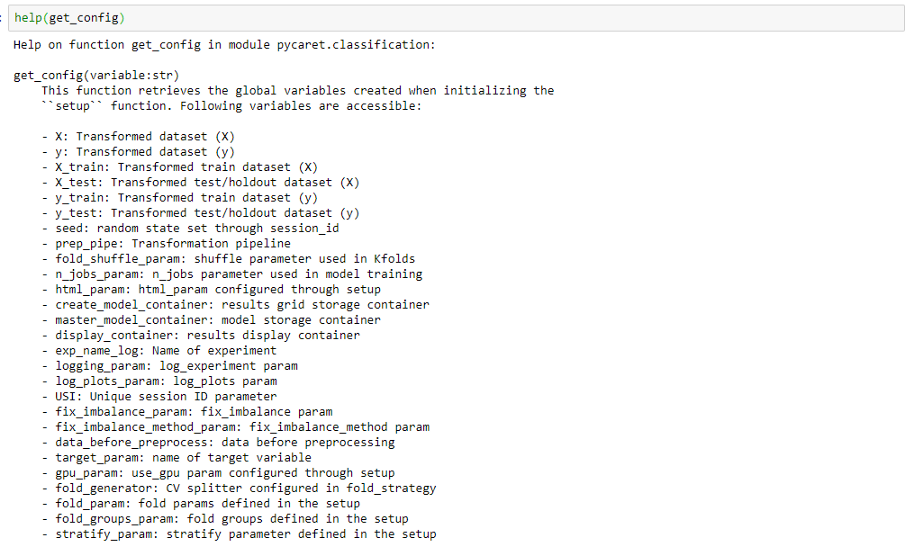
你可以通过在get_config函数中调用它来访问该变量。例如,要访问X_train 转换后的数据集,请编写以下内容:
你可以使用set_config函数更改环境变量。根据你目前对pull、get_config和set_config函数的了解,你可以创建一些非常复杂的工作流。例如,可以对保留集重新采样N次,以评估平均性能指标,而不是依赖于一个保留集:
import numpy as np
Xtest = get_config('X_test')
ytest = get_config('y_test')
AUC = []
for i in np.random.randint(0,1000,size=10):
Xtest_sampled = Xtest.sample(n = 100, random_state = i)
ytest_sampled = ytest[Xtest_sampled.index]
set_config('X_test', Xtest_sampled)
set_config('y_test', ytest_sampled)
predict_model(dt);
AUC.append(pull()['AUC'][0])
>>> print(AUC)
[Output]: [0.8182, 0.7483, 0.7812, 0.7887, 0.7799, 0.7967, 0.7812, 0.7209, 0.7958, 0.7404]
>>> print(np.array(AUC).mean())
[Output]: 0.77513
你没有保存你的实验
如果你没有保存你的实验,你应该立即开始保存它们。无论你是否要使用MLFlow后端服务器,你仍然应该记录所有的实验。当你执行任何实验时,你会生成大量的元数据,这些元数据是不可能手动跟踪的。
PyCaret的日志功能将在使用get_logs函数时生成一个漂亮、轻量级、易于理解的excel电子表格。例如:
# 加载数据集
from pycaret.datasets import get_data
data = get_data('juice')
# 初始化setup
from pycaret.classification import *
s = setup(data, target = 'Purchase', silent = True, log_experiment = True, experiment_name = 'juice1')
# 比较基线模型
best = compare_models()
# 生成日志
get_logs()

在这个非常短的实验中,我们已经生成了3000多个元数据点(度量、超参数、运行时等)。想象一下,你将如何手动跟踪这些数据点?也许,这实际上不可能。幸运的是,PyCaret提供了一种简单的方法来完成它。只需在设置函数中将log_experiment设置为True即可。
要了解PyCareT2.2中的所有更新的更多信息,请参阅发行说明或阅读此公告:https://www.github.com/pycaret/pycaret/
重要链接:
用户指南:https://www.pycaret.org/guide
文档:https://pycaret.readthedocs.io/en/latest/
官方教程:https://github.com/pycaret/pycaret/tree/master/tutorials
Notebook示例:https://github.com/pycaret/pycaret/tree/master/examples
其他资源:https://github.com/pycaret/pycaret/tree/master/resources
想了解特定模块吗
单击下面的链接,查看文档和工作示例。
分类:https://pycaret.readthedocs.io/en/latest/api/classification.html
回归:https://pycaret.readthedocs.io/en/latest/api/regression.html
聚类:https://pycaret.readthedocs.io/en/latest/api/clustering.html
异常检测:https://pycaret.readthedocs.io/en/latest/api/anomaly.html
自然语言处理:https://pycaret.readthedocs.io/en/latest/api/nlp.html
关联规则挖掘:https://pycaret.readthedocs.io/en/latest/api/arules.html
原文链接:https://towardsdatascience.com/5-things-you-are-doing-wrong-in-pycaret-e01981575d2a
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 字符编码:从基础到乱码解决