
pandas高效实现条件逻辑
作者|Louis Chan
编译|VK
来源|Towards Data Science

Python可以说是当今最酷的编程语言(多亏了机器学习和数据科学),但与最好的编程语言之一C相比,它的效率并不是很高。
在开发机器学习模型时,很常见的情况是,我们需要根据从统计分析或上一次迭代的结果导出的硬编码规则,然后以编程方式更新。承认这一点并不羞耻:我一直在用Pandas apply编写代码,直到有一天我对嵌套非常厌烦,于是决定研究(又称Google)其他更可维护、更高效的方法
演示数据集
我们将要使用的数据集是iris数据集,你可以通过pandas或seaborn免费获得它。
import pandas as pd
iris = pd.read_csv('https://raw.githubusercontent.com/mwaskom/seaborn-data/master/iris.csv')
# import seaborn as sns
# iris = sns.load_dataset("iris")
iris数据集的前5行
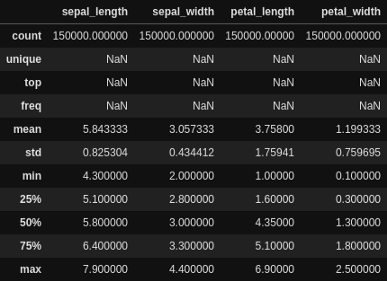
数据统计信息
假设在初始分析之后,我们希望用以下逻辑标记数据集:
-
如果萼片长度(sepal length)< 5.1,则标签为0;
-
否则,如果萼片宽度(sepal width)> 3.3和萼片长度< 5.8,则标签为1;
-
否则,如果萼片宽度> 3.3,花瓣长度(petal length)> 5.1,则标签为2;
-
否则,如果萼片宽度> 3.3,花瓣长度< 1.6且萼片长度< 6.4或花瓣宽度< 1.3,则标签3;
-
否则,如果萼片宽度>3.3且萼片长度< 6.4或花瓣宽度< 1.3,则标签为4;
-
否则,如果萼片宽度> 3.3,则标签为5;
-
否则标签6
在深入研究代码之前,让我们快速地将一个新的label列设置为None:
iris['label'] = None
Pandas.iterrows+嵌套If Else块
如果你还在用这个,这篇博文绝对是适合你的地方!
%%timeit
for idx, row in iris.iterrows():
if row['sepal_length'] < 5.1:
iris.loc[idx, 'label'] = 0
elif row['sepal_width'] > 3.3:
if row['sepal_length'] < 5.8:
iris.loc[idx, 'label'] = 1
elif row['petal_length'] > 5.1:
iris.loc[idx, 'label'] = 2
elif (row['sepal_length'] < 6.4) or (row['petal_width'] < 1.3):
if row['petal_length'] < 1.6:
iris.loc[idx, 'label'] = 3
else:
iris.loc[idx, 'label'] = 4
else:
iris.loc[idx, 'label'] = 5
else:
iris.loc[idx, 'label'] = 6
1min 29s ± 8.91 s per loop (mean ± std. dev. of 7 runs, 1 loop each)
时间挺长…好吧,我们继续…
Pandas .apply
Pandas.apply直接用于沿数据帧的轴或Series来应用函数。例如,如果我们有一个函数f,它可以是一个数列的和(例如,可以是一个list, np.array, tuple等),并将其传递给如下数据帧,我们将跨行求和:
def f(numbers):
return sum(numbers)
df['Row Subtotal'] = df.apply(f, axis=1)
在axis=1上应用函数。默认情况下,apply参数axis=0,即逐行应用函数;而axis=1将逐列应用函数。
现在我们已经对pandas.apply有了基本的了解,现在让我们编写分配标签的逻辑代码,看看它运行多长时间:
%%timeit
def rules(row):
if row['sepal_length'] < 5.1:
return 0
elif row['sepal_width'] > 3.3:
if row['sepal_length'] < 5.8:
return 1
elif row['petal_length'] > 5.1:
return 2
elif (row['sepal_length'] < 6.4) or (row['petal_width'] < 1.3):
if row['petal_length'] < 1.6:
return 3
return 4
return 5
return 6
iris['label'] = iris.apply(rules, 1)
1.43 s ± 115 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
15万行只需要1.43s比之前的水平有了很大的提高,但仍然非常缓慢。
想象一下,如果你需要处理一个由数百万个交易数据或信贷批准组成的数据集,那么每次我们要应用一组规则并将函数应用在一个列时,它将占用14秒以上。运行足够多的列,你一个下午可能就没了。
Pandas.loc[]
如果你熟悉SQL,那么使用.loc[]为新列赋值实际上只是一个带有WHERE条件的UPDATE语句。因此,这应该比将函数应用于每个行或列要好得多。
%%timeit
iris['label'] = 6
iris.loc[iris['sepal_width'] > 3.3, 'label'] = 5
iris.loc[
(iris['sepal_width'] > 3.3) &
((iris['sepal_length'] < 6.4) | (iris['petal_width'] < 1.3)),
'label'] = 4
iris.loc[
(iris['sepal_width'] > 3.3) &
((iris['sepal_length'] < 6.4) | (iris['petal_width'] < 1.3)) &
(iris['petal_length'] < 1.6),
'label'] = 3
iris.loc[
(iris['sepal_width'] > 3.3) &
(iris['petal_length'] > 5.1),
'label'] = 2
iris.loc[
(iris['sepal_width'] > 3.3) &
(iris['sepal_length'] < 5.8),
'label'] = 1
iris.loc[
(iris['sepal_length'] < 5.1),
'label'] = 0
13.3 ms ± 837 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
现在我们只花了前一次的十分之一的时间,这意味着当你在家工作的时候,你没有更多的借口离开办公桌。不过,我们目前只使用pandas内置的函数。尽管pandas为我们提供了一个非常方便的高级接口来与数据表交互,但是通过层层抽象,效率可能会降低。
Numpy.where
Numpy有一个较低级别的接口,允许与n维iterables(即向量、矩阵、张量等)进行更有效的交互。它的方法通常是基于C语言的,当涉及到更复杂的计算时,它使用了优化的算法,使得它比我们重新发明的轮子更快。
根据numpy的官方文件,np.where()接受以下语法:
np.where(condition, return value if True, return value if False)
本质上,这是一种二分,其中条件将被计算为布尔值并相应地返回值。这里的技巧是条件实际上可以是iterable(即布尔ndarray类型)。这意味着我们可以将df['feature']==1作为条件,并将where逻辑编码为:
np.where(
df['feature'] == 1,
'It is one',
'It is not one'
)
所以你可能会问,我们如何用一个像np.where()这样的二分函数来实现上述逻辑呢?答案很简单,但却令人不安。嵌套np.where()
%%timeit
iris['label'] = np.where(
iris['sepal_length'] < 5.1,
0,
np.where(
iris['sepal_width'] > 3.3,
np.where(
iris['sepal_length'] < 5.8,
1,
np.where(
iris['petal_length'] > 5.1,
2,
np.where(
(iris['sepal_length'] < 6.4) | (iris['petal_width'] < 1.3),
np.where(
iris['petal_length'] < 1.6,
3,
4
),
5
)
)
),
6
)
)
3.6 ms ± 149 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
恭喜你,你挺过来了。我不能告诉你我花了多少次来计算右括号,但是嘿,这就完成了!我们又从pandas身上砍下了10毫秒。loc[]。然而,这个代码片段是不可维护的,这意味着,它是不可接受的。
Numpy.select
Numpy.select,它与.where不同,它是用来实现多线程逻辑的函数。
np.select(condlist, choicelist, default=0)
它的语法近似于np.where,但第一个参数现在是一个条件列表,它的长度应该与选项的长度相同。使用时要记住一件事np.select是在满足第一个条件后立即选择一个选项。
这意味着,如果超集规则出现在列表中的子集规则之前,那么子集选择将永远不会被选择。具体说来:
condlist = [
df['A'] <= 1,
df['A'] < 1
]
choicelist = ['<=1', '<1']
selection = np.select(condlist, choicelist, default='>1')
因为所有命中df['A']<1的行也将被df['A']<=1捕获,因此没有行最终被标记为'<1'。为了避免这种情况发生,请务必在更具体的规则之前先制定一个不太具体的规则:
condlist = [
df['A'] < 1, # < ───┬ 交换
df['A'] <= 1 # < ───┘
]
choicelist = ['<1', '<=1'] # 记住也要更新这个!
selection = np.select(condlist, choicelist, default='>1')
从上面可以看到,你需要同时更新condlist和choicelsit,以确保代码顺利运行。但说真的,这一步也耗我们自己的时间。通过将其更改为字典,我们将达到大致相同的时间和内存复杂性,但使用更易于维护的代码片段:
%%timeit
rules = {
0: (iris['sepal_length'] < 5.1),
1: (iris['sepal_width'] > 3.3) & (iris['sepal_length'] < 5.8),
2: (iris['sepal_width'] > 3.3) & (iris['petal_length'] > 5.1),
3: (
(iris['sepal_width'] > 3.3) & \
((iris['sepal_length'] < 6.4) | (iris['petal_width'] < 1.3)) & \
(iris['petal_length'] < 1.6)
),
4: (
(iris['sepal_width'] > 3.3) & \
((iris['sepal_length'] < 6.4) | (iris['petal_width'] < 1.3))
),
5: (iris['sepal_width'] > 3.3),
}
iris['label'] = np.select(rules.values(), rules.keys(), default=6)
6.29 ms ± 475 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
大约是np.where的一半,但这不仅使你免于对各种嵌套的调试,而且使choicelist发生了变化。之前我已经忘记更新choicelist太多次了,以至于我花了四倍多的时间来调试我的机器学习模型。相信我,np.select和dict。这是非常好的选择
优秀函数
-
Numpy的向量化操作:如果你的代码涉及循环和计算一元函数、二进制函数或对数字序列进行操作的函数。你应该通过将数据转换为numpy-ndarray来重构代码,并充分利用numpy的向量化操作来极大地提高脚本的速度。在Numpy的官方文档中查看一元函数、二元函数或对数字序列进行操作的函数的示例:https://www.pythonlikeyoumeanit.com/Module3_IntroducingNumpy/VectorizedOperations.html#NumPy’s-Mathematical-Functions
-
np.vectorize:不要被这个函数的名字愚弄。这只是一个方便的函数,并不会使代码运行得更快。要使用此函数,首先需要将逻辑编码为可调用函数,然后运行np.vectorize(你的函数)(你的数据系列)。另一个大的缺点是需要将数据帧转换为一维的iterable,以便传递到“矢量化”函数中。结论:如果不方便使用np.vectorize,别使用。
-
numba.njit:现在这是真正的向量化。它试图将任何numpy值移动到尽可能接近C语言,以提高其效率。虽然它可以加速数值计算,但它也将自己限制为数值计算,这意味着没有pandas系列,没有字符串索引,只有具有int、float、datetime、bool和category类型的numpy的ndarray。结论:如果你能够轻松地使用Numpy的ndarray并将逻辑转换为数值计算或仅转换为数值计算,那么它将是一个非常优秀的选择。从这里了解更多:https://numba.pydata.org/numba-doc/dev/user/5minguide.html
结尾
如果可能的话,去争取numba.njit;否则,使用np.select和dict就可以帮助你远航了。记住,每一点改进都会有帮助!
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/

