
一幅图像能顶16x16字!——用于大规模图像缩放识别的变压器(对ICLR 2021年论文的简要回顾)
作者|Stan Kriventsov
编译|Flin
来源|medium
在这篇博文中,我想在不作太多技术细节的情况下,解释其作者提交给2021 ICLR会议的新论文“一张图等于16x16个字:用于大规模图像识别的变压器”的意义(目前为止匿名)。
另一篇文章中,我提供了一个示例,该示例将这种新模型(称为Vision Transformer,视觉变压器)与PyTorch一起用于对标准MNIST数据集进行预测。
自1960年以来深度学习(机器学习利用神经网络有不止一个隐藏层)已经问世,但促使深度学习真正来到了前列的,是2012年的时候AlexNet,一个卷积网络(简单来说,一个网络,首先查找小的图案在图像的每个部分,然后尝试将它们组合成一张整体图片),由Alex Krizhevsky设计,赢得了年度ImageNet图像分类竞赛的冠军。
-
ImageNet图像分类竞赛:https://en.wikipedia.org/wiki/ImageNet
在接下来的几年里,深度计算机视觉技术经历了一场真正的革命,每年都会出现新的卷积体系结构(GoogleNet、ResNet、DenseNet、EfficientNet等),以在ImageNet和其他基准数据集(如CIFAR-10、CIFAR-100)上创下新的精度记录。
下图显示了自2011年以来ImageNet数据集上机器学习模型的最高精度(第一次尝试时正确预测图像所含内容的准确性)的进展情况。
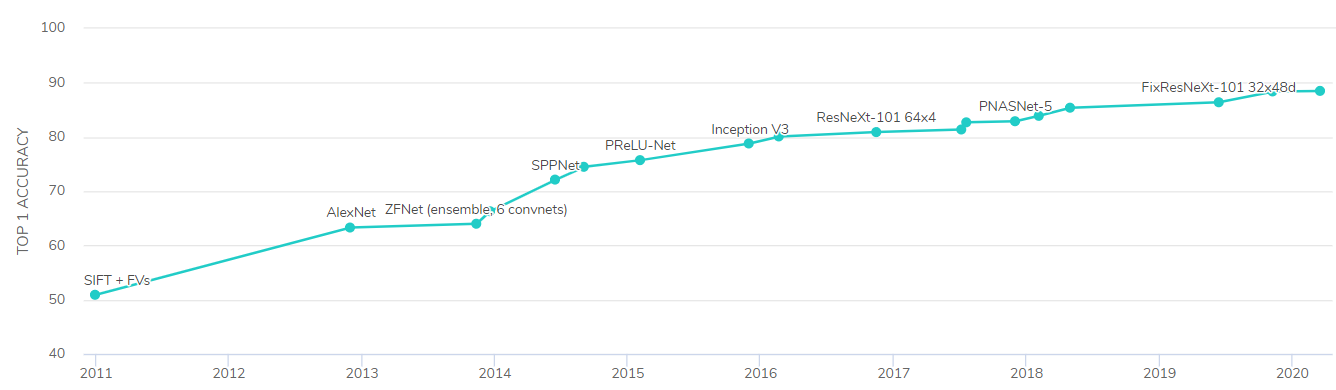
然而,在过去的几年里,深度学习最有趣的发展不是在图像领域,而是在自然语言处理(NLP)中,这是由Ashish Vaswani等人在2017年的论文“注意力是你需要的一切”中首次提出的。
注意力的思想,指的是可训练的权重,模拟输入句子不同部分之间的每个连接的重要性,对NLP的影响类似于计算机视觉中的卷积网络,极大地提高了机器学习模型对各种语言任务(如自然语言理解)的效果还有机器翻译的效果。
注意力之所以对语言数据特别有效,是因为理解人类语言通常需要跟踪长期依赖关系。我们可能会先说“我们到达了纽约”,然后说“城市的天气很好”。对于任何人类读者来说,应该很清楚,最后一句话中的“城市”指的是“纽约”,但对于一个只基于在附近数据(如卷积网络)中找到模式的模型,这种联系可能无法检测。
长期依赖性的问题可以通过使用递归网络来解决,例如LSTMs,在变压器到来之前,LSTMs实际上是NLP中的顶级模型,但即使是那些模型,也很难匹配特定的单词。
变压器中的全局注意力模型衡量了文本中任意两个单词之间每一个连接的重要性,这解释了它们性能的优越之处。对于注意力不那么重要的序列数据类型(例如,日销售额或股票价格等时域数据),递归网络仍然具有很强的竞争力,可能仍是最佳选择。
虽然在NLP等序列模型中,远距离对象之间的依赖关系可能具有特殊的意义,但在图像任务中,它们肯定不能被忽略。要形成一幅完整的图画,通常需要了解图像的各个部分。
到目前为止,注意力模型在计算机视觉中一直表现不佳的原因在于缩放它们的难度(它们的缩放比例为N²,因此1000x1000图像的像素之间的全套注意力权重将具有一百万项)。
也许更重要的是,事实上,与文本中的单词相反,图片中的各个像素本身并不是很有意义,因此通过注意力将它们连接起来并没有太大作用。
这篇新论文提出了一种方法,即不关注像素点,而是关注图像的小块区域(可能是标题中的16x16,尽管最佳块尺寸实际上取决于模型的图像尺寸和内容)。
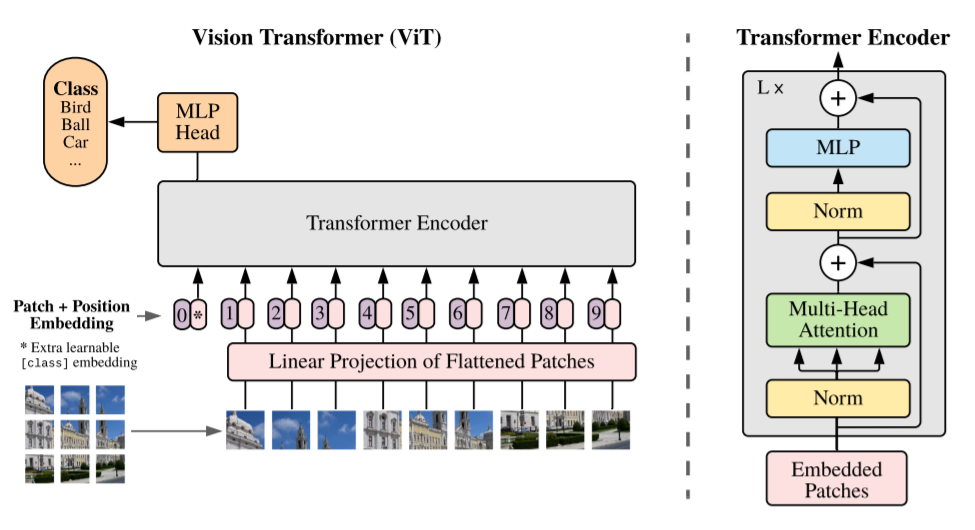
上面的图片(摘自论文)显示了视觉变压器的工作方式。
通过使用线性投影矩阵将输入图像中的每个色块展平,并向其添加位置嵌入(学习的数值,其中包含有关该色块最初在图像中的位置的信息)。这是必需的,因为变压器会处理所有输入,而不考虑其顺序,因此拥有此位置信息有助于模型正确评估注意力权重。额外的类标记连接到输入(图像中的位置0),作为要在分类任务中预测的类的占位符。
类似于2017版,该变压器编码器由多个注意力,规范化和完全连接的层组成,这些层具有残差(跳过)连接,如图中的右半部分所示。
在每个关注区域中,多个头部可以捕获不同的连接模式。如果你有兴趣了解有关变压器的更多信息,我建议阅读Jay Alammar撰写的这篇出色的文章。
输出端完全连接的MLP头可提供所需的类别预测。当然,与当今一样,主模型可以在大型图像数据集上进行预训练,然后可以通过标准的迁移学习方法将最终的MLP头微调为特定任务。
新模型的一个特点是,尽管根据本文的研究,它比卷积方法更有效地以更少的计算量获得相同的预测精度,但随着它接受越来越多的数据训练,其性能似乎在不断提高,这比其他模型更甚。
这篇文章的作者在一个包含3亿的私有googlejft-300M数据集上训练了视觉变换器图像,从而在许多基准测试中都获得了最先进的准确性。人们可以期待这个预先训练过的模型很快就会发布出来,以便我们都可以试用。
看到神经注意力在计算机视觉领域的新应用,实在太令人兴奋了!希望在未来的几年里,在这种发展的基础上,能取得更大的进步!
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/

