
一种超参数优化技术-Hyperopt
作者|GUEST BLOG
编译|VK
来源|Analytics Vidhya
介绍
在机器学习项目中,你需要遵循一系列步骤,直到你达到你的目标,你必须执行的步骤之一就是对你选择的模型进行超参数优化。此任务总是在模型选择过程之后完成(选择性能优于其他模型的最佳模型)。
什么是超参数优化?
在定义超参数优化之前,你需要了解什么是超参数。简言之,超参数是用来控制学习过程的不同参数值,对机器学习模型的性能有显著影响。
随机森林算法中超参数的例子是估计器的数目(n_estimators)、最大深度(max_depth)和准则。这些参数是可调的,可以直接影响训练模型的好坏。
超参数优化就是寻找合适的超参数值组合,以便在合理的时间内实现对数据的最大性能。它对机器学习算法的预测精度起着至关重要的作用。因此,超参数优化被认为是建立机器学习模型中最困难的部分。
大多数机器学习算法都带有默认的超参数值。默认值在不同类型的机器学习项目中并不总是表现良好,这就是为什么你需要优化它们,以获得最佳性能的正确组合。
好的超参数可以使一个算法发光。
有一些优化超参数的常用策略:
(a) 网格搜索
这是一种广泛使用的传统方法,它通过执行超参数调整来确定给定模型的最佳值。网格搜索通过在模型中尝试所有可能的参数组合来工作,这意味着执行整个搜索将花费大量时间,这可能会导致计算成本非常高。
注意:你可以在这里学习如何实现网格搜索:https://github.com/Davisy/Hyperparameter-Optimization-Techniques/blob/master/GridSearchCV .ipynb
(b) 随机搜索
在超参数值的随机组合用于为构建的模型寻找最佳解决方案时,这种方法的工作方式不同。随机搜索的缺点是有时会漏掉搜索空间中的重要点(值)。
注意:你可以在这里了解更多实现随机搜索的方法:https://github.com/Davisy/Hyperparameter-Optimization-Techniques/blob/master/RandomizedSearchCV.ipynb
超参数优化技术
在本系列文章中,我将向你介绍不同的高级超参数优化技术/方法,这些技术/方法可以帮助你获得给定模型的最佳参数。我们将研究以下技术。
- Hyperopt
- Scikit Optimize
- Optuna
在本文中,我将重点介绍Hyperopt的实现。
什么是Hyperopt
Hyperopt是一个强大的python库,用于超参数优化,由jamesbergstra开发。Hyperopt使用贝叶斯优化的形式进行参数调整,允许你为给定模型获得最佳参数。它可以在大范围内优化具有数百个参数的模型。
Hyperopt的特性
Hyperopt包含4个重要的特性,你需要知道,以便运行你的第一个优化。
(a) 搜索空间
hyperopt有不同的函数来指定输入参数的范围,这些是随机搜索空间。选择最常用的搜索选项:
- hp.choice(label, options)-这可用于分类参数,它返回其中一个选项,它应该是一个列表或元组。示例:hp.choice(“criterion”, [“gini”,”entropy”,])
- hp.randint(label, upper)-可用于整数参数,它返回范围(0,upper)内的随机整数。示例:hp.randint(“max_features”,50)
- hp.uniform(label, low, high)-它返回一个介于low和high之间的值。示例:hp.uniform(“max_leaf_nodes”,1,10)
你可以使用的其他选项包括:
- hp.normal(label, mu, sigma)-这将返回一个实际值,该值服从均值为mu和标准差为sigma的正态分布
- hp.qnormal(label, mu, sigma, q)-返回一个类似round(normal(mu, sigma) / q) * q的值
- hp.lognormal(label, mu, sigma)-返回exp(normal(mu, sigma))
- hp.qlognormal(label, mu, sigma, q) -返回一个类似round(exp(normal(mu, sigma)) / q) * q的值
你可以在这里了解更多的搜索空间选项:https://github.com/hyperopt/hyperopt/wiki/FMin#21-parameter-expressions
注:每个可优化的随机表达式都有一个标签(例如n_estimators)作为第一个参数。这些标签用于在优化过程中将参数选择返回给调用者。
(b) 目标函数
这是一个最小化函数,它从搜索空间接收超参数值作为输入并返回损失。这意味着在优化过程中,我们使用选定的超参数值训练模型并预测目标特征,然后评估预测误差并将其返回给优化器。优化器将决定要检查哪些值并再次迭代。你将在一个实际例子中学习如何创建一个目标函数。
(c) fmin
fmin函数是对不同的算法集及其超参数进行迭代,然后使目标函数最小化的优化函数。fmin有5个输入是:
-
最小化的目标函数
-
定义的搜索空间
-
使用的搜索算法有随机搜索、TPE(Tree-Parzen估计器)和自适应TPE。
注意:hyperopt.rand.suggest以及hyperopt.tpe.suggest为超参数空间的顺序搜索提供逻辑。
-
最大评估数
-
trials对象(可选)
例子:
from hyperopt import fmin, tpe, hp,Trials
trials = Trials()
best = fmin(fn=lambda x: x ** 2,
space= hp.uniform('x', -10, 10),
algo=tpe.suggest,
max_evals=50,
trials = trials)
print(best)
(d) 试验对象
Trials对象用于保存所有超参数、损失和其他信息,这意味着你可以在运行优化后访问它们。此外,trials 可以帮助你保存和加载重要信息,然后继续优化过程。(你将在实际示例中了解更多信息)。
from hyperopt import Trials
trials = Trials()
在理解了Hyperopt的重要特性之后,下面将介绍Hyperopt的使用方法。
-
初始化要搜索的空间。
-
定义目标函数。
-
选择要使用的搜索算法。
-
运行hyperopt函数。
-
分析测试对象中存储的评估输出。
实践中的Hyperpot
现在你已经了解了Hyperopt的重要特性,在这个实际示例中,我们将使用移动价格数据集,任务是创建一个模型,预测移动设备的价格是0(低成本)或1(中等成本)或2(高成本)或3(非常高成本)。
安装Hyperopt
你可以从PyPI安装hyperopt。
pip install hyperopt
然后导入重要的软件包
# 导入包
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn import metrics
from sklearn.model_selection import cross_val_score
from sklearn.preprocessing import StandardScaler
from hyperopt import tpe, hp, fmin, STATUS_OK,Trials
from hyperopt.pyll.base import scope
import warnings
warnings.filterwarnings("ignore")
数据集
让我们从数据目录加载数据集。以获取有关此数据集的更多信息:https://www.kaggle.com/iabhishekofficial/mobile-price-classification?select=train.csv
# 加载数据
data = pd.read_csv("data/mobile_price_data.csv")
检查数据集的前五行。
# 读取数据
data.head()
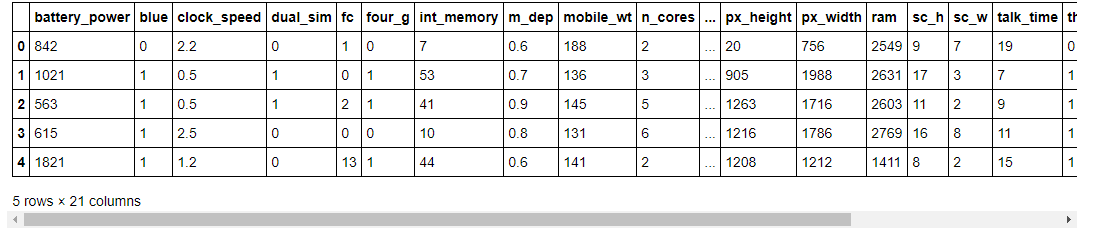
如你所见,在我们的数据集中,我们有不同的数值特征。
让我们观察一下数据集的形状。
# 显示形状
data.shape
(2000, 21)
在这个数据集中,我们有2000行和21列。现在让我们了解一下这个数据集中的特征列表。
#显示列表
list(data.columns)
[‘battery_power’, ‘blue’, ‘clock_speed’, ‘dual_sim’, ‘fc’, ‘four_g’, ‘int_memory’, ‘m_dep’, ‘mobile_wt’, ‘n_cores’, ‘pc’, ‘px_height’, ‘px_width’, ‘ram’, ‘sc_h’, ‘sc_w’, ‘talk_time’, ‘three_g’, ‘touch_screen’, ‘wifi’, ‘price_range’]
你可以在这里找到每个列名的含义:https://www.kaggle.com/iabhishekofficial/mobile-price-classification
将数据集分解为目标特征和独立特征
这是一个分类问题,我们将从数据集中分离出目标特征和独立特征。我们的目标是价格区间。
# 将数据拆分为特征和目标
X = data.drop("price_range", axis=1).values
y = data.price_range.values
预处理数据集
然后使用scikit-learn中的StandardScaler方法对独立特征进行标准化。
# 标准化特征变量
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
为优化定义参数空间
我们将使用随机森林算法的三个超参数,即n_estimators、max_depth和criterion。
space = {
"n_estimators": hp.choice("n_estimators", [100, 200, 300, 400,500,600]),
"max_depth": hp.quniform("max_depth", 1, 15,1),
"criterion": hp.choice("criterion", ["gini", "entropy"]),
}
我们在上面选择的超参数中设置了不同的值。然后定义目标函数。
定义最小化函数(目标函数)
我们的最小化函数称为超参数调整,优化其超参数的分类算法是随机森林。我使用交叉验证来避免过拟合,然后函数将返回一个损失值及其状态。
# 定义目标函数
def hyperparameter_tuning(params):
clf = RandomForestClassifier(**params,n_jobs=-1)
acc = cross_val_score(clf, X_scaled, y,scoring="accuracy").mean()
return {"loss": -acc, "status": STATUS_OK}
注意:记住hyperopt最小化了函数,所以我在acc中添加了负号:
微调模型
最后,首先实例化Trial 对象,对模型进行微调,然后用其超参数值打印出最佳损失。
# 初始化Trial 对象
trials = Trials()
best = fmin(
fn=hyperparameter_tuning,
space = space,
algo=tpe.suggest,
max_evals=100,
trials=trials
)
print("Best: {}".format(best))
100%|█████████████████████████████████████████████████████████| 100/100 [10:30<00:00, 6.30s/trial, best loss: -0.8915] Best: {‘criterion’: 1, ‘max_depth’: 11.0, ‘n_estimators’: 2}.
在进行超参数优化后,损失为-0.8915,使用随机森林分类器中的n_estimators=300,max_depth=11,criterian=“entropy”,模型性能的准确率为89.15%。
使用trials对象分析结果
trials对象可以帮助我们检查在实验期间计算的所有返回值。
(一)trials.results
这显示搜索期间“objective”返回的词典列表。
trials.results
[{‘loss’: -0.8790000000000001, ‘status’: ‘ok’}, {‘loss’: -0.877, ‘status’: ‘ok’}, {‘loss’: -0.768, ‘status’: ‘ok’}, {‘loss’: -0.8205, ‘status’: ‘ok’}, {‘loss’: -0.8720000000000001, ‘status’: ‘ok’}, {‘loss’: -0.883, ‘status’: ‘ok’}, {‘loss’: -0.8554999999999999, ‘status’: ‘ok’}, {‘loss’: -0.8789999999999999, ‘status’: ‘ok’}, {‘loss’: -0.595, ‘status’: ‘ok’},…….]
(二)trials.losses()
这显示了一个损失列表
trials.losses()
[-0.8790000000000001, -0.877, -0.768, -0.8205, -0.8720000000000001, -0.883, -0.8554999999999999, -0.8789999999999999, -0.595, -0.8765000000000001, -0.877, ………]
(三)trials.statuses()
这将显示状态字符串的列表。
trials.statuses()
[‘ok’, ‘ok’, ‘ok’, ‘ok’, ‘ok’, ‘ok’, ‘ok’, ‘ok’, ‘ok’, ‘ok’, ‘ok’, ‘ok’, ‘ok’, ‘ok’, ‘ok’, ‘ok’, ‘ok’, ‘ok’, ‘ok’, ……….]
注:这个试验对象可以保存,传递到内置的绘图例程,或者用你自己的自定义代码进行分析。
结尾
恭喜你,你已经完成了这篇文章
你可以在此处下载本文中使用的数据集和笔记本:https://github.com/Davisy/Hyperparameter-Optimization-technologies
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/

