
基于RNN自编码器的离群点检测
作者|David Woroniuk
编译|VK
来源|Towards Data Science
什么是异常
异常,通常称为异常值,是指数据中不符合数据系列总体行为的数据点、数据序列或模式。因此,异常检测就是检测不符合更广泛数据中的模式的数据点或序列的任务。
对异常数据的有效检测和删除对于许多业务功能非常有用,如检测嵌入在网站中的破损链接、互联网流量峰值或股价的剧烈变化。将这些现象标记为异常值,或制定预先计划的应对措施,可以节省企业的时间和资金。
异常类型
通常情况下,异常数据可以分为三类:加性异常值、时间变化异常值或水平变化异常值。
加性异常值的特点是价值突然大幅增加或减少,这可能是由外生或内生因素驱动的。加性异常值的例子可能是由于电视节目的出现而导致网站流量的大幅增长(外因),或者由于强劲的季度业绩而导致股票交易量的短期增长(内因)。
时间变化异常值的特点是一个短序列,它不符合数据中更广泛的趋势。例如,如果一个网站服务器崩溃,在一系列数据点上,网站流量将降为零,直到服务器重新启动,此时流量将恢复正常。
水平变化异常值是商品市场的常见现象,因为商品市场对电力的高需求与恶劣的天气条件有着内在的联系。因此我们可以观察到夏季和冬季电价之间的“水平变化”,这是由天气驱动的需求变化和可再生能源发电变化造成的。
什么是自编码器
自动编码器是设计用来学习给定输入的低维表示的神经网络。自动编码器通常由两个部分组成:一个编码器学习将输入数据映射到低维表示,另一个解码器学习将表示映射回输入数据。
由于这种结构,编码器网络迭代学习一个有效的数据压缩函数,该函数将数据映射到低维表示。经过训练,译码器能够成功地重建原始输入数据,重建误差(译码器产生的输入和重构输出之间的差异)是整个训练过程的目标函数。
实现
既然我们了解了自动编码器模型的底层架构,我们就可以开始实现该模型了。
第一步是安装我们将使用的库、包和模块:
# 数据处理:
import numpy as np
import pandas as pd
from datetime import date, datetime
# RNN自编码器:
from tensorflow import keras
from tensorflow.keras import layers
# 绘图:
!pip install chart-studio
import plotly.graph_objects as go
其次,我们需要获得一些数据进行分析。本文使用历史加密软件包获取2013年6月6日至今的比特币历史数据。下面的代码还生成每日比特币回报率和日内价格波动率,然后删除任何丢失的数据行并返回数据帧的前5行。
# 导入 Historic Crypto 包:
!pip install Historic-Crypto
from Historic_Crypto import HistoricalData
# 获取比特币数据,计算收益和日内波动:
dataset = HistoricalData(start_date = '2013-06-06',ticker = 'BTC').retrieve_data()
dataset['Returns'] = dataset['Close'].pct_change()
dataset['Volatility'] = np.abs(dataset['Close']- dataset['Open'])
dataset.dropna(axis = 0, how = 'any', inplace = True)
dataset.head()
既然我们已经获得了一些数据,我们应该直观地扫描每个序列中潜在的异常值。下面的plot_dates_values函数可以迭代绘制数据帧中包含的每个序列。
def plot_dates_values(data_timestamps, data_plot):
'''
这个函数提供输入序列的平面图
Arguments:
data_timestamps: 与每个数据实例关联的时间戳。
data_plot: 要绘制的数据序列。
Returns:
fig: 用滑块和按钮显示序列的图形。
'''
fig = go.Figure()
fig.add_trace(go.Scatter(x = data_timestamps, y = data_plot,
mode = 'lines',
name = data_plot.name,
connectgaps=True))
fig.update_xaxes(
rangeslider_visible=True,
rangeselector=dict(
buttons=list([
dict(count=1, label="YTD", step="year", stepmode="todate"),
dict(count=1, label="1 Years", step="year", stepmode="backward"),
dict(count=2, label="2 Years", step="year", stepmode="backward"),
dict(count=3, label="3 Years", step="year", stepmode="backward"),
dict(label="All", step="all")
])))
fig.update_layout(
title=data_plot.name,
xaxis_title="Date",
yaxis_title="",
font=dict(
family="Arial",
size=11,
color="#7f7f7f"
))
return fig.show()
我们现在可以反复调用上述函数,生成比特币的成交量、收盘价、开盘价、波动率和收益率曲线图。
plot_dates_values(dataset.index, dataset['Volume'])
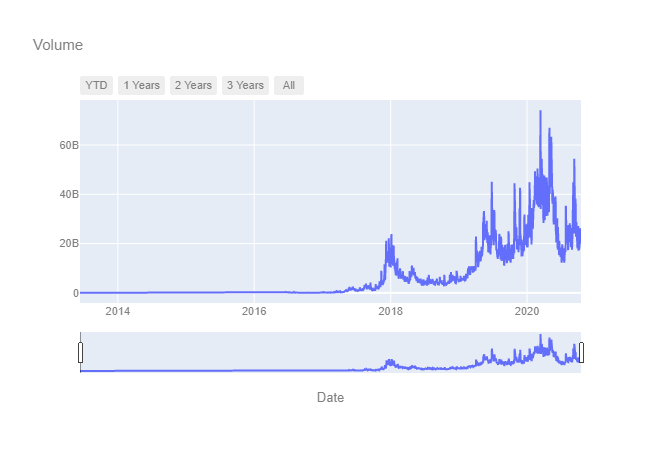
值得注意的是,2020年出现了一些交易量的峰值,调查这些峰值是否异常或预示着更广泛的序列可能是有用的。
plot_dates_values(dataset.index, dataset['Close'])
.png)
2018年收盘价出现了一个明显的上涨,随后下跌至技术支撑水平。然而,一个向上的趋势在整个数据中普遍存在。
plot_dates_values(dataset.index, dataset['Open'])
.png)
每日开盘价与上述收盘价走势相似。
plot_dates_values(dataset.index, dataset['Volatility'])
.png)
2018年的价格和波动性都很明显。因此,我们可以研究这些波动率峰值是否被自编码器模型视为异常。
plot_dates_values(dataset.index, dataset['Returns'])
.png)
由于收益序列的随机性,我们选择测试比特币日交易量中的异常值,以交易量为特征。
因此,我们可以开始自动编码器模型的数据预处理。数据预处理的第一步是确定训练数据和测试数据之间的适当分割。下面概述的generate_train_test_split功能可以按日期分割训练和测试数据。在调用下面的函数时,将生成两个数据帧,即训练数据和测试数据作为全局变量。
def generate_train_test_split(data, train_end, test_start):
'''
此函数通过使用字符串将数据集分解为训练数据和测试数据。作为'train_end'和'test_start'参数提供的字符串必须是连续的天。
Arguments:
data: 数据分割为训练数据和测试数据。
train_end: 训练数据结束的日期(str)。
test_start: 测试数据开始的日期(str)。
Returns:
training_data: 模型训练中使用的数据(Pandas DataFrame)。
testing_data: 模型测试中使用的数据(panda DataFrame)。
'''
if isinstance(train_end, str) is False:
raise TypeError("train_end argument should be a string.")
if isinstance(test_start, str) is False:
raise TypeError("test_start argument should be a string.")
train_end_datetime = datetime.strptime(train_end, '%Y-%m-%d')
test_start_datetime = datetime.strptime(test_start, '%Y-%m-%d')
while train_end_datetime >= test_start_datetime:
raise ValueError("train_end argument cannot occur prior to the test_start argument.")
while abs((train_end_datetime - test_start_datetime).days) > 1:
raise ValueError("the train_end argument and test_start argument should be seperated by 1 day.")
training_data = data[:train_end]
testing_data = data[test_start:]
print('Train Dataset Shape:',training_data.shape)
print('Test Dataset Shape:',testing_data.shape)
return training_data, testing_data
# 我们现在调用上面的函数,生成训练和测试数据
training_data, testing_data = generate_train_test_split(dataset, '2018-12-31','2019-01-01')
为了提高模型的准确性,我们可以对数据进行“标准化”或缩放。此函数可缩放上面生成的训练数据帧,保存训练平均值和训练标准,以便以后对测试数据进行标准化。
注:对训练和测试数据进行同等级别的缩放是很重要的,否则规模的差异将产生可解释性问题和模型不一致。
def normalise_training_values(data):
'''
这个函数用平均值和标准差对输入值进行规格化。
Arguments:
data: 要标准化的DataFrame列。
Returns:
values: 用于模型训练的归一化数据(numpy数组)。
mean: 训练集mean,用于标准化测试集(float)。
std: 训练集的标准差,用于标准化测试集(float)。
'''
if isinstance(data, pd.Series) is False:
raise TypeError("data argument should be a Pandas Series.")
values = data.to_list()
mean = np.mean(values)
values -= mean
std = np.std(values)
values /= std
print("*"*80)
print("The length of the training data is: {}".format(len(values)))
print("The mean of the training data is: {}".format(mean.round(2)))
print("The standard deviation of the training data is {}".format(std.round(2)))
print("*"*80)
return values, mean, std
# 现在调用上面的函数:
training_values, training_mean, training_std = normalise_training_values(training_data['Volume'])
正如我们在上面所说的normalise_training_values函数,我们现在有一个numpy数组,其中包含称为training_values的标准化训练数据,我们已经将training_mean和training_std存储为全局变量,用于标准化测试集。
我们现在可以开始生成一系列序列,这些序列可以用来训练自动编码器模型。我们定义窗口大小30,提供一个形状的3D训练数据(2004,30,1):
# 定义每个序列的时间步数:
TIME_STEPS = 30
def generate_sequences(values, time_steps = TIME_STEPS):
'''
这个函数生成要传递给模型的长度序列'TIME_STEPS'。
Arguments:
values: 生成序列(numpy数组)的标准化值。
time_steps: 序列的长度(int)。
Returns:
train_data: 用于模型训练的3D数据(numpy array)。
'''
if isinstance(values, np.ndarray) is False:
raise TypeError("values argument must be a numpy array.")
if isinstance(time_steps, int) is False:
raise TypeError("time_steps must be an integer object.")
output = []
for i in range(len(values) - time_steps):
output.append(values[i : (i + time_steps)])
train_data = np.expand_dims(output, axis =2)
print("Training input data shape: {}".format(train_data.shape))
return train_data
# 现在调用上面的函数生成x_train:
x_train = generate_sequences(training_values)
现在我们已经完成了训练数据的处理,我们可以定义自动编码器模型,然后将模型拟合到训练数据上。define_model函数使用训练数据形状定义适当的模型,返回自编码器模型和自编码器模型的摘要。
def define_model(x_train):
'''
这个函数使用x_train的维度来生成RNN模型。
Arguments:
x_train: 用于模型训练的3D数据(numpy array)。
Returns:
model: 模型架构(Tensorflow对象)。
model_summary: 模型架构的摘要。
'''
if isinstance(x_train, np.ndarray) is False:
raise TypeError("The x_train argument should be a 3 dimensional numpy array.")
num_steps = x_train.shape[1]
num_features = x_train.shape[2]
keras.backend.clear_session()
model = keras.Sequential(
[
layers.Input(shape=(num_steps, num_features)),
layers.Conv1D(filters=32, kernel_size = 15, padding = 'same', data_format= 'channels_last',
dilation_rate = 1, activation = 'linear'),
layers.LSTM(units = 25, activation = 'tanh', name = 'LSTM_layer_1',return_sequences= False),
layers.RepeatVector(num_steps),
layers.LSTM(units = 25, activation = 'tanh', name = 'LSTM_layer_2', return_sequences= True),
layers.Conv1D(filters = 32, kernel_size = 15, padding = 'same', data_format = 'channels_last',
dilation_rate = 1, activation = 'linear'),
layers.TimeDistributed(layers.Dense(1, activation = 'linear'))
]
)
model.compile(optimizer=keras.optimizers.Adam(learning_rate = 0.001), loss = "mse")
return model, model.summary()
随后,model_fit函数在内部调用define_model函数,然后向模型提供epochs、batch_size和validation_loss参数。然后调用此函数,开始模型训练过程。
def model_fit():
'''
这个函数调用上面的'define_model()'函数,然后根据x_train数据对模型进行训练。
Arguments:
N/A.
Returns:
model: 训练好的模型。
history: 模型如何训练的摘要(训练错误,验证错误)。
'''
# 在x_train上调用上面的define_model函数:
model, summary = define_model(x_train)
history = model.fit(
x_train,
x_train,
epochs=400,
batch_size=128,
validation_split=0.1,
callbacks=[keras.callbacks.EarlyStopping(monitor="val_loss",
patience=25,
mode="min",
restore_best_weights=True)])
return model, history
# 调用上面的函数,生成模型和模型的历史:
model, history = model_fit()
一旦对模型进行了训练,就必须绘制训练和验证损失曲线,以了解模型是否存在偏差(欠拟合)或方差(过拟合)。这可以通过调用下面的plot_training_validation_loss函数来观察。
def plot_training_validation_loss():
'''
这个函数绘制了训练模型的训练和验证损失曲线,可以对欠拟合或过拟合进行可视化诊断。
Arguments:
N/A.
Returns:
fig:模型的训练损失和验证的可视化表示
'''
training_validation_loss = pd.DataFrame.from_dict(history.history, orient='columns')
fig = go.Figure()
fig.add_trace(go.Scatter(x = training_validation_loss.index, y = training_validation_loss["loss"].round(6),
mode = 'lines',
name = 'Training Loss',
connectgaps=True))
fig.add_trace(go.Scatter(x = training_validation_loss.index, y = training_validation_loss["val_loss"].round(6),
mode = 'lines',
name = 'Validation Loss',
connectgaps=True))
fig.update_layout(
title='Training and Validation Loss',
xaxis_title="Epoch",
yaxis_title="Loss",
font=dict(
family="Arial",
size=11,
color="#7f7f7f"
))
return fig.show()
# 调用上面的函数:
plot_training_validation_loss()
.png)
值得注意的是,训练和验证损失曲线在整个图表中都在收敛,验证损失仍然略大于训练损失。在给定形状误差和相对误差的情况下,我们可以确定自动编码器模型不存在欠拟合或过拟合。
现在,我们可以定义重建误差,这是自动编码器模型的核心原理之一。重建误差表示为训练损失,重建误差阈值为训练损失的最大值。因此,在计算试验误差时,任何大于训练损失最大值的值都可以视为异常值。
def reconstruction_error(x_train):
'''
这个函数计算重建误差,并显示训练平均绝对误差的直方图
Arguments:
x_train: 用于模型训练的3D数据(numpy array)。
Returns:
fig: 训练MAE分布的可视化图。
'''
if isinstance(x_train, np.ndarray) is False:
raise TypeError("x_train argument should be a numpy array.")
x_train_pred = model.predict(x_train)
global train_mae_loss
train_mae_loss = np.mean(np.abs(x_train_pred - x_train), axis = 1)
histogram = train_mae_loss.flatten()
fig =go.Figure(data = [go.Histogram(x = histogram,
histnorm = 'probability',
name = 'MAE Loss')])
fig.update_layout(
title='Mean Absolute Error Loss',
xaxis_title="Training MAE Loss (%)",
yaxis_title="Number of Samples",
font=dict(
family="Arial",
size=11,
color="#7f7f7f"
))
print("*"*80)
print("Reconstruction error threshold: {} ".format(np.max(train_mae_loss).round(4)))
print("*"*80)
return fig.show()
# 调用上面的函数:
reconstruction_error(x_train)
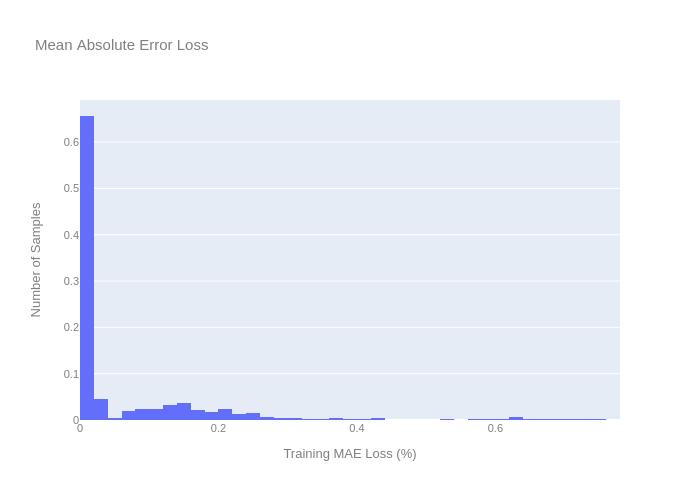
在上面,我们将training_mean和training_std保存为全局变量,以便将它们用于缩放测试数据。我们现在定义normalise_testing_values函数来缩放测试数据。
def normalise_testing_values(data, training_mean, training_std):
'''
该函数使用训练平均值和标准差对测试数据进行归一化,生成一个测试值的numpy数组。
Arguments:
data: 使用的数据(panda DataFrame列)
mean: 训练集平均值(浮点数)。
std: 训练集标准差(float)。
Returns:
values: 数组 (numpy array).
'''
if isinstance(data, pd.Series) is False:
raise TypeError("data argument should be a Pandas Series.")
values = data.to_list()
values -= training_mean
values /= training_std
print("*"*80)
print("The length of the testing data is: {}".format(data.shape[0]))
print("The mean of the testing data is: {}".format(data.mean()))
print("The standard deviation of the testing data is {}".format(data.std()))
print("*"*80)
return values
随后,在testing_data的Volume列上调用此函数。因此,test_value被具体化为numpy数组。
# 调用上面的函数:
test_value = normalise_testing_values(testing_data['Volume'], training_mean, training_std)
在此基础上,定义了生成测试损失函数,计算了重构数据与测试数据之间的差异。如果任何值大于训练最大损失值,则将其存储在全局异常列表中。
def generate_testing_loss(test_value):
'''
这个函数使用模型来预测测试集中的异常情况。此外,该函数生成“异常”全局变量,包含由RNN识别的异常值。
Arguments:
test_value: 测试的数组(numpy数组)。
Returns:
fig: 训练MAE分布的可视化图。
'''
x_test = generate_sequences(test_value)
print("*"*80)
print("Test input shape: {}".format(x_test.shape))
x_test_pred = model.predict(x_test)
test_mae_loss = np.mean(np.abs(x_test_pred - x_test), axis = 1)
test_mae_loss = test_mae_loss.reshape((-1))
global anomalies
anomalies = (test_mae_loss >= np.max(train_mae_loss)).tolist()
print("Number of anomaly samples: ", np.sum(anomalies))
print("Indices of anomaly samples: ", np.where(anomalies))
print("*"*80)
histogram = test_mae_loss.flatten()
fig =go.Figure(data = [go.Histogram(x = histogram,
histnorm = 'probability',
name = 'MAE Loss')])
fig.update_layout(
title='Mean Absolute Error Loss',
xaxis_title="Testing MAE Loss (%)",
yaxis_title="Number of Samples",
font=dict(
family="Arial",
size=11,
color="#7f7f7f"
))
return fig.show()
# 调用上面的函数:
generate_testing_loss(test_value)
此外,还介绍了MAE的分布,并与MAE的直接损失进行了比较。
.png)
最后,异常值在下面直观地表示出来。
def plot_outliers(data):
'''
这个函数决定了时间序列中离群点的位置,这些离群点被依次绘制出来。
Arguments:
data: 初始数据集(Pandas DataFrame)。
Returns:
fig: 由RNN确定的序列中出现的异常值的可视化表示。
'''
outliers = []
for data_idx in range(TIME_STEPS -1, len(test_value) - TIME_STEPS + 1):
time_series = range(data_idx - TIME_STEPS + 1, data_idx)
if all([anomalies[j] for j in time_series]):
outliers.append(data_idx + len(training_data))
outlying_data = data.iloc[outliers, :]
cond = data.index.isin(outlying_data.index)
no_outliers = data.drop(data[cond].index)
fig = go.Figure()
fig.add_trace(go.Scatter(x = no_outliers.index, y = no_outliers["Volume"],
mode = 'markers',
name = no_outliers["Volume"].name,
connectgaps=False))
fig.add_trace(go.Scatter(x = outlying_data.index, y = outlying_data["Volume"],
mode = 'markers',
name = outlying_data["Volume"].name + ' Outliers',
connectgaps=False))
fig.update_xaxes(rangeslider_visible=True)
fig.update_layout(
title='Detected Outliers',
xaxis_title=data.index.name,
yaxis_title=no_outliers["Volume"].name,
font=dict(
family="Arial",
size=11,
color="#7f7f7f"
))
return fig.show()
# 调用上面的函数:
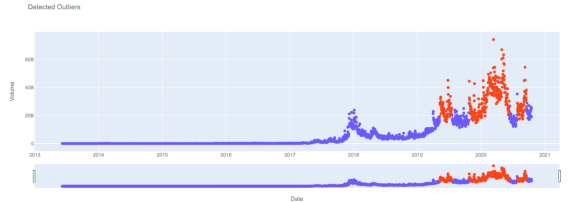
plot_outliers(dataset)
以自动编码器模型为特征的边远数据用橙色表示,而一致性数据用蓝色表示。
.png)
我们可以看到,2020年比特币交易量数据的很大一部分被认为是异常的——可能是由于Covid-19推动的零售交易活动增加?
尝试自动编码器参数和新的数据集,看看你是否能在比特币收盘价中发现任何异常,或者使用历史加密库下载不同的加密货币!
原文链接:https://towardsdatascience.com/outlier-detection-with-rnn-autoencoders-b82e2c230ed9
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/

