
用遗传算法优化垃圾收集策略
作者|Andrew Kuo
编译|VK
来源|Towards Data Science
遗传算法是一个优化技术,在本质上类似于进化过程。这可能是一个粗略的类比,但如果你眯着眼睛看,达尔文的自然选择确实大致上类似于一个优化任务,其目的是制造出完全适合在其环境中繁衍生息的有机体。
在本文中,我将展示如何在Python中实现一个遗传算法,在几个小时内“进化”一个收集垃圾的机器人。

背景
我所遇到的遗传算法原理最好的教程来自Melanie Mitchell写的一本关于复杂系统的好书《Complexity: A Guided Tour》。
在其中一个章节中,Mitchell介绍了一个名叫Robby的机器人,他在生活中的唯一目的是捡垃圾,并描述了如何使用GA优化Robby的控制策略。下面我将解释我解决这个问题的方法,并展示如何在Python中实现该算法。有一些很好的包可以用来构造这类算法(比如DEAP),但是在本教程中,我将只使用基本Python、Numpy和TQDM(可选)。
虽然这只是一个玩具的例子,但GAs在许多实际应用中都有使用。作为一个数据科学家,我经常用它们来进行超参数优化和模型选择。虽然GAs的计算成本很高,但GAs允许我们并行地探索搜索空间的多个区域,并且在计算梯度时是一个很好的选择。
问题描述
一个名为Robby的机器人生活在一个充满垃圾的二维网格世界中,周围有4堵墙(如下图所示)。这个项目的目标是发展一个最佳的控制策略,使他能够有效地捡垃圾,而不是撞墙。
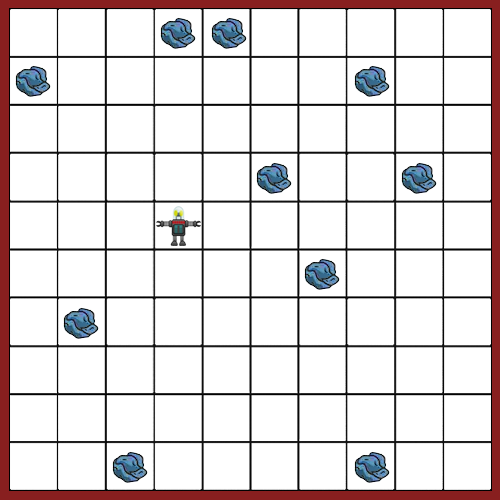
Robby只能看到他周围上下左右四个方块以及他所在的方块,每个方块有3个选择,空的,有垃圾,或者是一面墙。因此,Robby有3⁵=243种不同的情况。Robby可以执行7种不同的动作:上下左右的移动(4种)、随机移动、捡拾垃圾或静止不动。
因此,Robby的控制策略可以编码为一个“DNA”字符串,由0到6之间的243位数字组成(对应于Robby在243种可能的情况下应该采取的行动)。
方法
任何GA的优化步骤如下:
-
生成问题初始随机解的“种群”
-
个体的“拟合度”是根据它解决问题的程度来评估的
-
最合适的解决方案进行“繁殖”并将“遗传”物质传递给下一代的后代
-
重复第2步和第3步,直到我们得到一组优化的解决方案
在我们的任务中,你创建了第一代Robbys初始化为随机DNA字符串(对应于随机控制策略)。然后模拟让这些机器人在随机分配的网格世界中运行,并观察它们的性能。
拟合度
机器人的拟合度取决于它在n次移动中捡到多少垃圾,以及它撞到墙上多少次。在我们的例子中,机器人每捡到一块垃圾就给它10分,每次它撞到墙上就减去5分。然后,这些机器人以它们的拟合度相关的概率进行“交配”(即,捡起大量垃圾的机器人更有可能繁衍后代),新一代机器人诞生了。
交配
有几种不同的方法可以实现“交配”。在Mitchell的版本中,她将父母的两条DNA链随机拼接,然后将它们连接在一起,为下一代创造一个孩子。在我的实现中,我从每一个亲本中随机分配每个基因(即,对于243个基因中的每一个,我掷硬币决定遗传谁的基因)。
例如使用我的方法,在前10个基因里,父母和孩子可能的基因如下:
Parent 1: 1440623161
Parent 2: 2430661132
Child: 2440621161
突变
我们用这个算法复制的另一个自然选择的概念是“变异”。虽然一个孩子的绝大多数基因都是从父母那里遗传下来的,但我也建立了基因突变的小可能性(即随机分配)。这种突变率使我们能够探索新的可能。
Python实现
第一步是导入所需的包并为此任务设置参数。我已经选择了这些参数作为起点,但是它们可以调整,我鼓励你可以尝试调整。
"""
导入包
"""
import numpy as np
from tqdm.notebook import tqdm
"""
设置参数
"""
# 仿真设置
pop_size = 200 # 每一代机器人的数量
num_breeders = 100 # 每一代能够交配的机器人数量
num_gen = 400 # 总代数
iter_per_sim = 100 # 每个机器人垃圾收集模拟次数
moves_per_iter = 200 # 机器人每次模拟可以做的移动数
# 网格设置
rubbish_prob = 0.5 # 每个格子中垃圾的概率
grid_size = 10 # 0网格大小(墙除外)
# 进化设置
wall_penalty = -5 # 因撞到墙上而被扣除的拟合点
no_rub_penalty = -1 # 在空方块捡垃圾被扣分
rubbish_score = 10 # 捡垃圾可获得积分
mutation_rate = 0.01 # 变异的概率
接下来,我们为网格世界环境定义一个类。我们用标记“o”、“x”和“w”来表示每个单元,分别对应一个空单元、一个带有垃圾的单元和一个墙。
class Environment:
"""
类,用于表示充满垃圾的网格环境。每个单元格可以表示为:
'o': 空
'x': 垃圾
'w': 墙
"""
def __init__(self, p=rubbish_prob, g_size=grid_size):
self.p = p # 单元格是垃圾的概率
self.g_size = g_size # 不包括墙
# 初始化网格并随机分配垃圾
self.grid = np.random.choice(['o','x'], size=(self.g_size+2,self.g_size+2), p=(1 - self.p, self.p))
# 设置外部正方形为墙壁
self.grid[:,[0,self.g_size+1]] = 'w'
self.grid[[0,self.g_size+1], :] = 'w'
def show_grid(self):
# 以当前状态打印网格
print(self.grid)
def remove_rubbish(self,i,j):
# 从指定的单元格(i,j)清除垃圾
if self.grid[i,j] == 'o': # 单元格已经是空
return False
else:
self.grid[i,j] = 'o'
return True
def get_pos_string(self,i,j):
# 返回一个字符串,表示单元格(i,j)中机器人“可见”的单元格
return self.grid[i-1,j] + self.grid[i,j+1] + self.grid[i+1,j] + self.grid[i,j-1] + self.grid[i,j]
接下来,我们创建一个类来表示我们的机器人。这个类包括执行动作、计算拟合度和从一对父机器人生成新DNA的方法。
class Robot:
"""
用于表示垃圾收集机器人
"""
def __init__(self, p1_dna=None, p2_dna=None, m_rate=mutation_rate, w_pen=wall_penalty, nr_pen=no_rub_penalty, r_score=rubbish_score):
self.m_rate = m_rate # 突变率
self.wall_penalty = w_pen # 因撞到墙上而受罚
self.no_rub_penalty = nr_pen # 在空方块捡垃圾的处罚
self.rubbish_score = r_score # 捡垃圾的奖励
self.p1_dna = p1_dna # 父母2的DNA
self.p2_dna = p2_dna # 父母2的DNA
# 生成字典来从场景字符串中查找基因索引
con = ['w','o','x'] # 墙,空,垃圾
self.situ_dict = dict()
count = 0
for up in con:
for right in con:
for down in con:
for left in con:
for pos in con:
self.situ_dict[up+right+down+left+pos] = count
count += 1
# 初始化DNA
self.get_dna()
def get_dna(self):
# 初始化机器人的dna字符串
if self.p1_dna is None:
# 没有父母的时候随机生成DNA
self.dna = ''.join([str(x) for x in np.random.randint(7,size=243)])
else:
self.dna = self.mix_dna()
def mix_dna(self):
# 从父母的DNA生成机器人的DNA
mix_dna = ''.join([np.random.choice([self.p1_dna,self.p2_dna])[i] for i in range(243)])
#添加变异
for i in range(243):
if np.random.rand() > 1 - self.m_rate:
mix_dna = mix_dna[:i] + str(np.random.randint(7)) + mix_dna[i+1:]
return mix_dna
def simulate(self, n_iterations, n_moves, debug=False):
# 仿真垃圾收集
tot_score = 0
for it in range(n_iterations):
self.score = 0 # 拟合度分数
self.envir = Environment()
self.i, self.j = np.random.randint(1,self.envir.g_size+1, size=2) # 随机分配初始位置
if debug:
print('before')
print('start position:',self.i, self.j)
self.envir.show_grid()
for move in range(n_moves):
self.act()
tot_score += self.score
if debug:
print('after')
print('end position:',self.i, self.j)
self.envir.show_grid()
print('score:',self.score)
return tot_score / n_iterations # n次迭代的平均得分
def act(self):
# 根据DNA和机器人位置执行动作
post_str = self.envir.get_pos_string(self.i, self.j) # 机器人当前位置
gene_idx = self.situ_dict[post_str] # 当前位置DNA的相关索引
act_key = self.dna[gene_idx] # 从DNA中读取行动
if act_key == '5':
# 随机移动
act_key = np.random.choice(['0','1','2','3'])
if act_key == '0':
self.mv_up()
elif act_key == '1':
self.mv_right()
elif act_key == '2':
self.mv_down()
elif act_key == '3':
self.mv_left()
elif act_key == '6':
self.pickup()
def mv_up(self):
# 向上移动
if self.i == 1:
self.score += self.wall_penalty
else:
self.i -= 1
def mv_right(self):
# 向右移动
if self.j == self.envir.g_size:
self.score += self.wall_penalty
else:
self.j += 1
def mv_down(self):
# 向下移动
if self.i == self.envir.g_size:
self.score += self.wall_penalty
else:
self.i += 1
def mv_left(self):
# 向左移动
if self.j == 1:
self.score += self.wall_penalty
else:
self.j -= 1
def pickup(self):
# 捡垃圾
success = self.envir.remove_rubbish(self.i, self.j)
if success:
# 成功捡到垃圾
self.score += self.rubbish_score
else:
# 当前方块没有捡到垃圾
self.score += self.no_rub_penalty
最后是运行遗传算法的时候了。在下面的代码中,我们生成一个初始的机器人种群,让自然选择来运行它的过程。我应该提到的是,当然有更快的方法来实现这个算法(例如利用并行化),但是为了本教程的目的,我牺牲了速度来实现清晰。
# 初始种群
pop = [Robot() for x in range(pop_size)]
results = []
# 执行进化
for i in tqdm(range(num_gen)):
scores = np.zeros(pop_size)
# 遍历所有机器人
for idx, rob in enumerate(pop):
# 运行垃圾收集模拟并计算拟合度
score = rob.simulate(iter_per_sim, moves_per_iter)
scores[idx] = score
results.append([scores.mean(),scores.max()]) # 保存每一代的平均值和最大值
best_robot = pop[scores.argmax()] # 保存最好的机器人
# 限制那些能够交配的机器人的数量
inds = np.argpartition(scores, -num_breeders)[-num_breeders:] # 基于拟合度得到顶级机器人的索引
subpop = []
for idx in inds:
subpop.append(pop[idx])
scores = scores[inds]
# 平方并标准化
norm_scores = (scores - scores.min()) ** 2
norm_scores = norm_scores / norm_scores.sum()
# 创造下一代机器人
new_pop = []
for child in range(pop_size):
# 选择拟合度优秀的父母
p1, p2 = np.random.choice(subpop, p=norm_scores, size=2, replace=False)
new_pop.append(Robot(p1.dna, p2.dna))
pop = new_pop
虽然最初大多数机器人不捡垃圾,总是撞到墙上,但几代人之后,我们开始看到一些简单的策略(例如“如果与垃圾在一起,就捡起来”和“如果挨着墙,就不要移到墙里”)。经过几百次的反复,我们只剩下一代不可思议的垃圾收集天才!
结果
下面的图表表明,我们能够在400代机器人种群中“进化”出一种成功的垃圾收集策略。
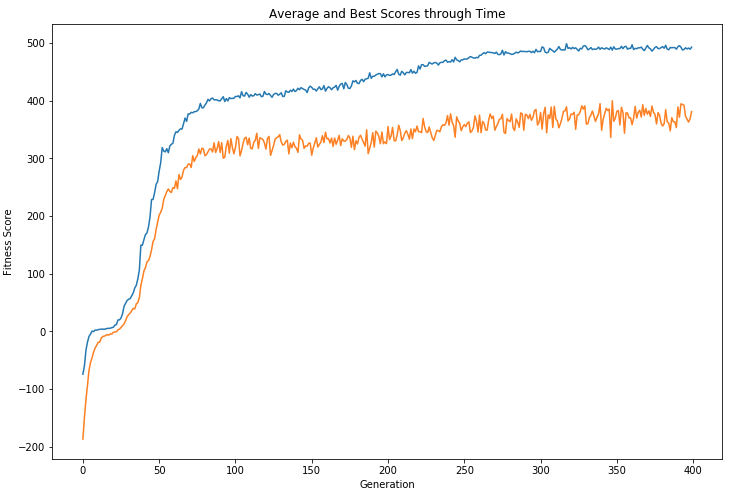
为了评估进化控制策略的质量,我手动创建了一个基准策略,其中包含一些直观合理的规则:
-
如果垃圾在当前方块,捡起来
-
如果在相邻的方块上可以看到垃圾,移到那个方块
-
如果靠近墙,则向相反方向移动
-
否则,随意移动
平均而言,这一基准策略达到了426.9的拟合度,但我们最终的“进化”机器人的平均拟合度为475.9。
战略分析
这种优化方法最酷的一点是,你可以找到反直觉的解决方案。机器人不仅能够学习人类可能设计的合理规则,而且还自发地想出了人类可能永远不会考虑的策略。一种先进的技术出现了,就是使用“标记物”来克服近视和记忆不足。
例如,如果一个机器人现在在一个有垃圾的方块上,并且可以看到东西方方块上的垃圾,那么一个天真的方法就是立即捡起当前方块上的垃圾,然后移动到那个有垃圾的方块。这种策略的问题是,一旦机器人移动(比如向西),他就无法记住东边还有1个垃圾。为了克服这个问题,我们观察了我们的进化机器人执行以下步骤:
-
向西移动(在当前方块留下垃圾作为标记)
-
捡起垃圾往东走(它可以看到垃圾作为标记)
-
把垃圾捡起来,搬到东边去
-
捡起最后一块垃圾
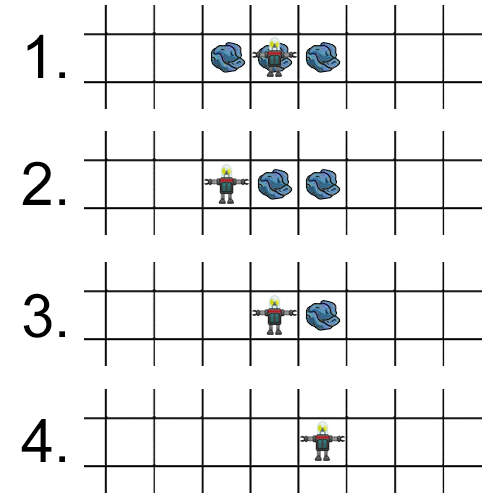
从这种优化中产生的另一个反直觉策略的例子如下所示。OpenAI使用强化学习(一种更复杂的优化方法)教代理玩捉迷藏。我们看到,这些代理一开始学习“人类”策略,但最终学会了新的解决方案。
结论
遗传算法以一种独特的方式将生物学和计算机科学结合在一起,虽然不一定是最快的算法,但在我看来,它们是最美丽的算法之一。
本文中介绍的所有代码都可以在我的Github上找到,还有一个演示Notebook:https://github.com/andrewjkuo/robby-robot-genetic-algorithm。谢谢你的阅读!
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/

