
自然语言处理中的语言模型简介
作者|Devyanshu Shukla
编译|Flin
来源|medium

在这篇文章中,我们将讨论关于语言模型(LM)的所有内容
- 什么是LM
- LM的应用
- 如何生成LM
- LM的评估
介绍
NLP中的语言模型是计算句子(单词序列)的概率或序列中下一个单词的概率的模型。即
句子的概率:

下一个单词的概率:
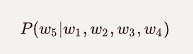
语言模型 v/s 字嵌入
语言模型常常与单词嵌入混淆。主要的区别在于,在语言模型中,单词顺序很重要,因为它试图捕捉单词之间的上下文,而在单词嵌入的情况下,只捕捉语义相似度(https://en.wikipedia.org/wiki/Semantic_similarity) ,因为它是通过预测窗口中的单词来训练的,而不管顺序如何。
语言模型的应用
语言是NLP的主要组成部分,在很多地方都有使用,比如,
- 情感分析
- 问答
- 总结
- 机器翻译
- 语音识别
生成语言模型
有不同的方法来生成语言模型,让我们逐一查看它们。
使用N-grams
N-grams(https://en.wikipedia.org/wiki/N-gram) 是给定语料库中N个单词的序列。对于“I like pizza very much”这句话,bigram将是 ‘I like’, ‘like pizza’, ‘pizza very’ 和 ‘very much’。
比方说,我们有一个句子‘students opened their’,我们想找到它的下一个单词,比如w。使用4-gram,我们可以用下面的方程来表示上面的问题,这个方程返回‘w’是下一个单词的概率。
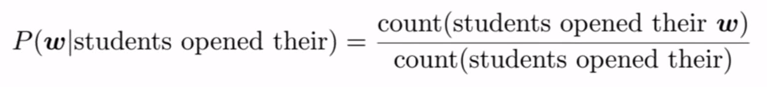
这里,count(X)表示X出现在语料库中的时间。
对于我们的LM,我们必须计算并存储整个语料库中的所有n-grams,随着语料库越来越大,这需要大量的存储空间。假设,我们的LM给出了一个单词列表,以及它们成为下一个单词的概率,现在,我们可以抽样从给定列表中选择一个单词。
可以看出,对于一个N-gram,下一个单词总是取决于句子的最后N-1个单词。因此,当我们添加更多的单词时,句子的上下文和依赖关系就会丢失。
“Today the price of gold per ton,while production of shoe lasts and shoe industry,the bank intervened just after it considered and rejected an IMF demand to rebuild depleted European stocks, sept 30th end primary 76 cts a share.’’
上面的文字是用商业和金融新闻语料库中的N-grams(N=3)生成的,它符合语法知识但不连贯,因为我们只考虑最后两个单词来预测下一个单词。
这种方法也容易受到稀疏性问题的影响,当单词“w”在给定的句子之后从未出现,就会出现稀疏性问题,因此“w”的概率始终为0。
使用神经网络
为了使用神经网络生成LM,我们考虑使用一个固定的窗口,即每一次的单词数都固定。如下图所示,然后以独热向量的形式表示单词,并与词嵌入向量相乘,连接以创建矩阵e。然后将该矩阵展平并通过隐藏层。最后使用softmax函数输出。
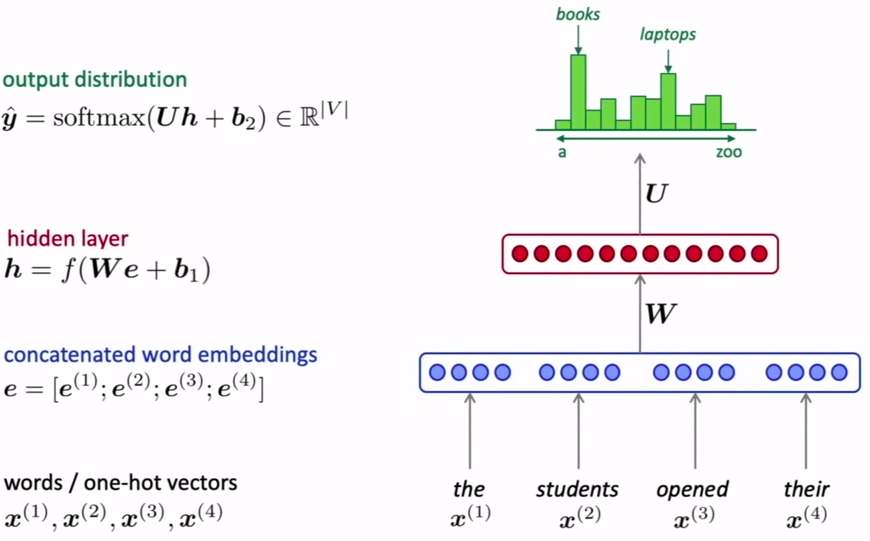
该方法解决了稀疏性问题,与N-grams相比不需要太多存储空间,但也存在一些自身的问题。由于神经网络使用固定的输入窗口,因此由该模型生成的文本长度是固定的,因此使用起来不太灵活。随着窗口大小的增大,模型的大小也随之增大,从而变得效率低下。
使用长-短期记忆网络(LSTM)
为了解决固定输入长度问题,我们使用递归神经网络(RNNs)。正如我们在N-grams方法中看到的,N-grams方法缺少长期依赖。如果我们使用vanilla-RNNs(https://medium.com/@apiltamang/unmasking-a-vanilla-rnn-what-lies-beneath-912120f7e56c) ,由于RNNs中的梯度消失,我们仍然会有相同的长期依赖问题。然而,一种称为LSTM的特殊RNN解决了上述问题。
LSTMs能够学习长期依赖关系。它们是由Hochreiter&Schmidhuber(1997)(http://www.bioinf.jku.at/publications/older/2604.pdf) 提出的,并在随后的工作中被许多人改进和推广。
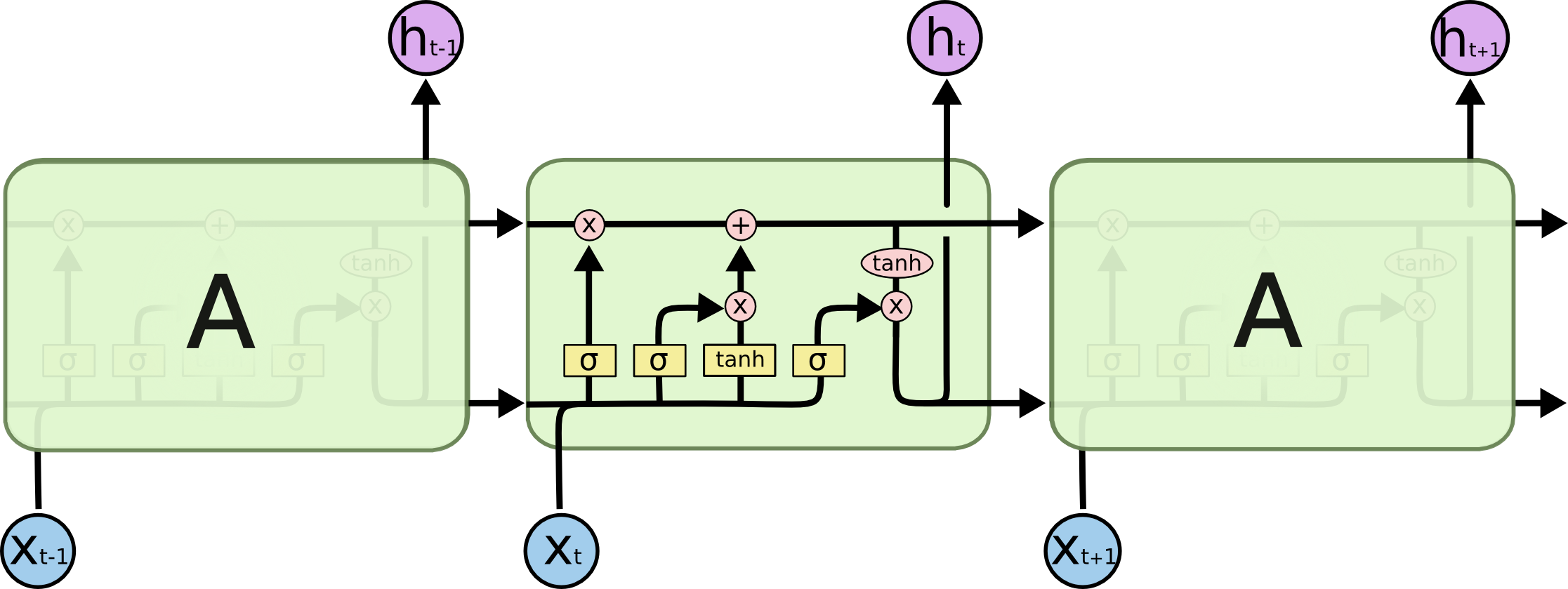
所有的RNNs都是由一系列重复的神经网络模块组成的。在标准RNN中,这个重复模块将有一个非常简单的结构,比如一个单一的tanh层。在LSTMs中,重复模块具有不同的结构。不是只有一个神经网络层,而是有四个,以一种非常特殊的方式相互作用。请在此处详细阅读LSTMs(https://colah.github.io/posts/2015-08-Understanding-LSTMs/)。
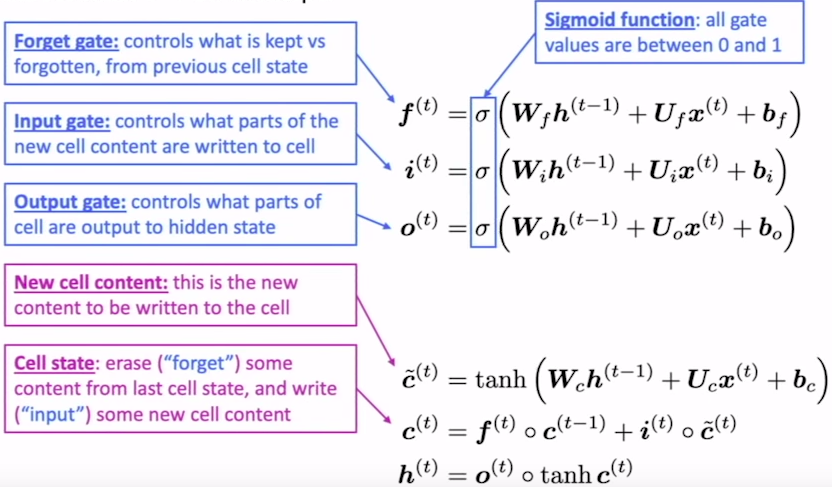
语言模型的评估
我们需要对模型进行评估,以改进它或将其与其他模型进行比较。困惑度被用来评估语言模型。它是一种测量概率模型预测测试数据的能力。
我们衡量我们的模型有多低的困惑度,低困惑度意味着模型生成了连贯、结构良好的句子,而高困惑度则表示不连贯和混乱的句子。因此,低困惑度是好的,高困惑度是坏的。
从数学上讲,困惑度是测试集的反概率,由单词数规范化。
LM的困惑度:
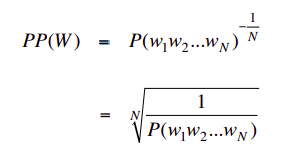
结论
语言模型是NLP的重要组成部分,可以用于许多NLP任务。我们看到了如何创建自己的语言模型,以及每种方法都会出现什么问题。我们得出的结论是,LSTM是制作语言模型的最佳方法,因为它考虑并处理了长期依赖问题。
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/

