

7个开源数据科学项目
作者|PRANAV DAR
编译|VK
来源|Analytics Vidhya
概述
-
开源数据科学项目会给你的简历增加很多价值,帮助你在面试中脱颖而出
-
这里有7个开源数据科学项目
介绍
我要给你一个建议。我希望在我开始数据科学职业生涯的时候曾有人给过我这个建议。
当我在数据科学中穿越充满障碍的旅程时,我认为具备所有的条件(或者我认为是这样的),但似乎有些事情不对劲。我经历了一番挣扎才找到我的缺陷。
我提出的与面试官期望的差距在于数据科学项目的经验。
数据科学项目给你的简历增加了很多价值,特别是如果你是个初学者。大多数新人都会获得认证证书,但增加开源数据科学项目将使你在竞争中获得显著优势。
相信我,开源数据科学项目数量多到惊人。

在这里,我列出了6月份创建或发布的顶级开源数据科学项目列表。这是我每月项目系列的一部分,在这个系列中,我展示了GitHub上开源的最佳数据科学项目。

我根据项目领域将其分为三类:
-
机器学习
-
计算机视觉
-
其他开源数据科学项目,其中包括一个很棒的数据集
让我们分别看一下每个类别。
开源机器学习项目
这些机器学习的项目。我们将在这里介绍与机器学习相关的三个有用的开源项目。你可以根据自己的兴趣选择一个项目,也可以尝试所有项目。
我试着让它们尽可能多样化,你可以看到一个关于机器学习论文的项目和另一个建立机器学习管道的项目。
带插图和注释的机器学习论文
链接:https://github.com/Machine-Learning-Tokyo/papers-with-annotations
对于大多数专业人士来说,阅读机器学习研究论文是一个令人望而生畏的前景,更不用说初学者了。
数据科学家和机器学习研究人员倾向于撰写技术含量极高的论文,即使是专家也很难解读。这实际上是我们领域最大的痛点之一。
因此,任何打破复杂性的努力都是受欢迎的。这个有用的项目是一个数据科学和机器学习论文的集合,“包括插图、注释、术语和先前研究的简要说明,这使得阅读论文和获得主要思想更容易”。
这个项目上周刚刚在GitHub上开源,所以它会定期更新。现在我们已经可以看到一些论文了,这样你就可以通过它们来了解注释是如何完成的。我特别喜欢YOLOv1的注释:
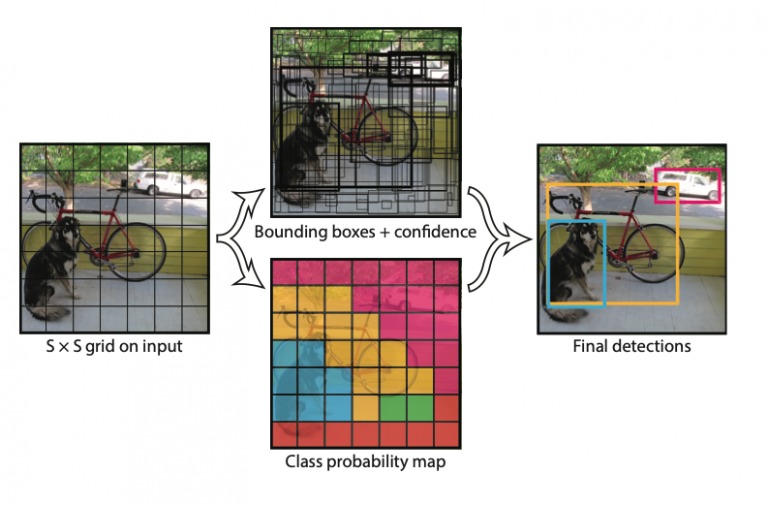
很酷!继续探索这篇论文和其他论文。有很多东西要学!
NeoML,一个机器学习框架
链接:https://github.com/neoml-lib/neoml
对于任何一个有点数据科学知识的人来说,这是一个非常有趣的项目。

NeoML是一个全面的机器学习框架,它使我们能够构建、训练和部署机器学习模型。
简而言之,我们可以建立一个端到端的机器学习管道,而不必为现成的解决方案花费大笔资金。
数据科学家和数据工程师可以将其用于计算机视觉和自然语言处理(NLP)任务,如图像预处理、分类、文档分析、OCR以及从结构化和非结构化文档中提取数据。
以下是我从GitHub存储库中获取的NeoML的关键特性:
-
支持100多种层类型的神经网络
-
传统机器学习:20+算法(分类、回归、聚类等)
-
支持快速CPU推理
-
ONNX支持
-
语言:C++、java、Objective-C
-
跨平台:相同的代码可以在Windows、Linux、macOS、iOS和Android上运行
谷歌机器学习的Caliban
链接:https://github.com/google/caliban
这是倾向于研究的数据科学家都会喜欢的项目。我们常常很难从测试环境过渡到全面部署,这不是一个容易的步骤。
当然,Google有一个以Caliban的形式为我们提供的潜在解决方案。
这是一个工具,将帮助你在一个孤立的,可重复的计算环境中启动和跟踪你的数值实验。Caliban是由谷歌的机器学习研究人员和工程师开发的。

正如他们所说,Caliban“使得从一个在工作站上运行的简单原型到在云端运行的数千个实验性工作变得容易”。以下是你应该注意的要点:
-
在本地开发实验代码,并在隔离(Docker)环境中测试它
-
扫描实验参数
-
提交你的实验作为云作业,它们将在相同的隔离环境中运行
-
控制并跟踪工作
开源计算机视觉项目
我对我们在计算机视觉领域所取得的进步感到惊讶。似乎每个月当我坐下来写这篇文章的时候,我都会遇到越来越多的突破性的框架和新的方法来提升这个领域的最新水平。
组织机构正在全球范围内搜寻计算机视觉人才,所以现在正是从事这些项目并进入该领域的大好时机。
Genetic Drawing
链接:https://github.com/anopara/genetic-drawing
如果我给你一个目标图像,然后让你写一个计算机视觉程序从头开始创建这个图像呢?是的,这就是计算机视觉的力量!
这个非常酷的开源项目使我们能够在获得目标图像时模拟绘图过程。下面是一个小的演示过程:

我迫不及待地想尝试这个项目。你需要以下Python库来运行它:
- OpenCV 3.4.1
- NumPy 1.16.2
- matplotlib 3.0.3
开发人员还给了我们一个例子,这样你就可以执行它,并观看计算机视觉的魔力。
PULSE
链接:https://github.com/tg-bomze/Face-Depixelizer
这个开源项目迎合了稍微更高级的数据科学家。
为了理解这个项目的意义,我们需要掌握单图像超分辨率的概念。简单地说,这里的目的是从相应的低分辨率输入构建一个高分辨率图像。
听起来像是一个经典的计算机视觉项目!
PULSE是这个问题陈述的一个新的解决方案。“通过潜在空间探索进行照片上采样”的简称,PULSE以难以置信的高分辨率生成高分辨率和超现实图像。这是以一种完全自我监督的方式完成的。
下面是一个PULSE如何工作的示例:

我建议你在阅读代码之前先阅读研究论文。这将使你更好地了解PULSE的工作原理,这样你就可以更清楚地处理代码了。
论文:https://arxiv.org/abs/2003.03808
其他开源数据科学项目
这里有几个开源数据科学项目并不完全符合上述两个类别。这实际上是两个截然不同的项目——一个面向数据科学的初学者,而另一个则针对强化学习。
你可以挑一个最适合你的项目,开始探索。
PalmerPenguins
链接:https://github.com/allisonhorst/palmerpenguins
这是一个很棒的用于探索和可视化的数据集
我相信你们大多数人都用过虹膜数据集。实际上,它甚至可能是你用来理解机器学习中分类概念的第一个数据集。我喜欢数据集的理解和探索。
但是使用同一个数据集可能会变得有些沉闷,特别是当你在学习机器学习的来龙去脉时。
Palmenguins是上个月开源的,这个数据集将自己定位为Iris的一个替代品,旨在为数据探索和可视化提供一个很好的数据集,特别是对于初学者。
以下是你可以想出的视觉化体验:
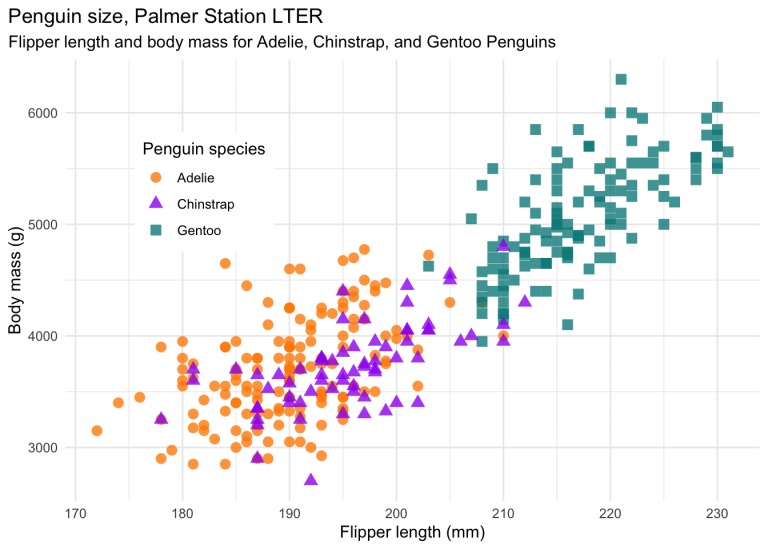
我上面提到的链接包含了如何开始探索这些数据的示例。他们甚至提供了关于不同变量的细节。
你可以使用以下代码在你的计算机上获取PalmerPenguins:
# install.packages("remotes")
remotes::install_github("allisonhorst/palmerpenguins")
SlimeVolleyGym
链接:https://github.com/hardmaru/slimevolleygym
这是一个开放源码的强化学习项目。
SlimeVolleyGym是一个简单的健身房环境,用于测试单智能体和多智能体强化学习算法。这是由机器学习领域的传奇人物hardmaru创建并开源的。
根据他的说法,游戏的运作方式(他自己用JavaScript创建了游戏):
这个游戏非常简单:代理的目标是让球落在对方的地面上,导致对手失去生命。每个特工一开始都有五条生命。当任何一个特工失去5条生命,或者超过3000个时间步时,结束。当一个代理人的对手输了,他会得到+1的奖励;当他输了,他会得到-1的奖励。
你可以直接从pip安装slimevolleygym :
pip install slimevolleygym
结尾
确实有很多项目。和往常一样,我的目标是尽可能保持项目的多样性,以便你能够选择适合你的数据科学旅程的项目。
如果你是初学者,我建议你从PalmerPenguins数据集开始,因为大多数人现在甚至还没有认识到它。这是一个先发制人的好机会。
原文链接:https://www.analyticsvidhya.com/blog/2020/07/7-open-source-data-science-projects-add-resume/
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
