
强化学习中的线性代数知识
作者|Nathan Lambert
编译|VK
来源|Towards Data Science
线性代数的基本原理如何用于深度强化学习?答案是解决了马尔可夫决策过程时的迭代更新。
强化学习(RL)是一系列用于迭代性学习任务的智能方法。由于计算机科学是一个计算领域,这种学习发生在状态向量、动作等以及转移矩阵上。状态和向量可以采用不同的形式。当我们考虑通过某个线性系统传递一个向量变量,并得到一个类似的输出时,应该想到特征值。
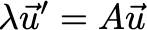
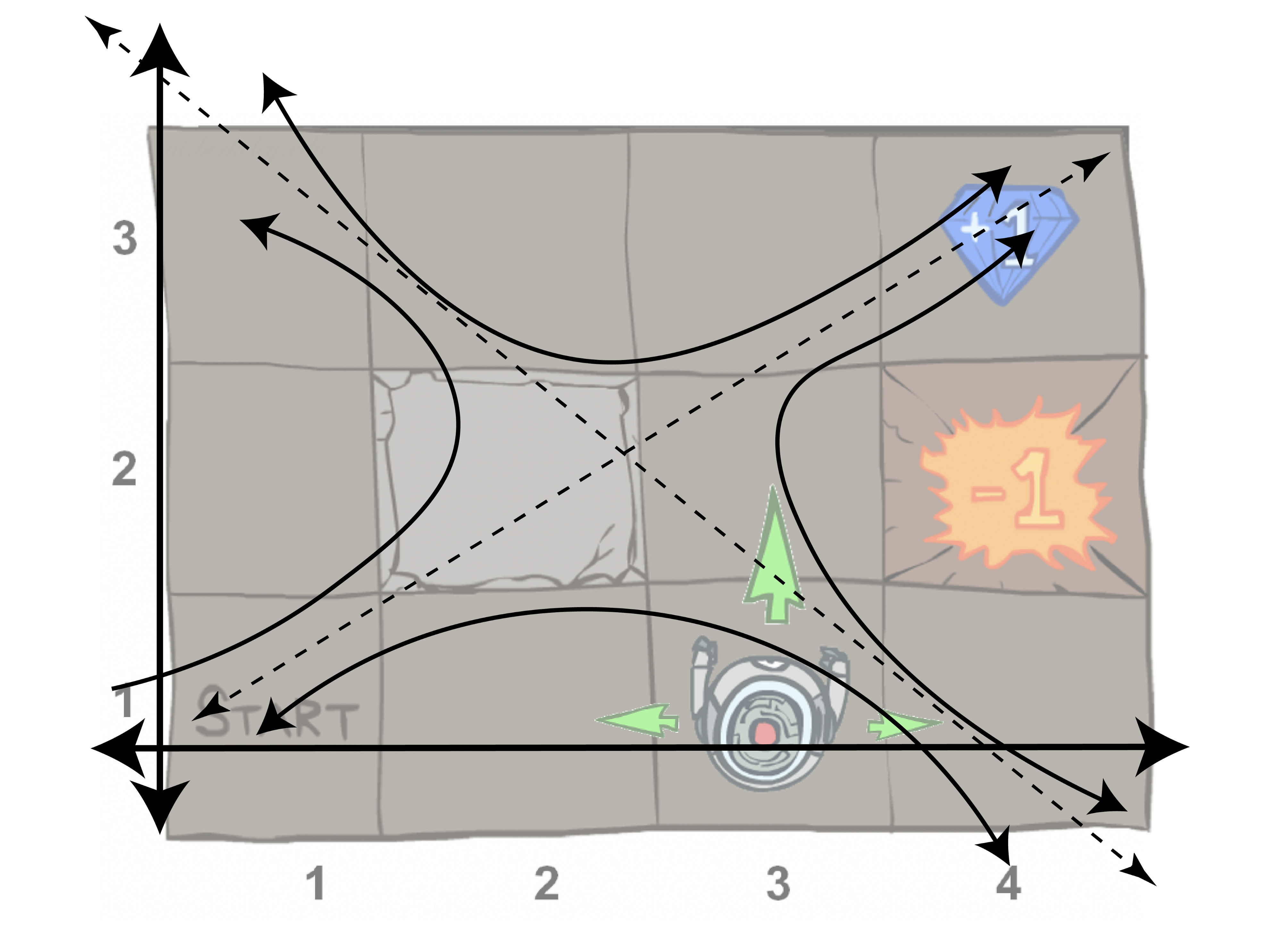
本文将帮助你理解在RL环境中解决任务的迭代方法(收敛到最优策略)。这个基础将反映一个系统的特征向量和特征值。

回顾马尔科夫决策过程
马尔可夫决策过程(MDPs)是支持强化学习(RL)的随机模型。如果你熟悉,你可以跳过这一部分。
定义
- 状态集$s\in S。状态是代理程序所有可能的位置。
- 一组动作\(a\in A\)。动作是代理可以采取的所有可能动作的集合。
- 转移函数T(s,a,s')。T(s,a,s')保持MDP的不确定性。给定当前位置和给定动作,T决定下一个状态出现的频率。
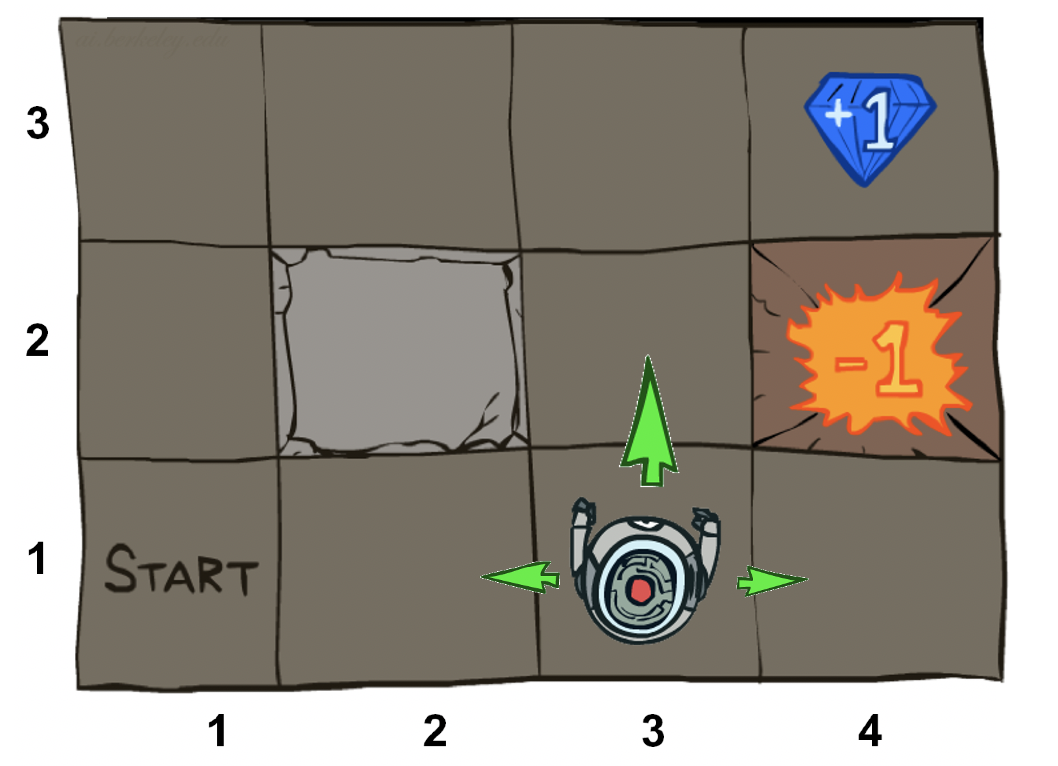
- 奖励函数R(s,a,s')。最大化报酬总额是任何代理的目标。此函数说明每个步骤可获得多少奖励。通常,为鼓励快速解决方案,每个步骤都会有少量的负奖励(成本),而在最终状态下会有较大的正面(成功的任务)或负面(失败的任务)奖励。
- 开始状态s0,也许是结束状态。

重要的属性
MDP有两个重要的属性,状态的值和随机节点的q值。
-
状态值:状态值是从状态开始的奖励的最优递归和。如果机器人在火坑里,在宝石旁边,或者在沙发上,状态值会有很大的不同。
-
状态-动作对(state- action pair)的q值:q值是与状态-动作对相关的折扣奖励的最优和。一个状态的q值是由一个动作决定的,所以如果方向指向火坑的内部或外部,q值会有很大的变化!
这两个值通过通过相互递归和Bellman更新相关联。
Bellman 更新
Richard E. Bellman是一位数学家,奠定了现代控制和优化理论的基础。通过recursive one-step方程、Bellman更新方程,可以有效地求解大型优化问题。通过递归Bellman更新,可以用动态规划建立优化或控制问题,这是一个创建更小、更易于计算处理的问题的过程。这个过程递归地从终点开始。

-
Bellman方程:用动态规划公式化。
-
动态规划:通过将优化问题分解成最优子结构来简化优化问题的过程。
在强化学习中,我们使用Bellman更新过程来求解状态-动作空间的最优值和q值。这是从一个从给定的位置最终形成的预期未来奖励总和。
在这里,我们可以看到的所有公式。符号(*)表示最优的。公式有最佳动作决定的状态值,和一个q状态。求和平衡了访问T(s,a,s')中的任何状态转移的概率和任何转移R(s,a,s')的奖励,从而为状态操作空间的值创建一个全局映射。
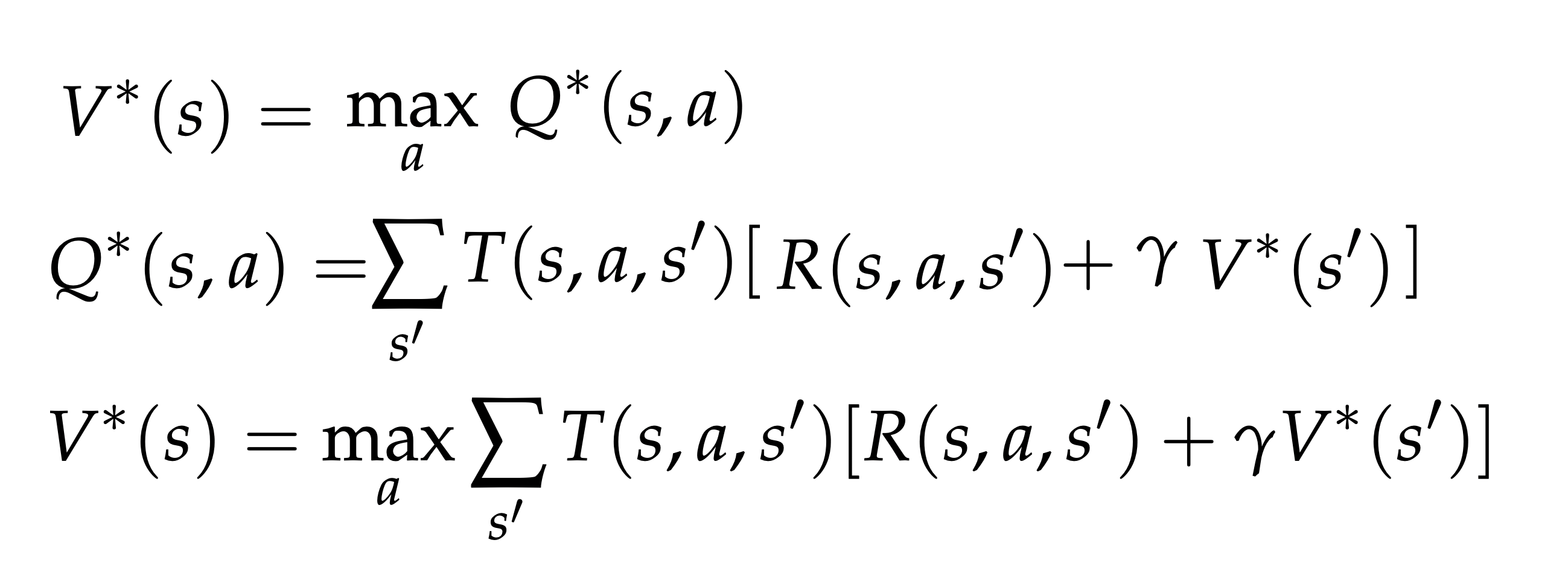
这里的关键点是我们用矩阵(R, T)乘以向量(V,U)来迭代地求出。这些值将从任何初始状态收敛,因为一个状态的值是由它们的近邻s决定的(马尔科夫)。
与强化学习的关系
以上这都是强化学习的内容,我断言理解算法所基于的假设和模型将比仅仅复制OpenAI中的python教程为你提供更好的基础。我指导过很多学生在RL工作,那些做得更多的人总是那些知道正在发生什么,然后知道如何应用它的人。
也就是说,这离在线q-learning只有一步之遥,在在线q-learning中,我们用T和R的样本来进行Bellman更新,而不是显式地在方程中使用它们。Q-learning是在2015年解决Atari游戏等问题的著名算法。
线性代数
特征值
回想一下,系统A的一个特征值-特征向量对(λ,u)是一个标量和向量,公式如下
特征值和特征向量的好处在于,每个向量都可以写成其他特征向量的组合。然后,在离散系统中特征向量控制从无论什么初始状态的演化,因为任何初始向量可以组合成特征向量的线性组合。
随机矩阵和马尔可夫链
MDPs与马尔科夫链非常接近,但在结构上与马尔科夫链并不相同。马尔可夫链是由转移矩阵P决定的。概率矩阵的作用类似于对动作求和的转移矩阵T(s,a,s')。在马尔可夫链中,下一个状态由:
这个矩阵P有一些特殊的值,你可以看到,这是一个特征值等于1的特征值方程。为了得到一个特征值等于1的矩阵,所有的列之和必须等于1。
我们现在在RL中寻找的是,我们的解的演化如何与概率分布的收敛相关?我们通过为V和Q制定线性算子(矩阵)的迭代运算符B。我们使用的值和q值的向量而不是特征向量,他们会收敛于特征向量,所以可以看出特征向量实际控制了整个系统。
B,像一个线性变换的特征向量,特征值λ= 1。
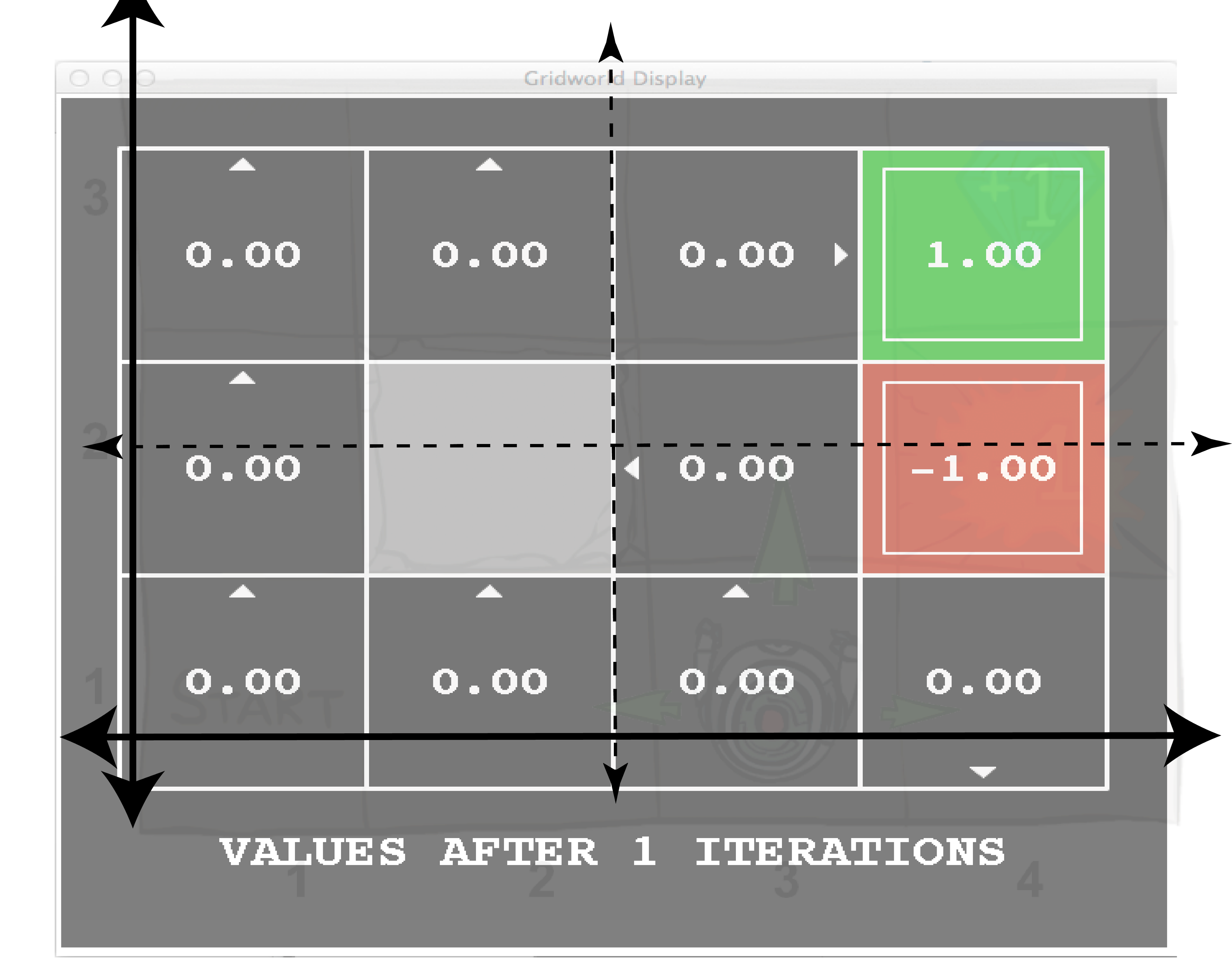
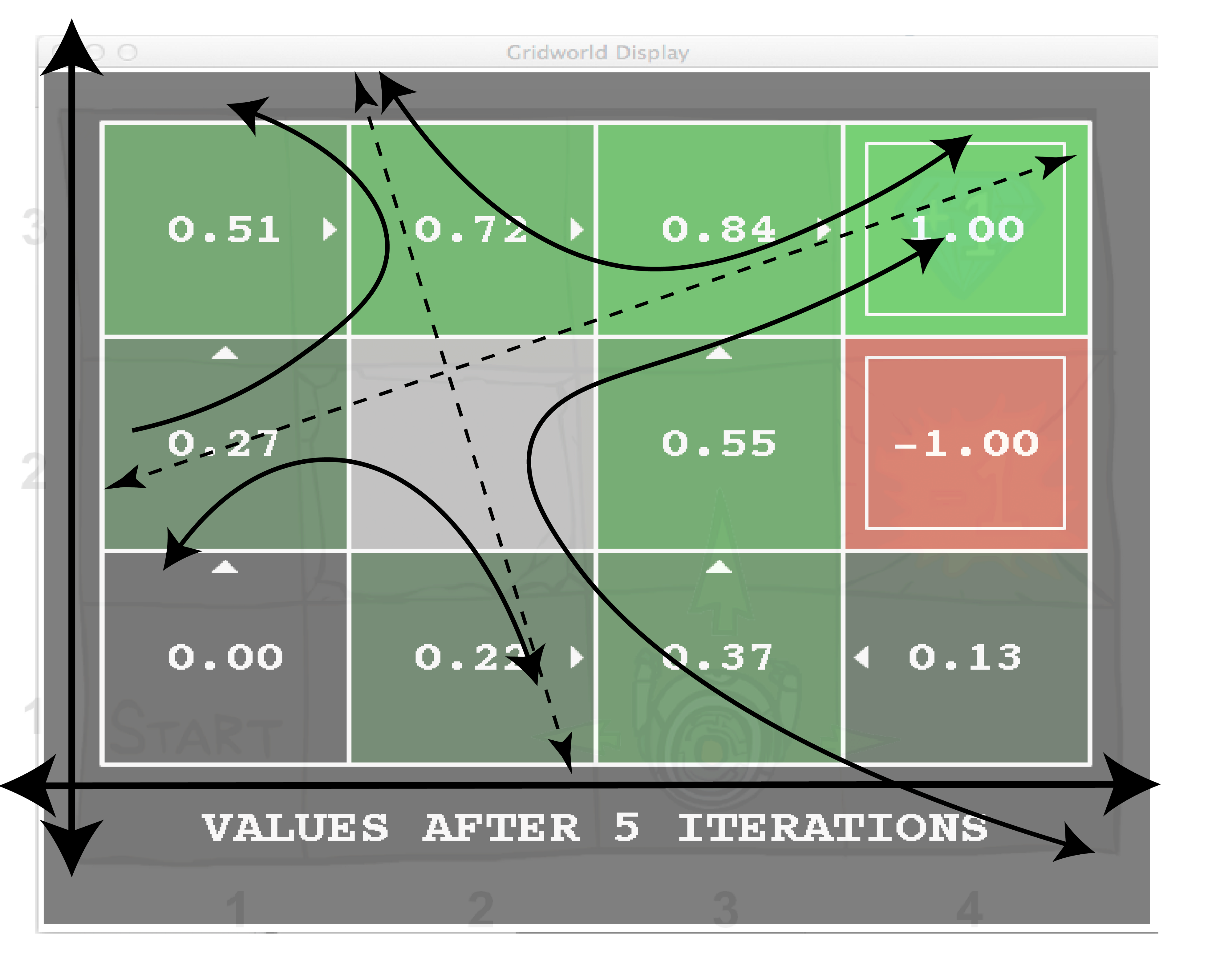
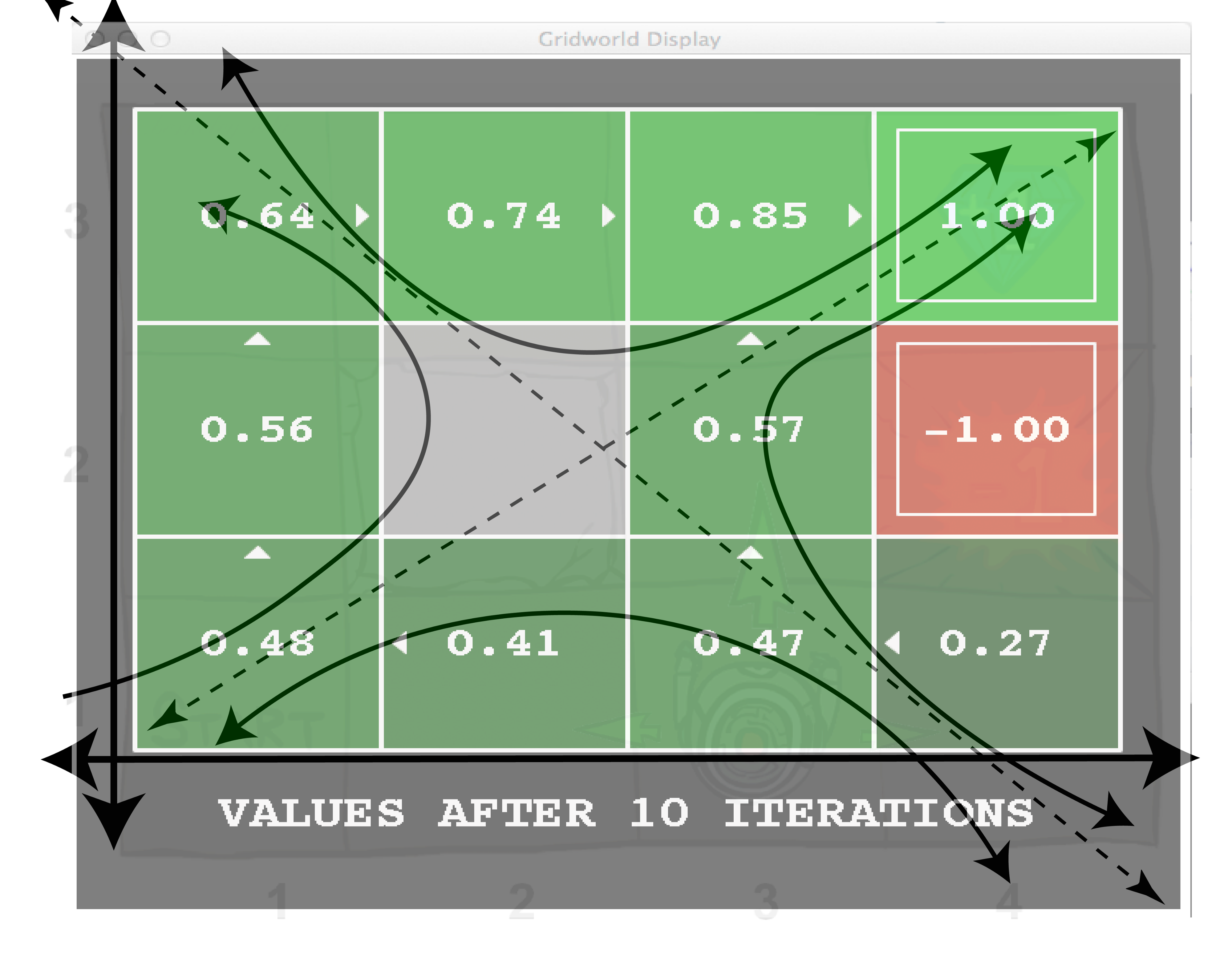
任何初值分布都收敛于特征空间的形状。这个例子并没有显示Bellman更新的确切特征值,但是当这些值递归更新时,图片显示了空间的形状是如何演变的。一开始,这些值是完全未知的,但是随着学习的出现,这些已知的值会逐渐收敛,以与系统完全匹配。
Bellman更新
到目前为止,我们知道如果我们可以用更简单的形式表示Bellman更新,那么将会出现一个方便的结构。我们如何将Q的更新表示为一个简单的更新方程?我们从一个q迭代方程开始。
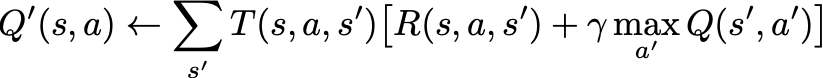
MDP的Q-迭代.
要实现这种转变,需要几个小步骤。
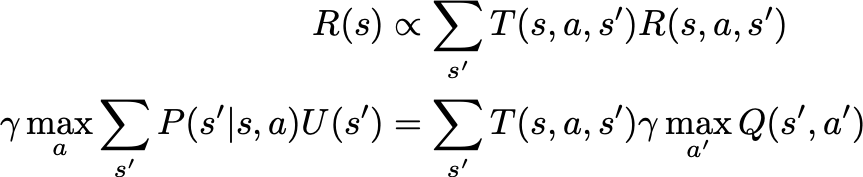
这样就将我们的系统移向一个线性算子(矩阵)
i)让我们把一些术语重新表述为一般形式
更新的前半部分,R和T的总和,是一个明确的奖励数字;我们称之为R(s),接下来,我们将转换的总和转换为一个概率矩阵(和一个马尔可夫矩阵匹配,非常方便)。此外,这将导致下一步,U的生成。
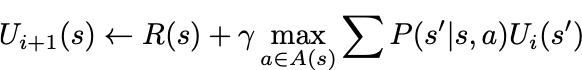
ii)让我们把它变成一个向量方程。
我们最感兴趣的是MDP的U是如何继续演进的。U隐含着值或q值。我们可以简单地把Q改写成U,而不需要做太多改变,但这意味着我们假设的策略是固定的。
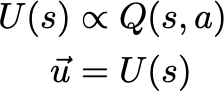
重要的是要记住,即使对于一个多维的物理系统——如果我们将所有测量到的状态叠加成一个长数组,状态的U也是一个向量。一个固定的策略不会改变收敛性,它只是意味着我们必须重新访问它来学习如何迭代地获得一个策略。
iii)假设策略是固定的
如果你假设一个固定的策略,那么a的最大值就消失了。最大化算符明显是非线性的,但是在线性代数中有一些形式是特征向量加上一个额外的向量(广义特征向量)。
上面的这个等式是关于U的Bellman更新的一般形式。我们想要一个线性算子B,然后我们可以看到这是一个特征值演化方程。它看起来有点不同,但这是我们最终想要的形式,减去几个线性代数断言,所以我们有了Bellman更新。
在计算上,我们可以得到我们想要的特征向量,因为在这个过程中所做的假设,所以在分析上这样做是有挑战性的,

结尾
线性算子向你展示了某些离散的线性系统是如何推导的——而我们在强化学习中使用的环境就是遵循这种结构。
我们收集的数据的特征值和特征向量可以表示一个RL问题的潜在值空间。
变量替换、线性变换、在线q-learning(而不是这里的q-iteration)中的拟合,以及更多的细节将在以后的文章中讨论。
原文链接:https://towardsdatascience.com/the-hidden-linear-algebra-of-reinforcement-learning-406efdf066a
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/

