
新手入门机器学习十大算法
欢迎大家关注我们的网站和系列教程:http://panchuang.net/ ,学习更多的机器学习、深度学习的知识!
在机器学习的世界中,有一种被称为“无免费午餐”的定理。 它意在说明没有哪种算法能够完美地解决每个问题,特别是对于监督学习问题。例如,神经网络不会总是比决策树要好,反之亦然。往往是有许多因素在起作用(如:数据集的大小、结构),共同决定了最后的结果。因此,我们应该针对具体的问题尝试许多不同的算法,并选取一部分数据作为“测试集”来评估性能,最后选择性能最好的算法。当然,我们选取的算法必须要适合我们的问题,这也是完成机器学习任务的关键所在。
然而,我们通过有监督机器学习进行建模必须遵守一个基本的原则:通过找到输入变量X到输出变量Y的映射关系:Y = f(X),最终学习得到一个目标函数f。这样就可以针对新的输入数据X通过目标函数f预测出新的输出变量Y。在机器学习中,这称为预测建模或预测分析。
一 、线性回归(Linear Regression)
线性回归可能是统计学和机器学习中最知名且最易于理解的算法之一。线性回归是指在输入变量(x)和输出变量(y)之间找到一种最佳的拟合关系,往往这种关系是通过查找被称为系数(B)的输入变量的特定权重来描述的。例如:y = B0 + B1 * x。即:我们将在给定输入x的情况下预测y,并且线性回归学习算法的目标是找到系数B0和B1的值。我们可以使用不同的方法从数据中学习线性回归模型,例如最小二乘法和梯度下降法。
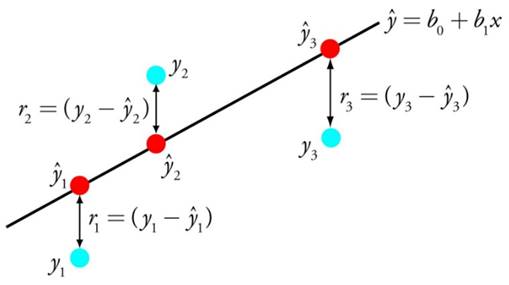
线性回归已经存在了200多年,并且已经被广泛研究。使用该方法时,我的一些经验是删除非常相似的变量,并尽可能消除数据中的噪声。总而言之,线性回归是一种快速而简单的算法,非常适合大家作为入门的第一种算法来尝试。
二、逻辑回归(Logistic Regression)
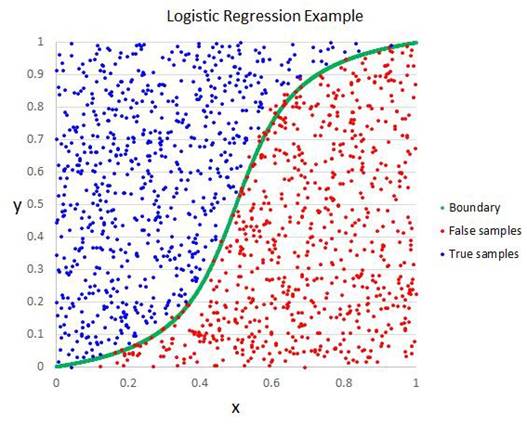
逻辑回归是机器学习从统计学领域借鉴过来的另一种方法。它是二分类问题的首选方法(两个类值的问题),也是学习二元分类问题并快速见面最有效的方法。逻辑回归就像线性回归一样,目标是找到每个输入变量对应的相关系数。与线性回归不同的是,它使用了一种称为“逻辑函数”的非线性函数来转换输出的预测。
逻辑函数看起来像一个大S,并可以将任何值转换为0到1的范围。这点非常的重要,因为我们可以将逻辑函数的输出控制到0和1来预测一个类值。此外,同线性回归一样,我们可以通过删除与输出变量无关的属性以及彼此非常相似的属性,来使模型的效果更好。
三、线性判别分析(Linear Discriminant Analysis)
逻辑回归是一种仅限于两分类问题的分类算法。但如果我们有两个以上的类别,那么线性判别分析算法是首选的线性分类算法。LDA的表示是非常直接的:它由每个类计算的数据所统计的属性组成。此外对于单个输入变量,它包括:每个类别的平均值以及所有类别计算的方差。
LDA是通过计算每个类的判别值并对具有最大值的类进行的预测。该技术的前提是假设数据具有高斯分布,因此我们需要事先从数据中删除异常值。LDA也是分类预测建模问题的一种简单而强大的算法。
四、决策树模型(Classification and Regression Trees)
决策树是机器学习中预测建模一种重要的算法。如下图所示,决策树模型的表示是二叉树,和算法和数据结构中的二叉树一样,每个节点表示一个输入变量(x)和该变量上的一个分割点(假设变量是数字)。
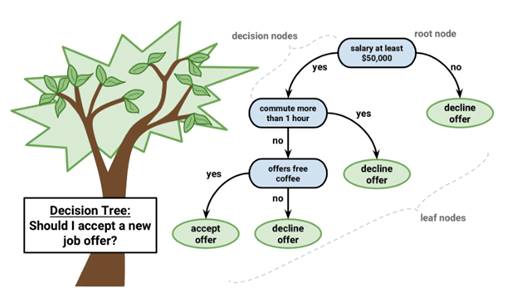
树的叶节点包含用于进行预测的输出变量(y)。预测过程是通过遍历树的分裂直到到达叶节点并输出该叶节点处的类值。决策树学模型的优势在于学习以及预测的速度都非常快。并且树模型适用于各种各样的问题,不需要对数据进行任何特殊的处理。
五、朴素贝叶斯( Naive Bayes)
Naive Bayes是一种简单但非常强大的预测建模算法。该模型由两种类型的概率组成,可以直接根据我们的训练数据进行计算:(1)每个类的概率;(2)每个类给定每个x值的条件概率。一旦计算出来,概率模型可利用贝叶斯定理对新数据进行预测。当我们的数据是实数时,通常会采用高斯分布,这样就可以轻松估计这些概率了。
朴素贝叶斯之所以被称为“naive”,是因为它假设每个输入变量是独立的。现实这是一个强有力的假设,对于实际数据是不成立的,但该技术对于大范围的复杂问题是非常有效。
六、K近邻算法(K-Nearest Neighbors)
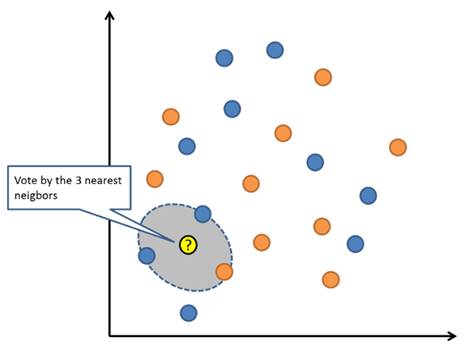
KNN算法非常的简单、有效。KNN的模型表示是整个训练数据集。KNN算法的原理是通过搜索整个训练集来寻找K个最相似的实例,并总结这K个实例的输出变量,进而对新的数据点进行预测。对于回归问题,可能是平均输出变量;对于分类问题,可能是常见的类值。
KNN的诀窍在于如何确定数据实例之间的相似性。 如果我们的属性都具有相同的比例,则最简单的方法是使用欧几里德距离,我们可以根据每个输入变量之间的差异直接计算该数字。
此外,KNN可能需要大量的内存或空间来存储所有数据,但只有在需要预测时才会执行计算的操作。所以,我们还可以随着时间的推移更新和调整训练实例,以保持预测效果更加准确。
七、学习矢量量化(Learning Vector Quantization)
K近邻的缺点是我们需要等候整个训练数据集。而学习矢量量化算法(简称LVQ)是一种神经网络算法,允许我们选择要挂起的训练实例数量,并可以准确地学习到这些实例。如果我们的数据集可以使用KNN的方法训练出良好的结果,那么就可以尝试使用LVQ算法来减少存储整个训练数据集的内存需求。
LVQ的表示是码本(权值)向量的集合。这些码本在开始时随机选择的,并且适合于在学习算法的多次迭代中最佳地总结训练数据集。在学习之后,可我们以使用码本向量来进行与KNN类似的预测。通过计算每个码本矢量和新数据实例之间的距离来找到最相似的邻居(即最佳匹配码本矢量)。然后,将最佳匹配单元的类值或回归值(实值)作为预测返回。如果将数据重新缩放至相同范围(例如0到1之间),就可以获得最好的结果。
八、支持向量机(Support Vector Machines)
支持向量机可能是目前最流行的机器学习算法之一。SVM算法的核心是选择一个最佳的超平面将输入变量空间中的点按照它们的类(0或1)分开。所谓的“超平面”其实就是一个分割输入变量空间的线,在二维空间中,我们可以将其可视化为一条直线,并且假设我们所有的输入点都可以被这条直线完全分开。
此外,超平面和最近数据点之间的距离称为边距。可以分离两个类的最佳或最优超平面是具有最大边距的行。这些点与定义超平面和分类器的构造是有关,这些点称为支持向量。它们可以支持或定义超平面。
最后,SVM可能是最强大的分类器之一,值得我们使用数据集尝试使用。
九、随机森林(Bagging and Random Forest)
随机森林是最流行和最强大的机器学习算法之一。它是一种被称为“bagging”的集成机器学习算法。Bagging是一种强大的统计方法,常用于估计从数据样本的数量。如:我们取大量的数据样本后计算平均值,然后再对所有平均值进行平均,以便更好地估计真实的平均值。
在bagging中,要对我们的训练数据进行多次采样,然后为每个数据样本构建模型。当需要对新数据进行预测时,每个模型都进行预测,并对预测进行平均,以更好地估计真实输出值。
随机森林是对这种方法的一种调整,通过创建决策树,使得不是选择最佳分裂点,而是通过引入随机性来进行次优分割。因此,为每个数据样本构建的模型与它们原本是不同的,这样结合它们的预测可以更好地估计真实的输出结果。
十、Boosting and AdaBoost
Boosting是一种集成方法,试图从多个弱分类器中创建强分类器。这一过程是通过从训练数据种构建模型,然后创建第二个模型来完成的,该模型试图纠正来自第一个模型的错误。以此类推,添加模型直到能完美预测训练集或是添加最大数量的模型。
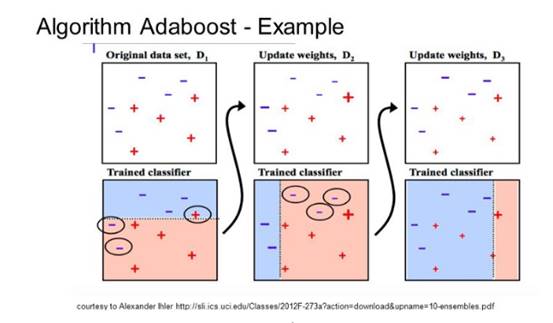
AdaBoost是第一个真正成功实现Boosting的算法,是理解boosting方法的最佳起点。现在很多boosting方法都是建立在AdaBoost算法之上,效果最好的当数是gradient boosting 。
此外,Adaboost通常会和短决策树一起使用。在创建第一棵树之后,使用树在每个训练实例上的性能来衡量创建的下一棵树应该对每个训练实例关注多少。往往难以预测的训练数据会被赋予更多的权重,而容易预测的实例被赋予较少的权重。这样,一个接一个地依次创建模型,每个模型更新训练实例上的权重,这些权重影响序列中的下一棵树所执行的学习。构建完所有树之后,将对新数据进行预测,并根据训练数据的准确性对每棵树的性能进行加权。
【总结】本篇文章针对需要入门机器学习的玩家,为大家准备了十大最常用的机器学习算法,希望大家喜欢。
对深度学习感兴趣,热爱Tensorflow的小伙伴,欢迎关注我们的网站!http://www.tensorflownews.com 。我们的公众号:磐创AI。

