软工查重
| 软件工程 | 网工1934 |
|---|---|
作业要求: 1、在Github仓库中新建一个学号为名的文件夹。 2、在开始实现程序之前,在PSP表格记录下你估计在程序开发各个步骤上耗费的时间,在你实现程序之后,在PSP表格记录下你在程序的各个模块上实际花费的时间。 3、编程语言不限,将编译好的程序发布到Github仓库中的releases中 4、提交的代码要求经过Code Quality Analysis工具的分析并消除所有的警告。 5、完成项目的首个版本之后,请使用性能分析工具Studio Profiling Tools来找出代码中的性能瓶颈并进行改进。 6、使用Github[附录3]来管理源代码和测试用例,代码有进展即签入Github。签入记录不合理的项目会被助教抽查询问项目细节。 7、使用单元测试[附录4]对项目进行测试,并使用插件查看测试分支覆盖率等指标;写出至少10个测试用例确保你的程序能够正确处理各种情况。 |
作业要求 |
| 作业目标: 设计一个论文查重算法,给出一个原文文件和一个在这份原文上经过了增删改的抄袭版论文的文件,在答案文件中输出其重复率。 |
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 20 |
| · Estimate | · 估计这个任务需要多少时间 | 20 | 20 |
| Development | 开发 | 300 | 240 |
| · Analysis | · 需求分析 (包括学习新技术) | 20 | 40 |
| · Design Spec | · 生成设计文档 | 60 | 120 |
| · Design Review | · 设计复审 | 40 | 60 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 15 | 15 |
| · Design | · 具体设计 | 30 | 30 |
| · Coding | · 具体编码 | 180 | 240 |
| · Code Review | · 代码复审 | 30 | 40 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 20 | 30 |
| Reporting | 报告 | 60 | 120 |
| · Test Report | · 测试报告 | 30 | 30 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 20 |
| Total | · 合计 | 855 | 1035 |
二、计算模块接口与实现
项目结构:
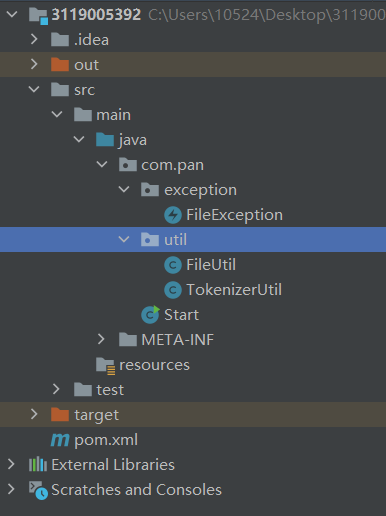
开发环境:
IDEA 2021 (jdk 11)
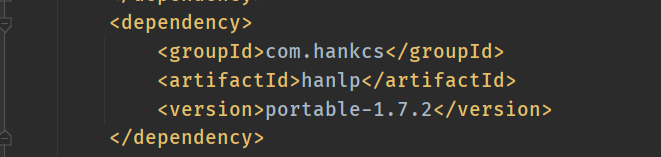
maven项目引入汉语包:
1、主要实现类
主类:
FileUtil: 对文件读取和写入
TokenizerUtil: 使用余弦相似度算法计算文本相似度
FileException: 抛出程序异常
Start:程序主入口
2、使用算法
余弦相似度算法:一个向量空间中两个向量夹角间的余弦值作为衡量两个个体之间差异的大小,余弦值接近1,夹角趋于0,表明两个向量越相似,余弦值接近于0,夹角趋于90度,表明两个向量越不相似。
下面我们介绍使用余弦相似度计算两段文本的相似度。思路:1、分词;2、列出所有词;3、分词编码;4、词频向量化;5、套用余弦函数计量两个句子的相似度。
句子A:这只皮靴号码大了。那只号码合适。
句子B:这只皮靴号码不小,那只更合适。
1、分词:
使用结巴分词对上面两个句子分词后,分别得到两个列表:
listA=[‘这‘, ‘只‘, ‘皮靴‘, ‘号码‘, ‘大‘, ‘了‘, ‘那‘, ‘只‘, ‘号码‘, ‘合适‘]
listB=[‘这‘, ‘只‘, ‘皮靴‘, ‘号码‘, ‘不小‘, ‘那‘, ‘只‘, ‘更合‘, ‘合适‘]
2、列出所有词,将listA和listB放在一个set中,得到:
set={'不小', '了', '合适', '那', '只', '皮靴', '更合', '号码', '这', '大'}
将上述set转换为dict,key为set中的词,value为set中词出现的位置,即‘这’:1这样的形式。
dict1={'不小': 0, '了': 1, '合适': 2, '那': 3, '只': 4, '皮靴': 5, '更合': 6, '号码': 7, '这': 8, '大': 9},可以看出“不小”这个词在set中排第1,下标为0。
3、将listA和listB进行编码,将每个字转换为出现在set中的位置,转换后为:
listAcode=[8, 4, 5, 7, 9, 1, 3, 4, 7, 2]
listBcode=[8, 4, 5, 7, 0, 3, 4, 6, 2]
我们来分析listAcode,结合dict1,可以看到8对应的字是“这”,4对应的字是“只”,9对应的字是“大”,就是句子A和句子B转换为用数字来表示。
4、对listAcode和listBcode进行oneHot编码,就是计算每个分词出现的次数。oneHot编号后得到的结果如下:
listAcodeOneHot = [0, 1, 1, 1, 2, 1, 0, 2, 1, 1]
listBcodeOneHot = [1, 0, 1, 1, 2, 1, 1, 1, 1, 0]
下图总结了句子从分词,列出所有词,对分词进行编码,计算词频的过程
5、得出两个句子的词频向量之后,就变成了计算两个向量之间夹角的余弦值,值越大相似度越高。
listAcodeOneHot = [0, 1, 1, 1, 2, 1, 0, 2, 1, 1]
listBcodeOneHot = [1, 0, 1, 1, 2, 1, 1, 1, 1, 0]
根据余弦相似度,句子A和句子B相似度很高。
查看余弦相似度算法
3、代码测试
测试:
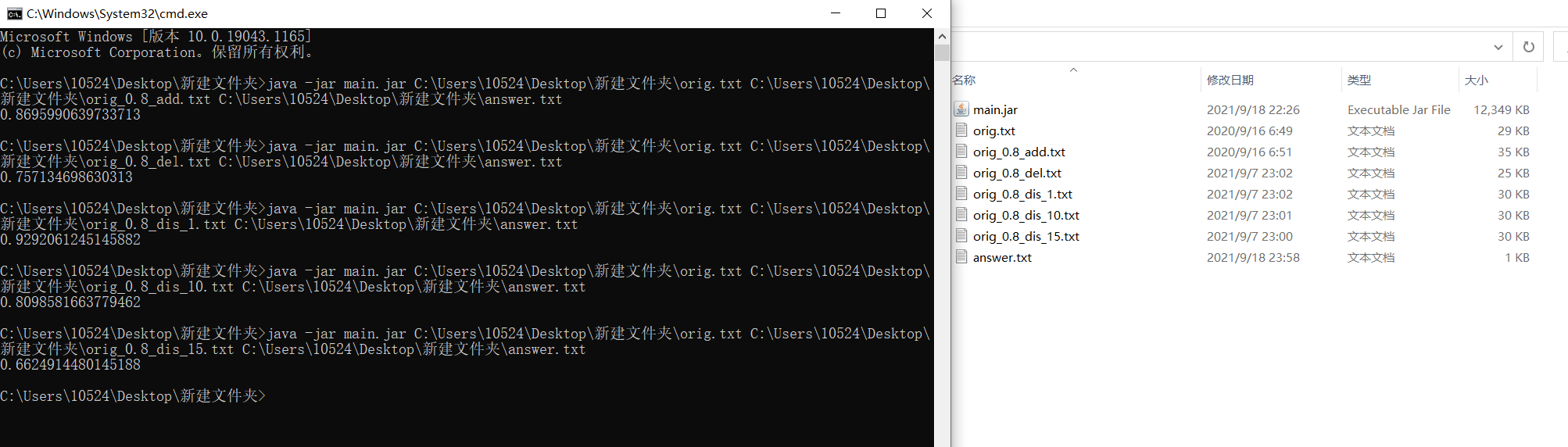
结果:

4、异常处理
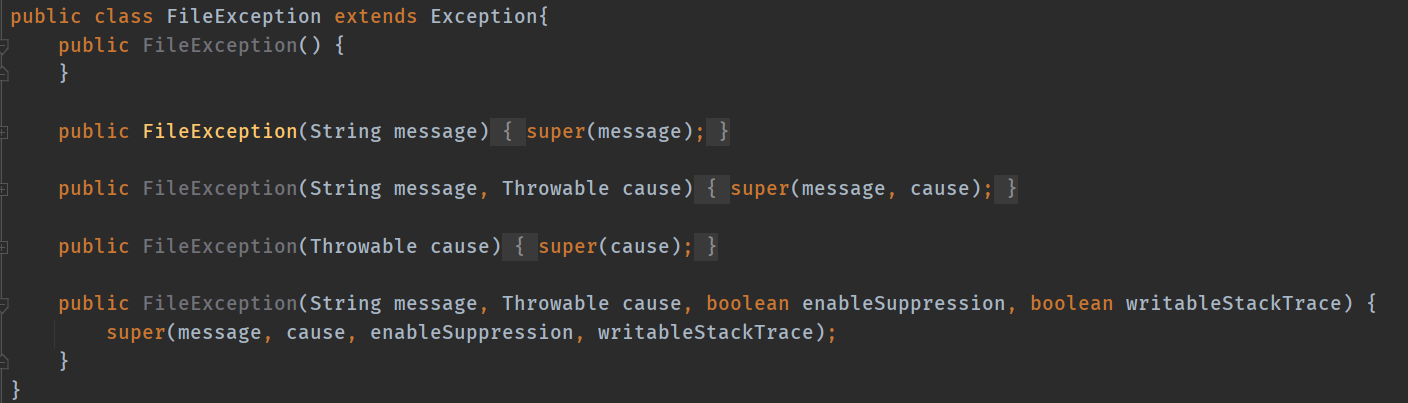
对文件为空或其他问题时抛出异常

 浙公网安备 33010602011771号
浙公网安备 33010602011771号