了解GraphRAG
了解GraphRAG
- 开源地址:https://github.com/microsoft/graphrag
- 论文:From Local to Global: A Graph RAG Approach to Query-Focused Summarization
- 博客介绍:https://microsoft.github.io/graphrag/
传统RAG
LLM预训练和微调一般都是基于公开的互联网数据,不可能包含公司内部私有数据,如果你问有关某公司的运营情况,直接基于模型参数生成的回答可能和胡说八道没什么两样。
RAG(Retrieval-Augmented Generation,检索增强生成)的思想就是将私有数据作为参考信息传递给LLM。这些私有数据除了作为一种补充信息,也可以作为一种限制,能避免LLM产生幻觉。
参考信息一般以文本、图片等非结构化形式存在。
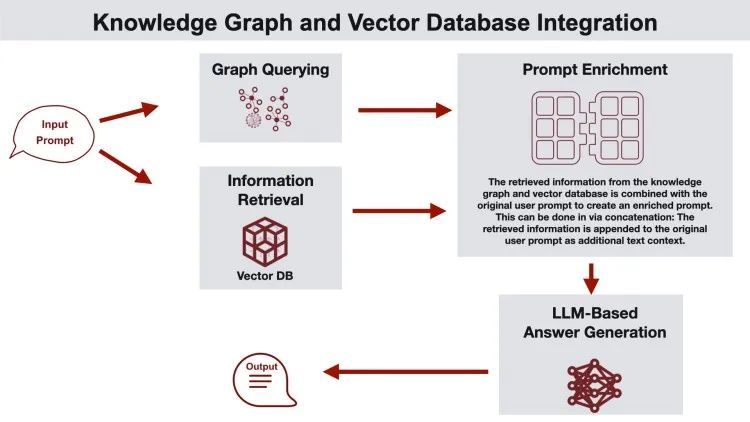
RAG的流程是:
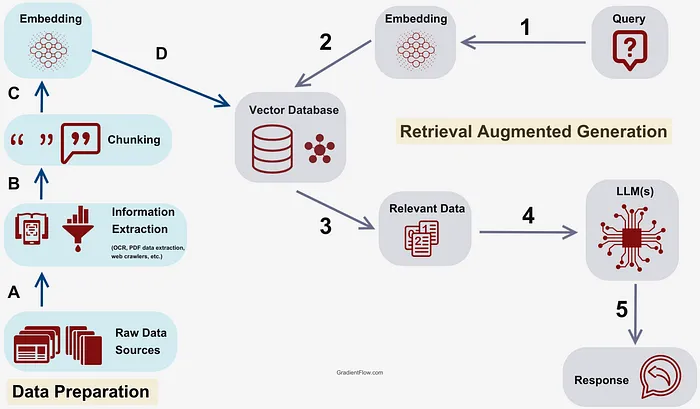
- 首先要将文本划分成片段,然后将片段转换成向量存储到向量数据库中备用,这个向量就是这段文本语义信息的数字表示。
- 将用户查询转换成向量,并与所有文本片段向量进行相似度计算,取出top k个片段。
- 将用户查询和k个文本片段组织成特定prompt格式输入到LLM中。
GraphRAG
但传统的RAG仍有一些限制。
例如,基于某个公司的运营数据搭建RAG,由于LLM上下文大小的限制,划分的文本片段不可能太大,所以每个文本片段不可能包含太多信息。
如果你问某个员工去年的销售业绩,基于RAG,LLM很可能会给出准确回答,因为某个文本片段很可能包含了某个员工的年终总结信息。但如果你问该员工所在团队去年的销售情况呢?就算某个文本片段包含了该团队的销售数据,LLM也很难通过该员工找到团队的其它成员。
微软最近提出的GraphRAG(Graph-based Retrieval Augmented Generation) 就是解决这个问题。
GraphRAG就是将图和传统的RAG结合了起来。
构造知识图谱
图是由节点和边组成的,节点可以表示各种实体,边表示实体之间的关系。
GraphRAG的核心就是构造知识图谱,可以通过GPT4或者使用像llamaindex(KnowledgeGraphIndex)这样的库构造知识图谱。
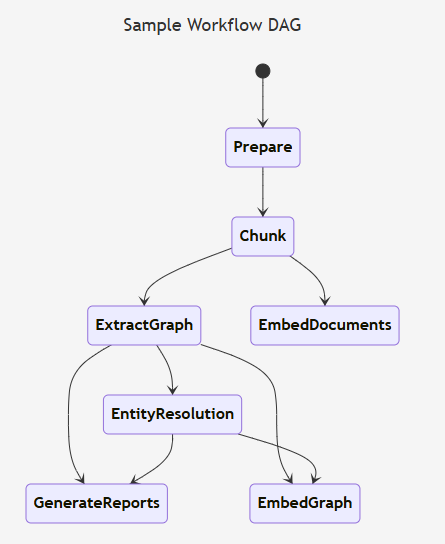
将公司运营文档构造成知识图谱:
- 识别出文档中包含的实体以及实体之间的关系(员工,同事)
- 将实体进行聚类(同组同事)
- 对每个聚类进行总结(销售情况)
- 将实体进行向量化,转换到图向量空间
- 提取实体对应的原始文本,并转换成向量
查询
当用户提问时,首先在知识图谱中找到与用户提问语义相关的实体,同时找到与实体相关的原始文本,最后将这些信息组织成特定prompt格式输入给LLM。