大模型显存计算
大模型微调需要多少GPU显存?
如:微调 1B 模型,16bit = 2byte
- 全量微调
显存占用分为:
- model weight(参数本身):10亿(bit) = 20亿(byte)约等于2GB
训练模型时,通过一系列反向传播的方法,来更新模型参数,涉及以下gradient和optimizer states参数。
不断计算梯度,以更新模型参数
- gradient(梯度):近似2GB
- optimizer states(优化器):近似4倍的
model weight,即8GB - Activation:忽略不计
共12GB,约6倍的model weight显存。
- 高效微调(PEFT)
- LoRA微调:以更少量的参数进行学习,从而对原有模型微调。
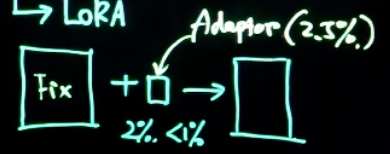
原有模型model weight为2GB
Adaptor weight为0.05GB(如按2.5%的比例)
gradient和optimizer states约为0.25GB(如按2.5%的比例)
共约2.3GB。
- QLoRA微调:对原有参数(
model weight)进一步压缩,如将原有的16bit转换为8bit或者4bit。
论文推荐:
- GPU估计: LLMem: Estimating GPU Memory Usage for Fine-Tuning Pre-Trained LLMs
- QLoRA:Efficient Finetuning of Quantized LLMs
- LoRA: Low-Rank Adaptation of Large Language Models

 浙公网安备 33010602011771号
浙公网安备 33010602011771号