了解显卡
硬件
ROG Strix RTX 4080为例:
- 供电接口:8pin接口,单个提供225w供电,高功耗可使用多个

该4080提供6个供电接口:

还有背插显卡,无需外接供电,需搭载特定主板和转接头使用:

- 散热模组由:风扇、鳍片、热管、均热板组成

热管利用汽热转换传递热量

- 电路板结构,其中gpu芯片由nvdia、amd、intel三家供应

AIC厂商(如华硕)完成电路板与散热的设计和生产

- 视频接口,对外传输图像

- PCIe接口,与主板、cpu、内存等元器件交互,如PCIe4.0单通道传输速率为2GB

- 供电模块:核心PWM、电容、MOS管、现存PWM、电感组成


-
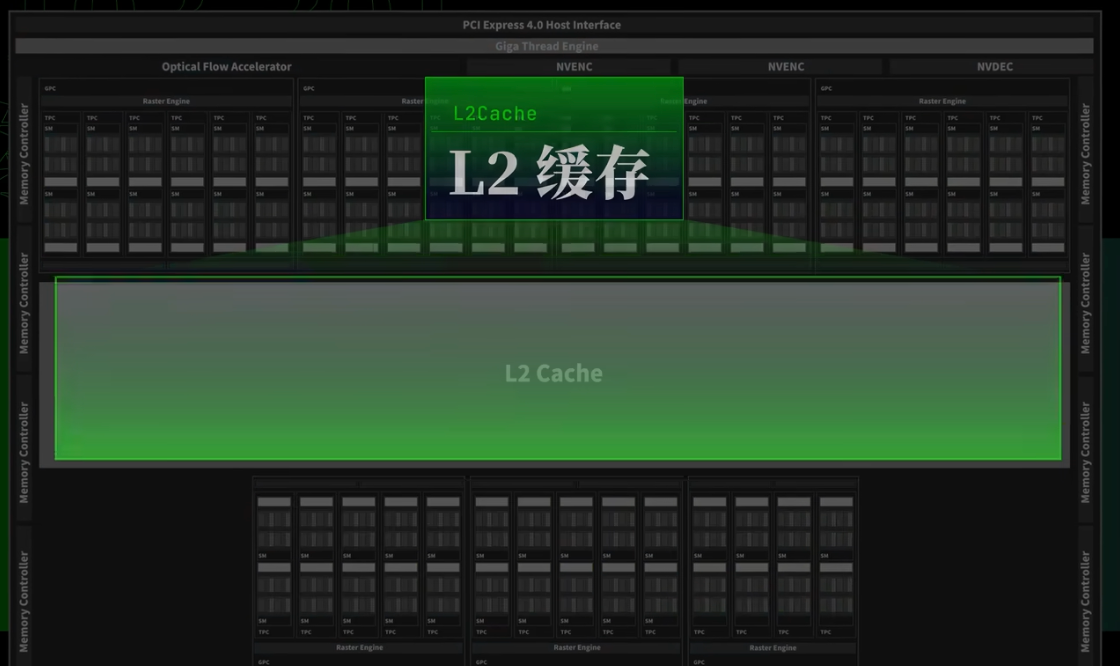
显存的总带宽(每秒传输的数据量)由频率、位宽、倍增系数决定的
- 频率:每秒传输多少个周期
- 位宽:一次(周期)可以传输的数据量
- 倍增系数:发挥多少倍性能


-
显卡的gpu核心
-
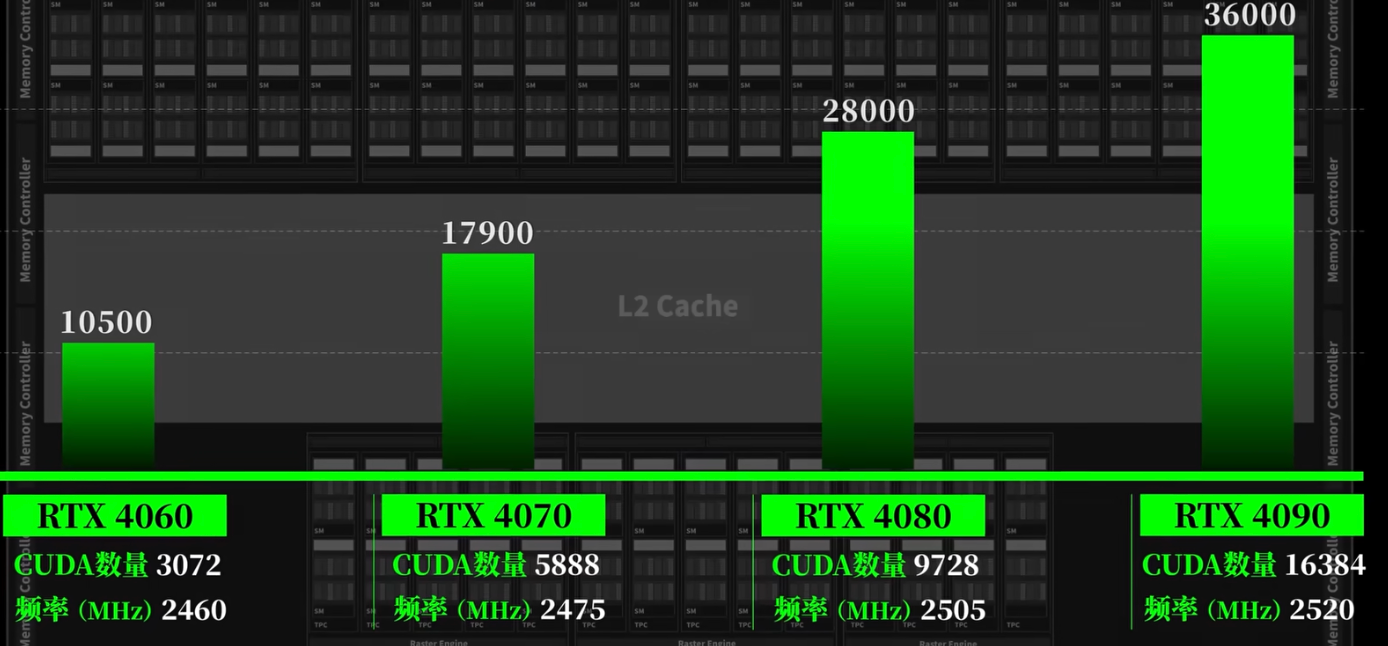
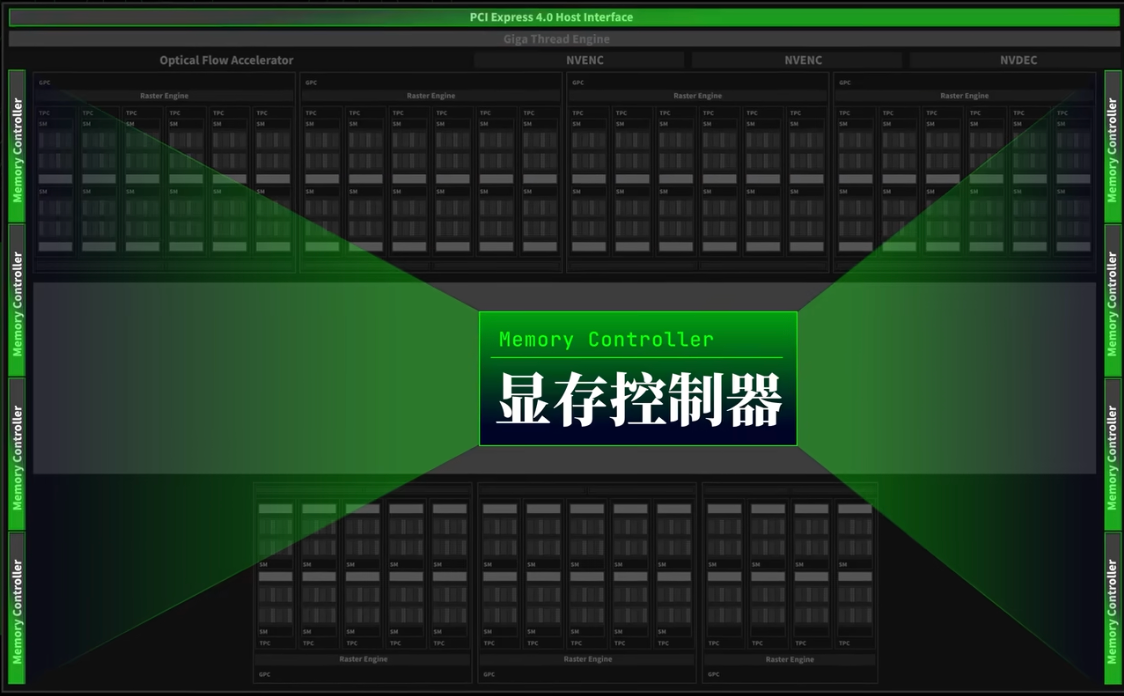
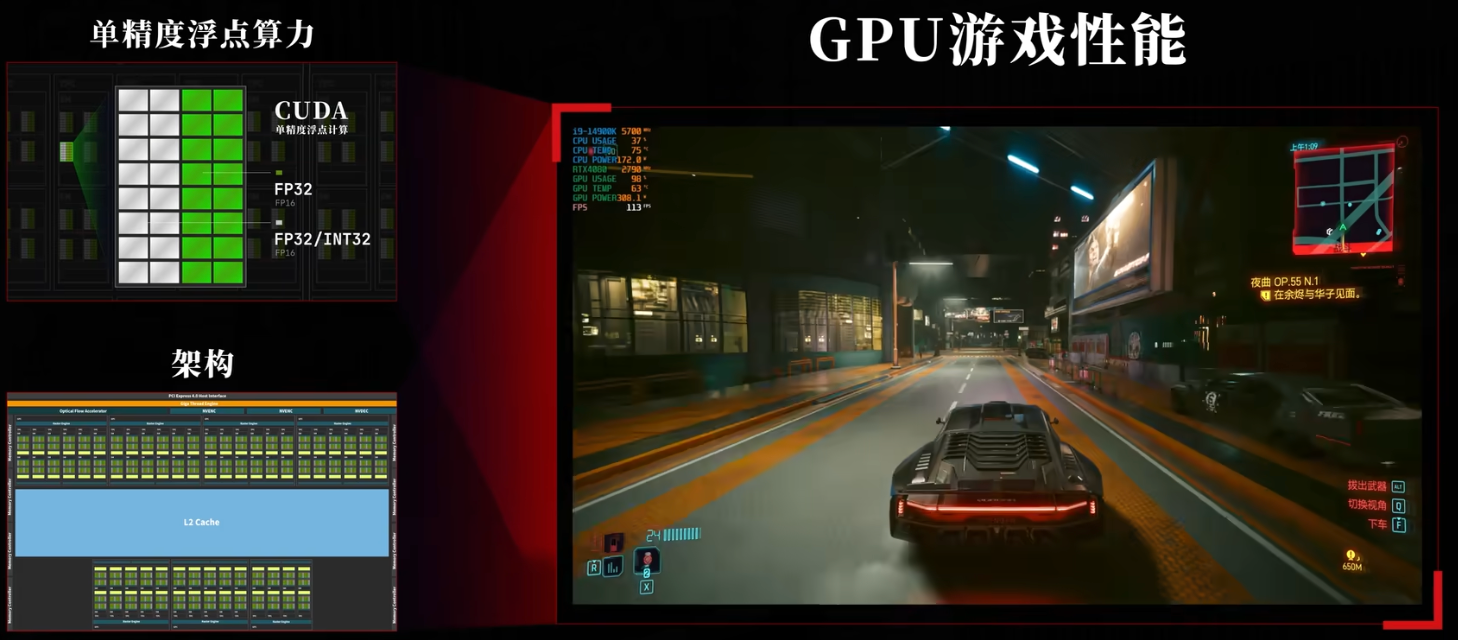
SM流式多处理器,负责几乎所有的图形运算,例如由76颗SM计算单元,每组SM单元中由128个流处理器,共9728个流处理器(也叫做CUDA核心),【处理器个数越多、频率越高,性能越强】,若每组看成一个核心,就相当于76个核心,9728个线程的处理器,显卡核心数量决定算力。
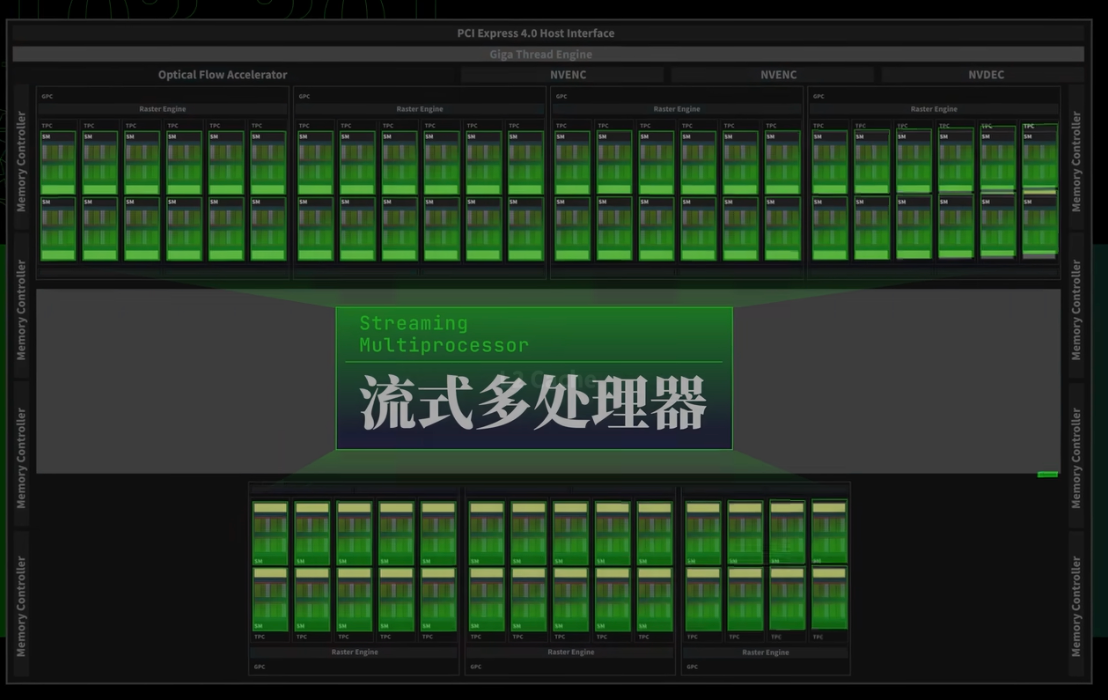
- nvidia ada-lovelace架构,459亿颗晶体管
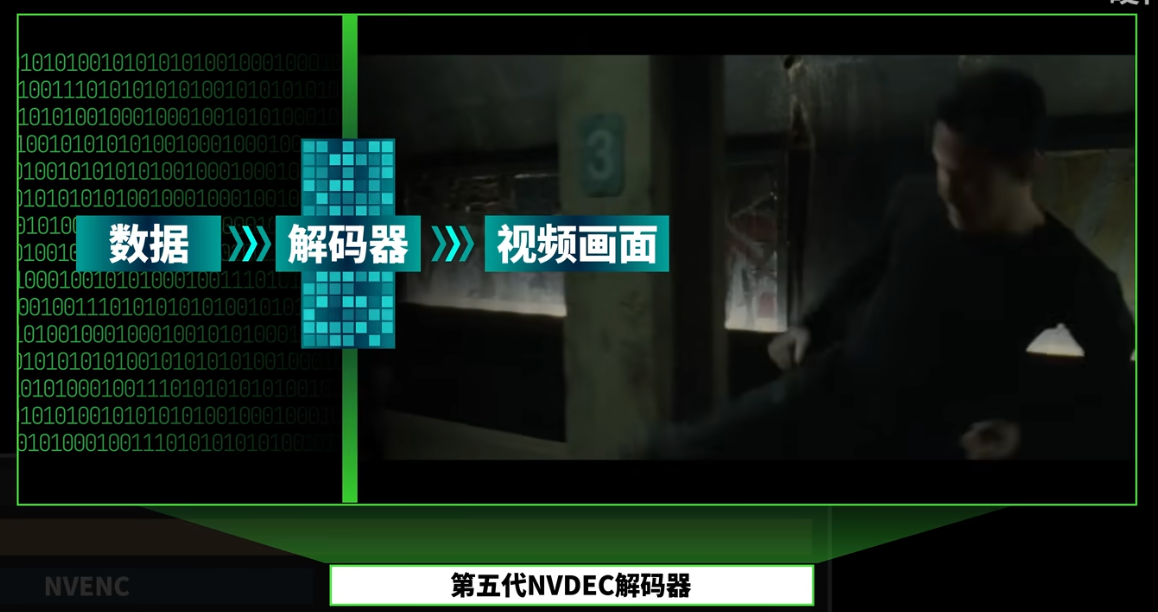

- 显卡更适合做简单的四则运算
三角面的顶点坐标(x,y,z),用32位的二进制表示,也叫做单精度浮点数(FP32)

每秒能计算的次数就是单精度浮点算力,用于衡量图形渲染的性能。
GPU对比CPU更加适合图形渲染

一个CUDA核心能支持FP32计算,也能向下兼容半精度FP16计算。

gpu的效率也和设计架构有关。




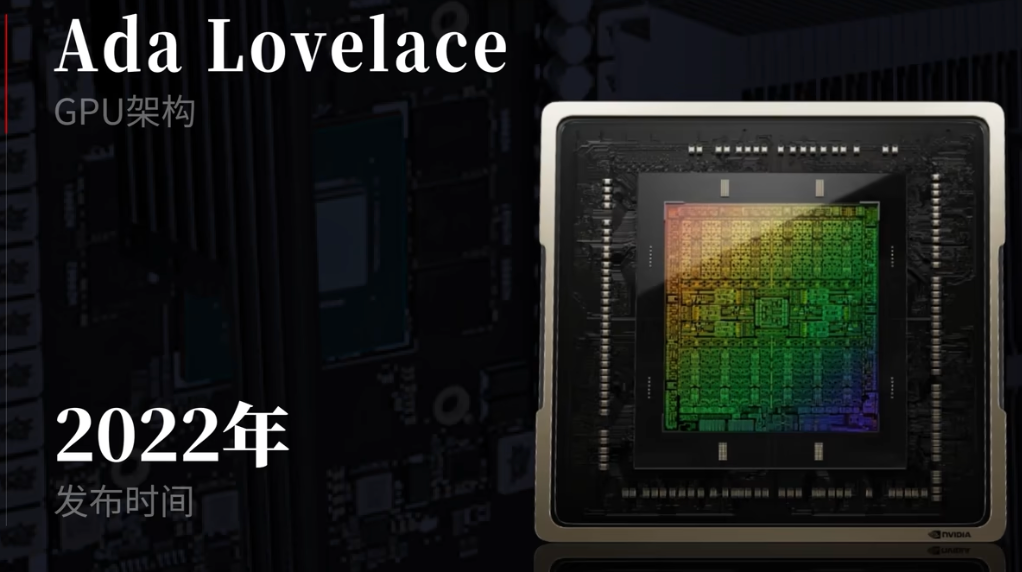
架构不同,性能也不同。
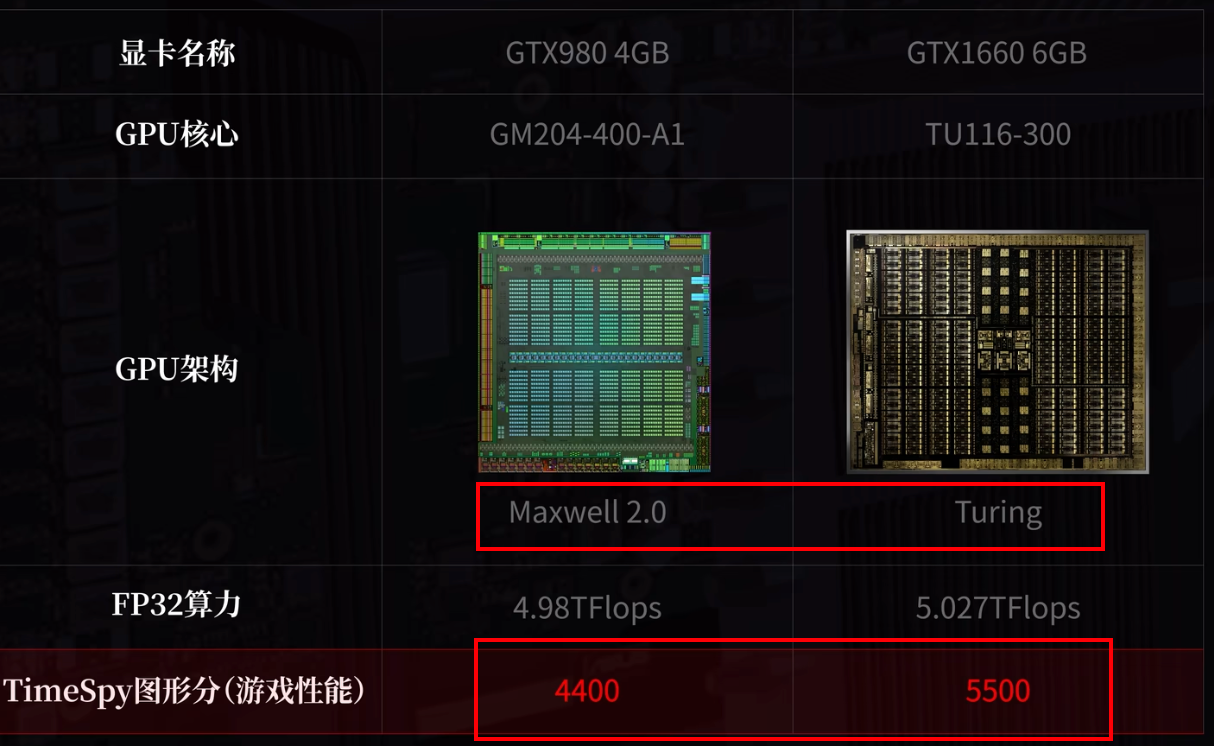
- 单精度浮点算力和架构决定了gpu的游戏性能。
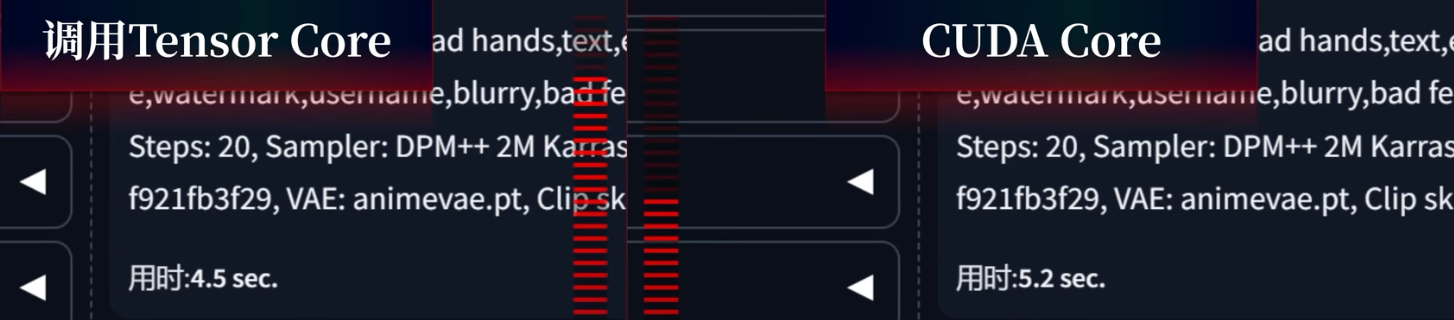
用于AI
CUDA核心的旁边是第4代Tensor Core张量核心,适合做AI相关的深度学习计算,如AI绘图软件可以调用Tensor Core,生成图片的速度比纯CUDA快。

- 主流显卡TimeSpy跑分天梯图
- 主流AIC厂商

- 显卡子型号


