



第20章 keras中“开箱即用”CNNs
第20章 keras中“开箱即用”CNNs
到目前为止,我们学习了如何从头开始训练CNNs。这些CNNs大多数工作在浅层(以及较小数据集上),以至于它们可以很容易的在CPU上训练,而不需要在更贵的GPU上,这使得我们能够掌握神经网络和深度学习的基础。
但是由于我们只在浅层网络上工作,我们无法利用深度学习带给我们的全分类能力。幸运的是,keras库预置了5种在ImageNet数据集上预训练的CNNs:
l VGG16
l VGG19
l ResNet50
l Inception V3
l Xception
就像第5章讨论的,ILSVRC的目标是训练一个可以将图片正确的分类到1000种不同对象类别的模型。这1000种图像分类表示了我们日常见到的常见分类,如狗、猫、不同车辆等等类型。
这意味着如果我们利用在ImageNet数据集上预训练的CNNs,我们可以“开箱即用”(out-of-the-box)的识别出所有这些1000种类别,而不需要重新训练。
本章,我们将回顾内置在keras库中的预训练的最新的ImageNet模型。之后,将演示如何写python脚本利用这些网络来分类我们自定义的图像,而不需要从头训练这些模型。
1 Keras中最新的CNNs
此时,你可能想:“我没有贵重的GPU。我怎么利用这些大的深度学习模型呢?因为它们在数据集上预训练要比本书中我们做的要大得多?”
要回答这个问题,回到第8章的参数化学习,回顾参数化学习的两个要点:
(1)定义一个机器学习模型,它可以在训练时间内从输入数据中学习模式(需要我们花费大量时间在训练过程中),但是在测试过程中将快速的多;
(2)获得一个可以用少量参数定义的模型,这些参数可以很容易的表示网络,而不管训练集大小。
因此,我们实际的模型尺寸是参数的函数,而不是训练数据的量。我们可以在1亿张图片或1000张图片的数据集上训练训练一个很深的CNN(如VGG或ResNet),但是我们的输出模型尺寸是相同的,因为模型尺寸是由我们选择的架构决定的。
其次,神经网络占据了大部分时间,我们将花费大量时间来训练CNNs,不管这是由于架构很深、训练数据量很大、还是由于调参而大量实验造成的。
优化的硬件如GPUs可以加速我们在BP算法中前向和后向都需要计算的训练过程,我们知道这个过程实际上是我们的网络学习的过程。但是,一旦我们的训练完成后,我们只需要执行前向过程来分类一张给定的输入图像。前向过程实际上是非常快的,这使我们可以在CPUs上使用深度神经网络来分类给定图片。
在大多数情况下,本章的网络架构在CPU上将不会获得真正的实时性能(那样我们需要GPU),但也是可以的,我们仍可以将它们用在自定义的应用上。如果你对如何从头在ImageNet数据集上训练最新的CNNs感兴趣,那么看作者在ImageNet Bundle中的精确的示例。
1.1 VGG16和VGG19

图20.1 VGG架构可视化
VGG网络架构在2014年论文《Very Deep Convolutional Networks for Large Scale Image Recognition》中介绍,见图20.1。就像我们在第15章讨论的,VGG家族的网络的特点是,仅使用3×3的卷积层随着深度增加堆叠在一起。通过max pooling处理降低卷大小。每个都为1096的两个FC层之后跟着一个softmax层。
在2014年,16和19层的神经网络认为是很深的,尽管现在ResNet架构可以在ImageNet上成功的训练在50-100层以及在CIFAR-10上训练到1000层。不幸的是,VGG有两个缺陷:
(1)训练极其慢(幸运的是本章我们只需要测试输入图像);
(2)网络权重本身相当大。由于深度和FC节点的数目,VGG16序列化的权重文件是533MB而VGG19是574MB。
幸运的是,这些权重只需要下载一次,之后就可以从磁盘上加载它们。
1.2 ResNet
ResNet第一次在2015年论文《Deep Residual Learning for Image Recognition》中介绍,该架构就称为深度学习文献的开创性工作,证明了通过使用残差模块(residual modules)就可以通过使用标准的SGD(和一个合理的初始化函数)来训练很深的网络。

图20.2 左:原始残差模块 右:使用预激活的残差模块
通过使用身份映射(identity mappings)(见图20.2)来更新残差模块可以进一步提高正确率,这在2016年的文章《Identity Mappings in Deep Residual Networks》被证明。
也就是说,注意在keras核心库中实现的ResNet50(也就是50个权重层)是以2015年的论文为基础。尽管ResNet比VGG16和VGG19深的多,但是由于使用了global average pooling而不是FC层,它的权重尺寸是相当小的,即对于ResNet50的模型尺寸减小到了102MB。
如果你对ResNet架构的学习感兴趣,包括残差模块和它是如何工作的,去看更详细的Practitioner Bundle和ImageNet Bundle。
1.3 Inception V3
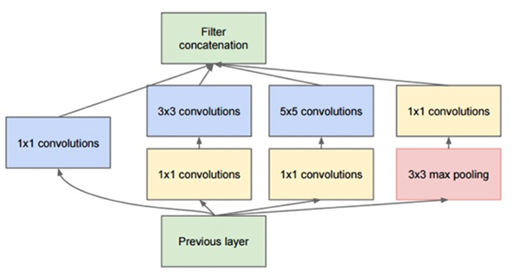
图20.3 在GoogLeNet中使用的原始Inception模块
这个“Inception”模块(导致了Inception架构)在2014年的文章《Going Deeper with Convolutions》介绍。Inception模块(见图20.3)的目标是扮演“多级特征提取器”,通过在网络的相同模块上计算1×1、3×3和5×5的卷积,这些过滤器的输出在进入网络的下一层之前沿着通道维度堆叠在一起。
这个架构的原始化身称为GoogLeNet,但是随后出现的现象简单的将它命名为Inception vN,这里的N是由Google指出的版本号。包含在keras核中的Inception V3架构来自之后出版的《Rethinking the Inception Architecture for Computer Vision》,他对Inception模块提出更新来进一步提升ImageNet的分类正确率。Inception V3的权重比VGG和ResNet都要小,达到了96MB。
对于Inception模块工作的更多信息(以及如何从头训练GoogLeNet),见Practitioner Bundle 和ImageNet Bundle。
1.4 Xception
正是keras库的创建者和主要维护者François Chollet本人在2016年的文章《Xception: Deep Learning with Depthwise Separable Convolutions》中提出了Xception。Xception是Inception架构的延伸,它使用深度可分离卷积(depthwise separable convolutions)替代了标准的Inception模块。这个Xception权重是包含在keras库中预训练的网络中最小的,权重只有91MB。
1.5 还有更小的架构吗?
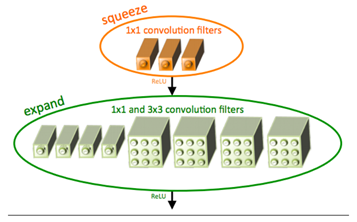
图20.5 SqueezeNet中的“fire”模块。
尽管没有包含在keras库中,我还要提到的一种当我们需要小卷积核时经常使用的SqueezeNet架构,见文章《SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <1MB model size》,如图20.5所示,包含一个“squeeze”和一个“expand”。SqueezeNet非常小只有4.9MB且经常用在当需要对网络进行训练,然后将其部署到网络和/或资源受限的设备时。
再次说明,尽管SqueezeNet没有包含在keras核心中,但是我将在ImageNet Bundle中在ImageNet数据集上从头演示如何训练它。
2 使用预训练的ImageNet CNNs分类图像
让我们学习如何使用keras库在预训练的CNNs上分类图像。我们不会更新到目前为止我们已经开发的pyimagesearch模块,因为预训练的模型是keras库的一部分。
仅仅打开文件命名为imagenet_pretrained.py,键入代码即可,见GitHub的chapter20/下。
训练模型时,通过python imagenet_pretrained.py --image example_images/test01.jpg --model vgg16即可。
3 总结
本章回顾了keras库自带的5中预训练模型:VGG16、VGG19、ResNet50、Inception V3、Xception。
但是,对于想要在大数据集上训练深度网络更高级技术的学习,建议浏览Practitioner Bundle。如果对如何从头训练这些模型感兴趣,见ImageNet Bundle。

