



第14章 LeNet:识别手写数字
第14章 LeNet:识别手写数字
LeNet架构时深度学习社区的一个开创性工作,见论文【1】,作者在实现LeNet的主要创新点是用于OCR上。LeNet架构简单轻巧(就内存占用而言),这使它成为教授CNNs的完美之选。在本章,我们将复制类似于1998年LeCun的论文中的实验。我们首先回顾LeNet架构,之后使用keras实现网络,最后将它用在MNIST数据集上评估手写数字识别。
1 LeNet架构
我们在第12章使用ShallowNet探索了CNN构建块,现在我们看看现实中第一个完美的架构LeNet,该架构简单直接但结果很优异。
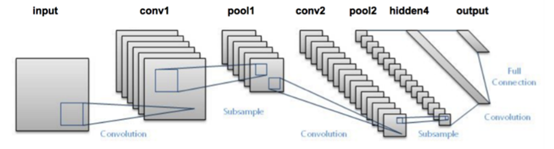
图14.1 LeNet架构
LeNet+MNIST组合实验很容易运行在CPU上,类似于“Hello World”实验。LeNet架构包含CONV=>ACT=>POOL的模式结构:

注意,在上述架构中使用Tanh作为激活函数而不是ReLU,是因为在1998年左右更常见的是使用tanh或sigmoid,直到今天,更常见的是使用ReLU代替tanh。我们在后续实验中将使用ReLu函数。

表14.1 LeNet架构总结
表14.1列出了LeNet架构的参数,我们的输入层为28×28×1,之后学习20个核,每个核5×5大小。卷积层之后跟随一个POOL层,POOL层计算为核2×2、stride为2×2的max pooling。
架构的下一个块采取类似结构,这次学习50个5×5的过滤器。随着实际的空间输入维度的减少,在网络的更深层上增加卷积层的数目是很常见的。
之后我们有两个FC层,第一个FC层包含500个隐藏节点,之后跟着ReLU激活。最后一个FC层控制输出类别标签的数目(这个例子中为0-9分别代表一个数字)。最后跟着一个softmax激活层,获得每个类别的输出概率。
2 实现LeNet
给定14.1的表,我们使用keras库实现LeNet架构。我们在chapter12/pyimagesearch/nn/conv下新建一个名为lenet.py的文件,该文件包含实际的LeNet实现。
我们将chapter12/pyimagesearch文件夹拷贝到chapter14/下,然后打开lenet.py文件,开始键入LeNet网络实现,具体见GitHub。
from keras.model import Sequential,这个方法是网络构建一层一层的构建块初始化,之后可按照架构蓝图一层一层配置。那么,第一个conv=>relu=>pool配置如下:

对照程序代码,以及表14.1,我们按照keras层构建方法,一步步即可构建出最终的LeNet模型。
构建完后,由于我们在后面需要导入该模型,因此需要在nn.conv.__init__.py中添加两行模块说明:
from .lenet import LeNet __all__=[‘ShallowNet’, ‘LeNet’]
3 在MNIST上实施LeNet
下一步我们创建一个脚本,用于从磁盘加载MNIST数据集、初始化LeNet架构、训练LeNet、评估网络性能。
我们在chapter14/下创建一个名为lenet_mnist.py的文件,然后键入代码,代码见GitHub。此时我们的python构建脚本将变得比较标准,且具备比较通用框架。在本书的大量例子中,我们将导入:
(1)我们要训练的网络架构
(2)一个训练网络的优化器(如SGD)
(3)给定训练集时用于构建和划分训练和测试集的合适函数
(4)评估分类器性能的计算分类报告的函数
本书之后几乎所有例子都遵循这种导入模式,当然也会添加一些辅助函数,如argparse等模块。
MNIST数据集已经预处理过了,且每个数字图片为28×28=784维数据,我们要根据是否通道优先来改变排列顺序,见代码。
我们按照网络蓝图构建了一个特定网络架构实现之后,我们在训练脚本中,通过上述步骤加载必要的模块后。一般的设计脚本步骤为:加载必要模块、加载数据集、按照模型要求对数据集大小等预处理、按照keras通道优先要求处理数据、划分数据集、标签转为向量形式、初始化优化器和模型、训练模型、评估网络、显示网络性能曲线。
训练完成后, 性能曲线如图所示:
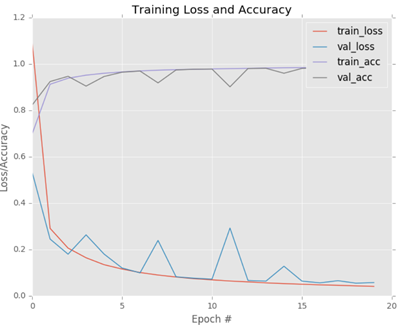
可看到使用LeNet后,训练正确率接近98%,比第10章中的前向网络的92%的正确率提高了很多。由训练损失和正确率曲线,可看到在5轮之后,我们的正确率就接近到96%,这说明我们的网络特性相当好。我们的训练和验证损失持续下降,只在部分点上出现跳动,这是由于学习率为常量的缘故,这将在第16章讨论。
这个图表演示了损失和正确率之间很好的性能,没有过拟合的迹象。这种如此好的训练图表,暗示了我们的网络学习到了潜在的模式而没有发生过拟合。
MNIST数据集的问题是图像被过度预处理了而不能代表现实世界中真实的图像分类问题。研究者倾向于使用MNIST数据集作为基准测试来评估新的分类算法。如果新的方法没有获得>95%的分类正确率,那么存在缺陷要么是算法本身要么是算法实现上。
4 总结
本章中,我们实现了经典的LeNet网络模型,尽管经典,但是它仅实现了4个可训练层(2个CONV层和2个FC层)。考虑到今天的最新的网络架构如VGG(16或19层)和ResNet(100+层),LeNet仍然是一个比较浅的网络(Shallow network)。
下一章,我们将讨论VGGNet的变种,作者称为“MiniVGGNet”。这个架构变种与【2】中的架构原理一模一样,只是减少了层数允许我们可以在较小的数据集上训练网络。对于VGGNet的完全实现,可以见ImageNet Bundle的第6章将从头在ImageNet上实现。
5 附录
[1] Yann Lecun et al. “Gradient-based learning applied to document recognition”. In: Proceedings of the IEEE. 1998, pages 2278–2324 (cited on pages 24, 195, 219, 227).
[2] Karen Simonyan and Andrew Zisserman. “Very Deep Convolutional Networks for LargeScale Image Recognition”. In: CoRR abs/1409.1556 (2014). URL: http://arxiv.org/abs/1409.1556 (cited on pages 113, 192, 195, 227, 229, 278).

