scrapy的使用
Scrapy是Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
css
- css选择器中如果是查看标签是直接写response.css('标签'),后面可带上.class名,或者@id
- 如果是多层的,就像样式那样写就好了 比如
<div class="tags"><a class="tag"></a></div>
写成 response.css('.tags .tag') 就获取到a标签了
- 内容的提取(标签名/样式 ::text)
- 嵌套标签内容的提取(*::text)
例如一个文章由多个p标签组成的,你想一下子取到,就可以使用这个,如:
response.css(".post-content *::text").extract()
- 属性值的提取 (标签名/样式 ::attr(属性名)))
- css高级用法(来源:菜鸟教程,文末附录)
xpath
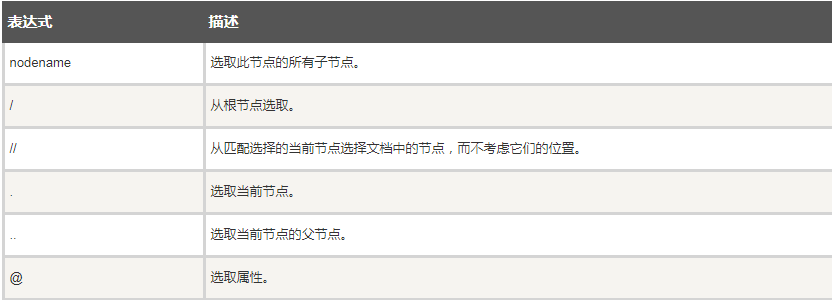
- 属性提取 //@属性
- 提取内容 //text()
- 包含HTML标签的所有文字内容提取 //string(要提取内容的标签)
其他函数的使用
- extract(),extract_first(),extract()[n]
extract() 获取所有符合条件的标签
extract_first() 获取符合条件的第一个标签
extract()[n] 获取符合条件的第n个标签
调试
scrapy shell url地址 可调试是否选择中了标签
附录
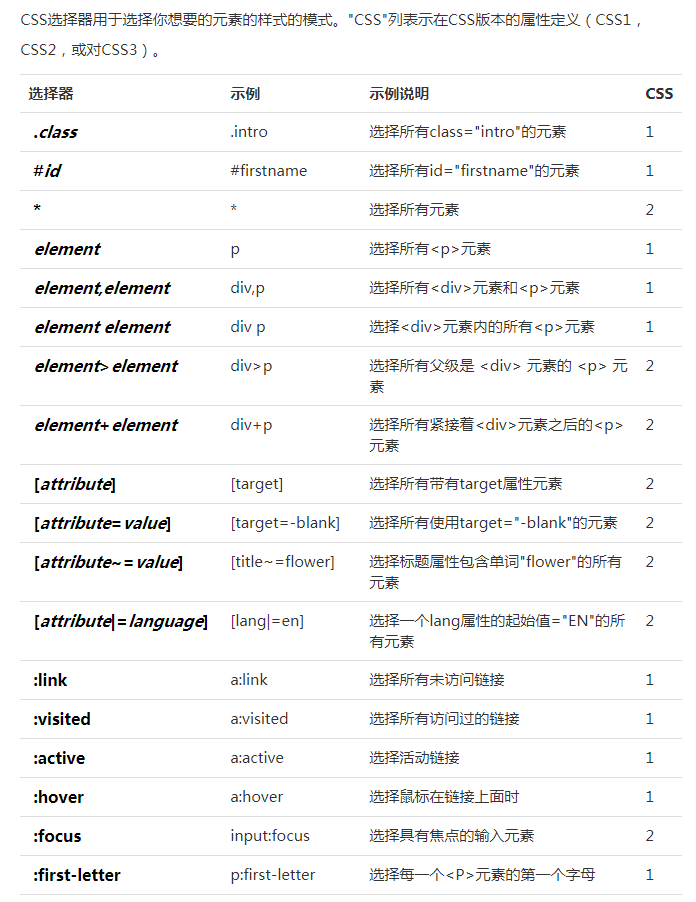
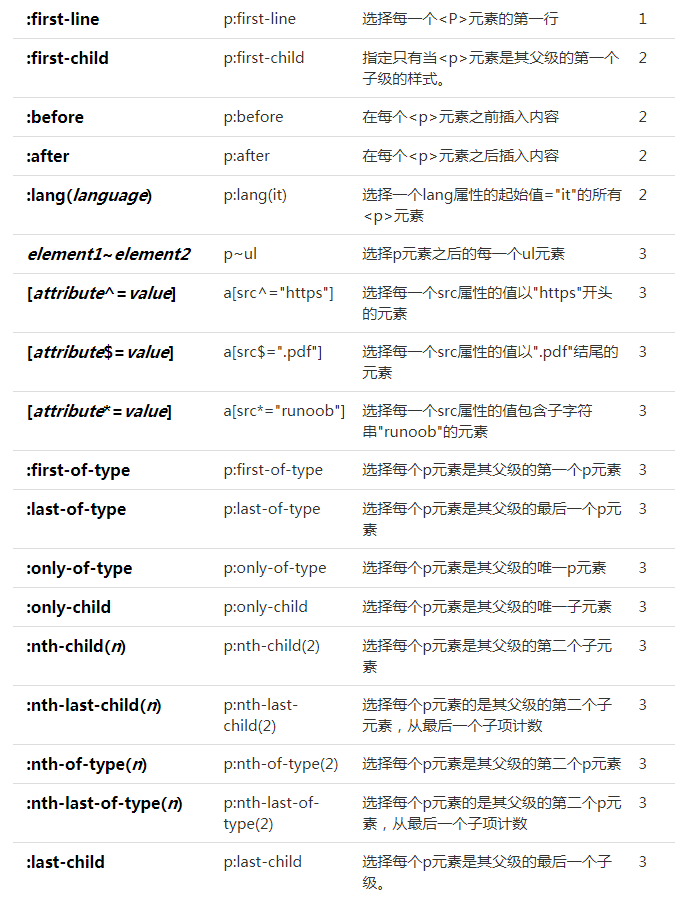
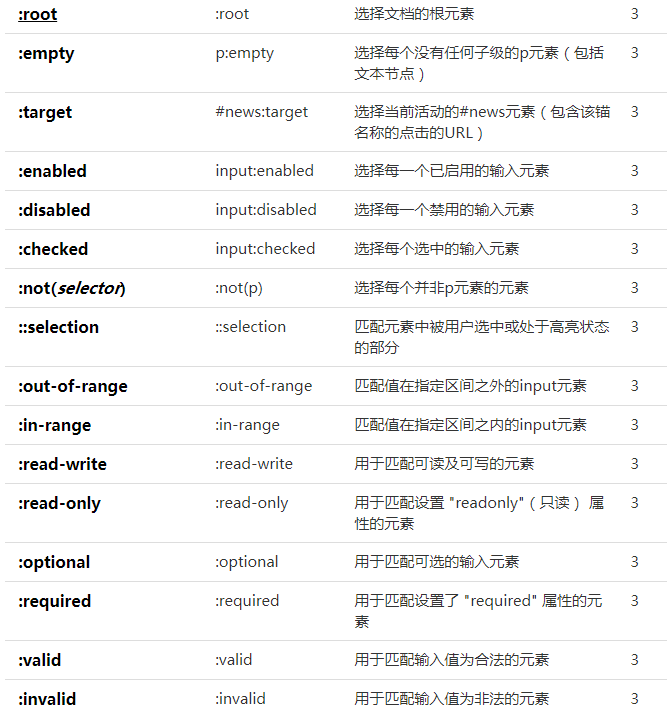
参考链接:
不负光阴不负卿

 浙公网安备 33010602011771号
浙公网安备 33010602011771号