

faiss 没有提供余弦距离怎么办
参考:https://zhuanlan.zhihu.com/p/40236865
faiss是Facebook开源的用于快速计算海量向量距离的库,但是没有提供余弦距离,而余弦距离的使用率还是很高的,那怎么解决呢
答案说在前面
knowledge_embedding = np.random.random((1000, 300)).astype('float32') # 1000个待查知识点
query_embedding = np.random.random((100, 300)).astype('float32') # 100个查询语句
normalize_L2(knowledge_embedding) # 熟悉余弦相似度公式的都知道,点击后会除于长度,所以要把长度归一化到1,就可以直接点击算出余弦相似度
normalize_L2(query_embedding) # 熟悉余弦相似度公式的都知道,点击后会除于长度,所以要把长度归一化到1,就可以直接点击算出余弦相似度
index = faiss.IndexFlat(d, faiss.METRIC_INNER_PRODUCT) # 等价 index=faiss.IndexFlatIP(d)
index.add(knowledge_embedding) # 把知识点加到索引里面
D, I =index.search(query_embedding, k=5) # 召回5个
进一步实验
import faiss
from faiss import normalize_L2
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
import copy
def faiss_cos_similar_search(x, k=None):
#
assert len(x.shape) == 2, "仅支持2维向量的距离计算"
x = copy.deepcopy(x)
nb, d = x.shape
x = x.astype('float32')
k_search = k if k else nb
normalize_L2(x)
index = faiss.IndexFlat(d, faiss.METRIC_INNER_PRODUCT)
# index=faiss.IndexFlatIP(d)
# index.train(x)
# index=faiss.IndexFlatL2(d)
index.add(x)
D, I =index.search(x, k=k_search)
return I
def sklearn_cos_search(x, k=None):
assert len(x.shape) == 2, "仅支持2维向量的距离计算"
x = copy.deepcopy(x)
nb, d = x.shape
ag=cosine_similarity(x)
np.argsort(-ag, axis=1)
k_search = k if k else nb
return np.argsort(-ag, axis=1)[:, :k_search]
def test_IndexFlatIP_only(nb = 1000, d = 100, kr = 0.005, n_times=10):
k = int(nb * kr)
print("recall count is %d" % (k))
for i in range(n_times):
x = np.random.random((nb, d)).astype('float32')
# x = np.random.randint(0,2, (nb,d))
# faiss_I = faiss_cos_similar_search(x, k)
index=faiss.IndexFlatIP(d)
index.train(x)
index.add(x)
D, faiss_I =index.search(x, k=k)
sklearn_I = sklearn_cos_search(x, k)
cmp_result = faiss_I == sklearn_I
print("is all correct: %s, correct batch rate: %d/%d, correct sample rate: %d/%d" % \
(np.all(cmp_result), \
np.all(cmp_result, axis=1).sum(),cmp_result.shape[0], \
cmp_result.sum(),cmp_result.shape[0]*cmp_result.shape[1] ) )
def test_embedding(nb = 1000, d = 100, kr = 0.005, n_times=10):
k = int(nb * kr)
print("recall count is %d" % (k))
for i in range(n_times):
x = np.random.random((nb, d)).astype('float32')
# x = np.random.randint(0,2, (nb,d))
faiss_I = faiss_cos_similar_search(x, k)
sklearn_I = sklearn_cos_search(x, k)
cmp_result = faiss_I == sklearn_I
print("is all correct: %s, correct batch rate: %d/%d, correct sample rate: %d/%d" % \
(np.all(cmp_result), \
np.all(cmp_result, axis=1).sum(),cmp_result.shape[0], \
cmp_result.sum(),cmp_result.shape[0]*cmp_result.shape[1] ) )
def test_one_hot(nb = 1000, d = 100, kr = 0.005, n_times=10):
k = int(nb * kr)
print("recall count is %d" % (k))
for i in range(n_times):
# x = np.random.random((nb, d)).astype('float32')
x = np.random.randint(0,2, (nb,d))
faiss_I = faiss_cos_similar_search(x, k)
sklearn_I = sklearn_cos_search(x, k)
cmp_result = faiss_I == sklearn_I
print("is all correct: %s, correct batch rate: %d/%d, correct sample rate: %d/%d" % \
(np.all(cmp_result), \
np.all(cmp_result, axis=1).sum(),cmp_result.shape[0], \
cmp_result.sum(),cmp_result.shape[0]*cmp_result.shape[1] ) )
if __name__ == "__main__":
print("test use IndexFlatIP only")
test_IndexFlatIP_only()
print("-"*100 + "\n\n")
print("test when one hot")
test_one_hot()
print("-"*100 + "\n\n")
print("test use normalize_L2 + IndexFlatIP")
test_embedding()
print("-"*100 + "\n\n")
下面是实验结果,比较faiss和sklearn实现的余弦相似度召回顺序是不是完全一样
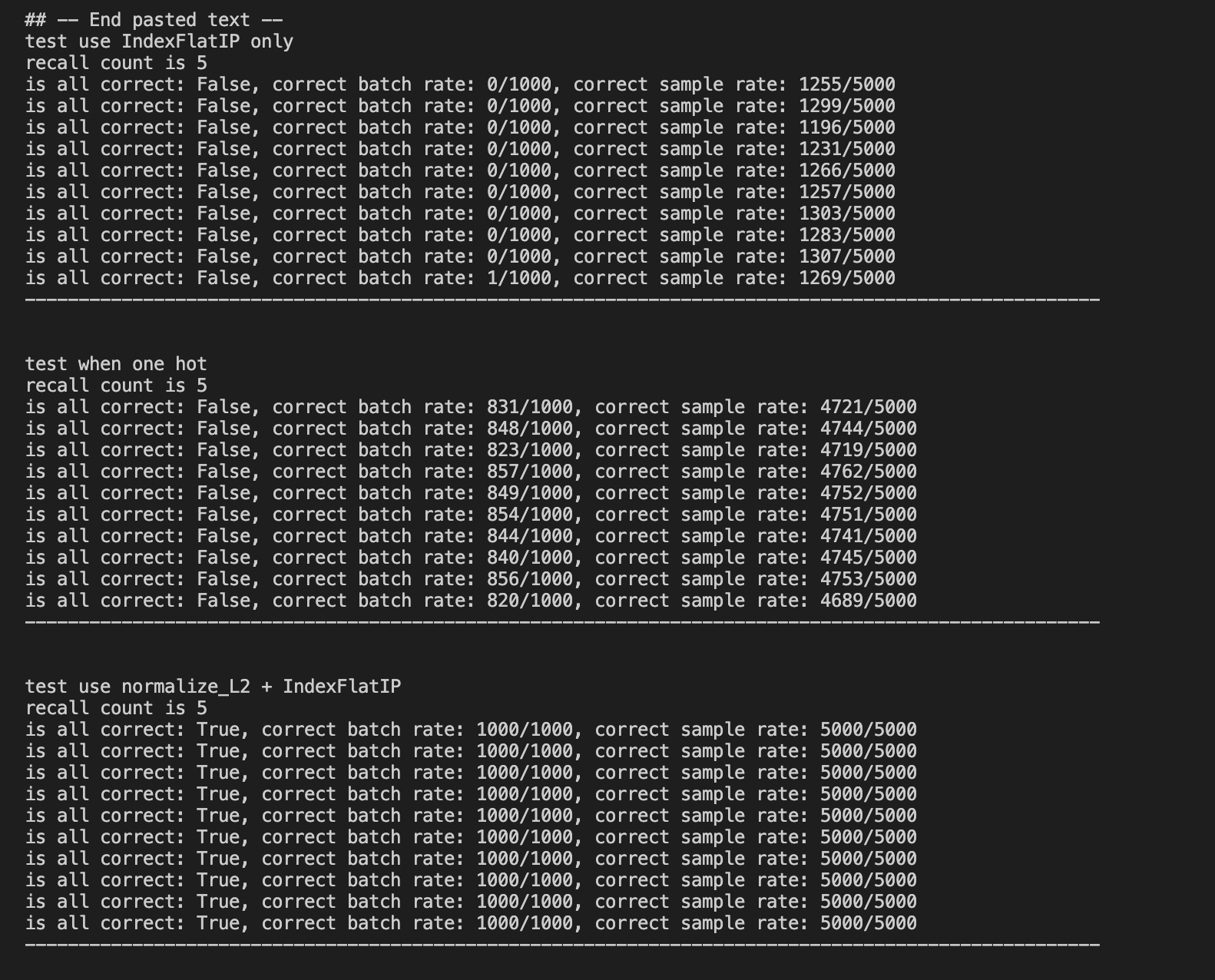
分析:第一份结果(横线隔开),是仅用IndexFlatIP的时候,跟余弦距离的结果相差非常大
第二份结果,是当数据是 one hot 的时候,用 normalize_L2 + IndexFlatIP,faiss和sklearn召回不完全一样是因为余弦相似度相同的时候召回id排序不同而已
第二份结果,是当数据是 embedding 的向量的时候,用 normalize_L2 + IndexFlatIP,faiss和sklearn召回一般都会全部对得上,因为相同距离的情况很少会出现
