【本周主题】第二期:浏览器组成及工作原理深度了解
一、浏览器的大致组成:
2018-11-27 19:48:32 周二(补)
1. 用户界面
包括地址栏、后退/前进按钮、书签目录等,也就是你所看到的除了用来显示你所请求页面的主窗口之外的其他部分
2. 浏览器引擎
用来查询及操作渲染引擎的接口
3. 渲染引擎
用来显示请求的内容,例如,如果请求内容为html,它负责解析html及css,并将解析后的结果显示出来
4. 网络
用来完成网络调用,例如http请求,它具有平台无关的接口,可以在不同平台上工作
5. UI 后端
用来绘制类似组合选择框及对话框等基本组件,具有不特定于某个平台的通用接口,底层使用操作系统的用户接口
6. JS解释器
用来解释执行JS代码
7. 数据存储
属于持久层,浏览器需要在硬盘中保存类似cookie的各种数据,HTML5定义了web database技术,这是一种轻量级完整的客户端存储技术
二、浏览器内核工作原理/流程、浏览器页面渲染流程
2018-11-27 19:48:38 周二
浏览器的内核:
别名:
排版引擎、页面渲染引擎、解释引擎、模板引擎
英文名:
Layout Engine、 Rendering Engine (解释引擎、渲染引擎、排版引擎)
定义:
内核、负责处理渲染页面、处理css样式、解析js等。
浏览器的核心就是浏览器内核。
内核分为两个部分:
1、渲染引擎
作用是:负责获取网页内容(html、图像)、整理消息、计算网页显示方式、输出到显示器这些工作
渲染引擎内含:
html解释器:将html文本解析成dom树(文档对象模型)
css解释器:为dom对象计算样式信息,为计算机布局提供基础设施
layout布局:在dom建立完毕后,计算出他们的位置大小、布局信息。形成一个内部表示模型。
2、js引擎
由于js引擎越来越独立,所以内核倾向于指的是渲染引擎。
作用是:解析js语言,执行js语言。并通过DOM接口和CSSOM接口修改布局和样式。实现网页的动态交互效果。
不同的浏览器有不同的内核,这就导致了不同的浏览器对同一段代码的解析结果不一致。
浏览器内核有哪些:
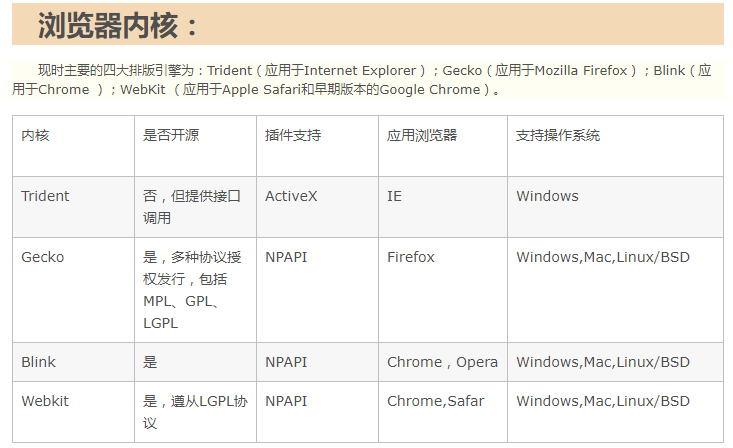
一、Trident内核(IE内核)
代表产品Internet Explorer,又称其为IE内核
Trident(又称为MSHTML),是微软开发的一种排版引擎。使用Trident渲染引擎的浏览器包括:IE、傲游、世界之窗浏览器、Avant、腾讯TT、Netscape 8、NetCaptor、Sleipnir、GOSURF、GreenBrowser和KKman等。 二、Gecko内核(Firefox内核)
代表作品Mozilla FirefoxGecko是一套开放源代码的、以C++编写的网页排版引擎。Gecko是最流行的排版引擎之一,仅次于Trident。使用它的最著名浏览器有Firefox、Netscape6至9。 三、WebKit内核(Safari内核,Chrome内核原型,开源)其实 Chromium 就是 WebKit
代表作品Safari、Chromewebkit 是一个开源项目,包含了来自KDE项目和苹果公司的一些组件,主要用于Mac OS系统,它的特点在于源码结构清晰、渲染速度极快。缺点是对网页代码的兼容性不高,导致一些编写不标准的网页无法正常显示。主要代表作品有Safari和Google的浏览器Chrome。 四、Presto(Opera前内核) (已废弃)
代表作品OperaPresto是由Opera Software开发的浏览器排版引擎,供Opera 7.0及以上使用。它取代了旧版Opera 4至6版本使用的Elektra排版引擎,包括加入动态功能,例如网页或其部分可随着DOM及Script语法的事件而重新排版。
五、Blink(Google的最新内核)
2013年4月3日,谷歌内置Blink渲染引擎(即浏览器核心)于Chrome浏览器之中。Opera表示将会跟随谷歌采用其Blink浏览器核心,同时参与了Blink的开发。
[引] 百度经验:浏览器内核
主要的浏览器内核以及他们的特点
转自:https://blog.csdn.net/liuzijiang1123/article/details/76095986
排版引擎:
WebCore:
苹果公司开发的排版引擎,使用WebCore的主要有Safari
KHTML:
KHTML,是HTML网页排版引擎之一
浏览器内核的作用
浏览器内核的主要作用,是帮助浏览器来渲染网页的内容,负责解析网页语法(如html、javascript),并渲染、展示网页。将页面内容和排版代码转换为用户所见的视图
浏览器内核不同导致的兼容问题及解决方法:
见面试题汇总文章
三、浏览器页面渲染流程
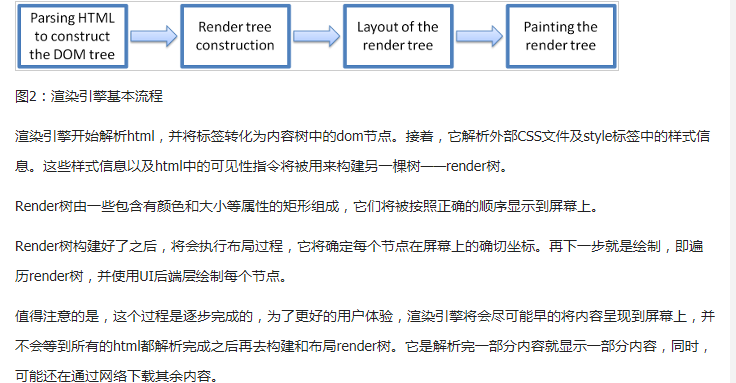
浏览器内核渲染页面的过程
解析html以构建dom树->构建render树->布局render树->绘制render树
转自:浏览器组成及工作原理深度了解
具体总结见《课外主题》http协议及输入URl按下回车后都发生了什么?
以下收集优秀讲解:
转自:https://blog.csdn.net/u010874036/article/details/51123897
浏览器解析页面的过程(浏览器加载和渲染原理分析)
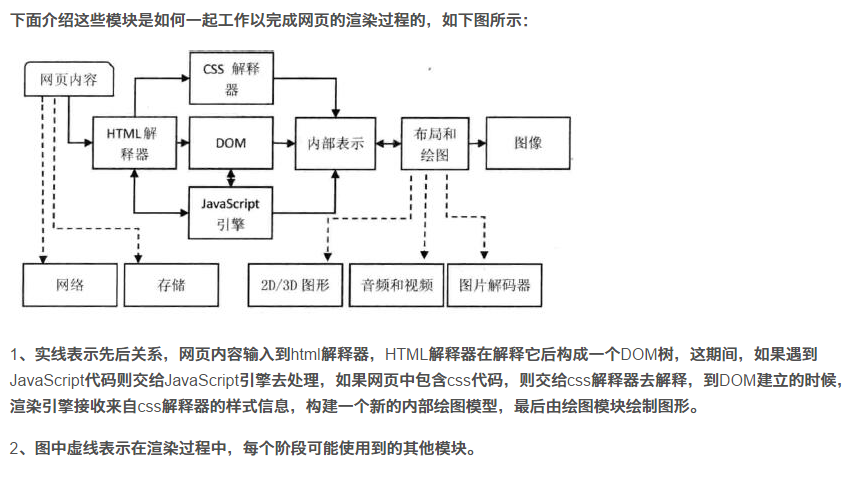
1、下载的顺序是从上到下,渲染的顺序也是从上到下。下载和渲染是同时执行的。
2、在渲染到页面的某一部分时,其上面的所有部分都已经下载完成(并不是说所有相关联的元素都已经下载完)
3、下载过程中,如果遇到内嵌文件、并且文件是具有语义解释性的(就是js脚本、css样式等),那么下载过程会启用单独连接进行下载。并且在下载后进行解析,解析(js、css如有重定义,后定义函数会覆盖前边定义的函数)过程中,停止页面所有往下元素的下载。
4、样式表特殊:下载完后,将和以前下载的所有样式表一起进行解析。解析完成后,将对此前所有元素(含以前已经渲染的)重新进行样式的渲染。并以此方式一直渲染下去,直到整个页面渲染完成。
根据渲染原理、提高网页加载速度的建议:
合并、压缩js、css
减少dns寻址(少请求)
或者将图片分散到不同的域名存储
使用缓存
尽量避免css表达式
图片增加宽度和高度(不然每次要自动计算)
css放在头部、js合理放置(尽量在最后)
工具:
YSlow -
转自:http://www.docin.com/p-201916384.html
回流和重绘
四、javascript引擎
转自:https://blog.csdn.net/liuzijiang1123/article/details/76095986

js引擎的作用:
读取网页中的js代码,并对其处理后运行。
五、浏览器缓存机制
六、浏览器本地存储(cookie,storage)
七、浏览器数据存储(客户端数据库)
八、浏览器兼容写法汇总
(更新中,届时以单独篇幅整理)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号