smooth L1损失函数
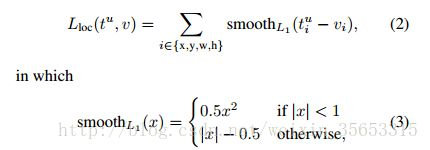
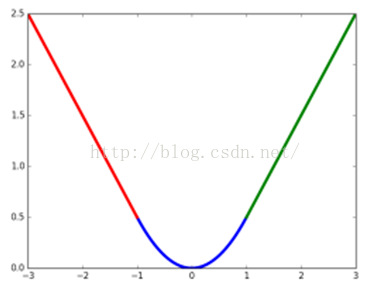
当预测值与目标值相差很大时,L2 Loss的梯度为(x-t),容易产生梯度爆炸,L1 Loss的梯度为常数,通过使用Smooth L1 Loss,在预测值与目标值相差较大时,由L2 Loss转为L1 Loss可以防止梯度爆炸。

L2 loss的导数(梯度)中包含预测值与目标值的差值,当预测值和目标值相差很大,L2就会梯度爆炸。说明L2对异常点更敏感。L1 对噪声更加鲁棒。
当差值太大时, loss在|x|>1的部分采用了 l1 loss,避免梯度爆炸。原先L2梯度里的x−t被替换成了±1, 这样就避免了梯度爆炸, 也就是它更加健壮。
总的来说:相比于L2损失函数,其对离群点、异常值(outlier)不敏感,可控制梯度的量级使训练时不容易跑飞。

