排序
排序是以某种顺序从集合中放置元素的过程。例如,单词列表可以按字母顺序或按长度排序。
1、冒泡排序
冒泡排序需要多次遍历列表。
它比较相邻的项并交换那些无序的项。
每次遍历列表将下一个最大的值放在其正确的位置。实质上,每个项“冒泡”到它所属的位置。
下图展示了冒泡排序的第一次遍历。阴影项正在比较它们是否乱序。如果在列表中有 n 个项目,则第一遍有 n-1 个项需要比较。
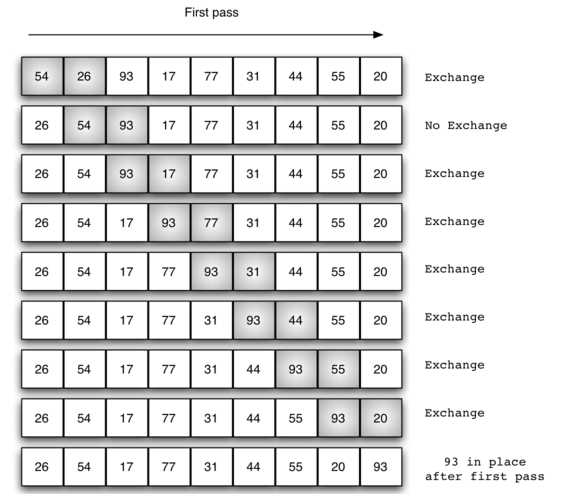
在第二次遍历的开始,现在最大的值已经在正确的位置。有 n-1 个项留下排序,意味着将有 n-2 对。
由于每次通过将下一个最大值放置在适当位置,所需的遍历的总数将是 n-1。
在完成 n-1 遍之后,最小的项肯定在正确的位置,不需要进一步处理。
冒泡排序通常被认为是最低效的排序方法,因为它必须在最终位置被知道之前交换项。
复杂度是O(N^2)。

1 def bubblesort(ls): 2 # 升序排序 3 for i in range(len(ls)-1,0,-1): 4 for i in range(i): 5 if ls[i] > ls[i+1]: 6 ls[i],ls[i+1] = ls[i+1],ls[i] 7 # 降序排序 8 # for i in range(len(ls)-1,0,-1): 9 # for i in range(i): 10 # if ls[i] < ls[i+1]: 11 # ls[i],ls[i+1] = ls[i+1],ls[i] 12 13 alist = [54, 26, 93, 17, 77, 31, 44, 55, 20] 14 bubblesort(alist) 15 print(alist)
短冒泡排序
特别地,如果在遍历期间没有交换,则我们知道该列表已排序。 如果发现列表已排序,可以修改冒泡排序提前停止。
这意味着对于只需要遍历几次列表,冒泡排序具有识别排序列表和停止的优点。
1 def shortBubbleSort(alist): 2 exchanges = True 3 passnum = len(alist)-1 4 while passnum > 0 and exchanges: 5 exchanges = False 6 for i in range(passnum): 7 if alist[i]>alist[i+1]: 8 exchanges = True 9 temp = alist[i] 10 alist[i] = alist[i+1] 11 alist[i+1] = temp 12 passnum = passnum-1 13 14 alist=[20,30,40,90,50,60,70,80,100,110] 15 shortBubbleSort(alist) 16 print(alist)
2、选择排序
选择排序改进了冒泡排序,每次遍历列表只做一次交换。
选择排序在他遍历时寻找最大的值,并在完成遍历后,将其放置在正确的位置。
与冒泡排序一样,在第一次遍历后,最大的项在正确的地方。 第二遍后,下一个最大的就位。遍历 n-1 次排序 n 个项,因为最终项必须在第(n-1)次遍历之后。

def selectionSort(ls): # 开始遍历列表所有索引0-8,列表长度为9 # 列表索引从8,7,6,5,4,3,2,1 for i in range(len(ls)-1,0,-1): # 其实索引从0开始 position_of_max = 0 # i=8: j=1,2,3,4,5,6,7 # i=7: j=1,2,3,4,5,6 for j in range(1,i+1): # 如果j索引位置的值大于当前索引位置的值, # 那么就将最大值索引改为这个索引 if ls[j] > ls[position_of_max]: position_of_max = j # 此时,找到了最大值对应的索引,找到之后,交换一下 ls[j],ls[position_of_max] = ls[position_of_max],ls[j] alist = [54,26,93,17,77,31,44,55,20] selectionSort(alist) print(alist)
选择排序与冒泡排序有相同数量的比较,因此也是 O(n^2)。 然而,由于交换数量的减少,选择排序通常在基准研究中执行得更快。 事实上,对于我们的列表,冒泡排序有 20 次交换,而选择排序只有 8 次。
3、插入排序
仍然是 O(n^2)。
它始终在列表的较低位置维护一个排序的子列表。然后将每个新项 “插入” 回先前的子列表,使得排序的子列表称为较大的一个项。
下图展示了插入排序过程。阴影项表示算法进行每次遍历时的有序子列表。

我们开始假设有一个项(位置 0 )的列表已经被排序。在每次遍历时,对于每个项 1至 n-1,将针对已经排序的子列表中的项检查当前项。当我们回顾已经排序的子列表时,我们将那些更大的项移动到右边。 当我们到达较小的项或子列表的末尾时,可以插入当前项。
下图是第五次遍历的图:
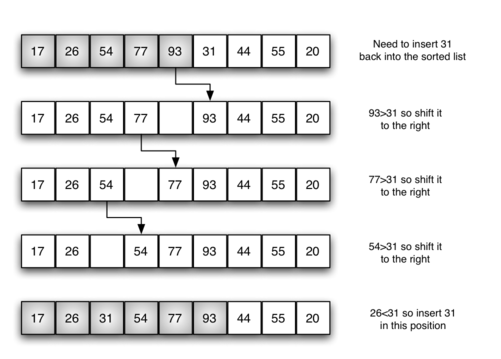
存在 n-1 个遍历以对 n 个排序。从位置1开始迭代并移动位置到n-1,因为这些是需要插回到排序子列表中的项。
移位操作中,将值向上移动到列表中的一个位置,在其后面插入。注意,这不是以前算法中的完全交换。
从位置 1 开始迭代并移动位置到 n-1,因为这些是需要插回到排序子列表中的项。第 8 行执行移位操作,将值向上移动到列表中的一个位置,在其后插入。请记住,这不是像以前的算法中的完全交换。
插入排序的最大比较次数是 n-1 个整数的总和。同样,是 O(n^2)。然而,在最好的情况下,每次通过只需要进行一次比较。这是已经排序的列表的情况。
关于移位和交换的一个注意事项也很重要。通常,移位操作只需要交换大约三分之一的处理工作,因为仅执行一次分配。
在基准研究中,插入排序有非常好的性能。
1 def insertsort(ls): 2 # i从1开始是因为i也是要进行比较的值得索引position, 3 # 要与前面的有序小列表进行比较 4 for i in range(1,len(ls)): 5 # 索引1位置的值给currentvalue变量 6 currentvalue = ls[i] 7 # 当前索引, 8 position = i 9 # positon索引的值和前面的小列表中的每个元素进行比较, 10 # 将position位置的值 与 前面的小列表的所有值从后往前,迭代进行比较,知道找到合适的位置 11 while position > 0 and ls[position-1] > currentvalue: 12 ls[position] = ls[position-1] 13 position = position-1 14 ls[position] = currentvalue 15 alist = [54,26,93,17,77,31,44,55,20] 16 insertsort(alist) 17 print(alist)
4、希尔排序
希尔排序(有时称为“递减递增排序”)通过将原始列表分解为多个较小的子列表来改进插入排序。
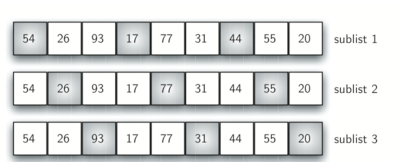
选择这些子列表的方式是希尔排序的关键。不是将列表拆分为连续项的子列表,希尔排序使用增量i(有时称为 gap),通过选择 i 个项的所有项来创建子列表。
下面列表有九个项。如果我们使用三的增量,有三个子列表,每个子列表可以通过插入排序进行排序。
完成这些排序后,我们得到下图列表。虽然这个列表没有完全排序,但发生了很有趣的事情。 通过排序子列表,我们已将项目移动到更接近他们实际所属的位置。
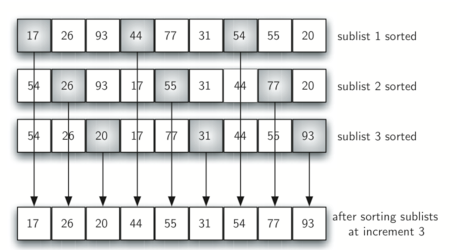
使用增量为 1 的插入排序; 换句话说也就是标准插入排序。
我们之前说过,增量的选择方式是希尔排序的独特特征。 ActiveCode 1中展示的函数使用不同的增量集。在这种情况下,我们从 n/2 子列表开始。下一次,n/4 子列表排序。 最后,单个列表按照基本插入排序进行排序。 Figure 9 展示了我们使用此增量的示例的第一个子列表。
1 def shell_sort(list): 2 n = len(list) 3 4 #初始步长 5 gap = n//2 6 while gap > 0: 7 #按照初始步长进行直接插入排序 8 for j in range(gap,n): 9 i = j 10 #插入排序 11 while i >= gap and list[i-gap] > list[i]: 12 list[i-gap],list[i] = list[i],list[i-gap] 13 i -= gap 14 15 #得到新的步长 16 gap = gap//2
乍一看,你可能认为希尔排序不会比插入排序更好,因为它最后一步执行了完整的插入排序。 然而,结果是,该最终插入排序不需要进行非常多的比较(或移位),因为如上所述,该列表已经被较早的增量插入排序预排序。 换句话说,每个遍历产生比前一个“更有序”的列表。 这使得最终遍历非常有效。
虽然对希尔排序的一般分析远远超出了本文的范围,我们可以说,它倾向于落在 $$O(n)$$ 和 $$O(n^2)$$ 之间的某处,基于以上所描述的行为。对于 Listing 5中显示的增量,性能为 $$O(n^2)$$ 。 通过改变增量,例如使用2^k -1(1,3,7,15,31等等),希尔排序可以在 $$O(n^{\frac{3}{2}})$$处执行。
5、归并排序
使用分而治之策略作为提高排序算法性能的一种方法。

1 """ 2 归并排序 3 最优时间复杂度:O(nlogn) 4 最坏 :O(nlogn) 5 稳定性:稳定 6 7 与其他排序的区别:利用一个新列表将算法排序后的元素存储当中,空间换时间 8 """ 9 10 import time 11 import random 12 13 def merge_sort(list): 14 """归并排序""" 15 n = len(list) 16 if n <= 1: 17 return list 18 19 #最大整数 20 mid = n//2 21 #left 利用递归 截取的列表形成的有序列表 22 left_list = merge_sort(list[:mid]) 23 #right利用递归截取的列表形成的有序列表 24 right_list = merge_sort(list[mid:]) 25 #创建左右标记记录列表值的索引 26 left_pointer, right_pointer = 0,0 27 #创建新空列表 28 result = [] 29 #循环 比较数值大小 30 #退出循环条件:当左右游标其中一个等于所在列表的长度时 31 while left_pointer < len(left_list) and right_pointer < len(right_list): 32 #判断左值和右值大小 33 if left_list[left_pointer] <= right_list[right_pointer]: 34 result.append(left_list[left_pointer]) 35 #每判断一次 游标加一 36 left_pointer +=1 37 else: 38 result.append(right_list[right_pointer]) 39 right_pointer +=1 40 41 #将最后一个数值加入到新列表中 42 result += left_list[left_pointer:] 43 result += right_list[right_pointer:] 44 #返回值 45 return result 46 47 def new_num(lis): 48 for i in range(50): 49 j = random.randint(1,100) 50 lis.append(j) 51 52 if __name__=='__main__': 53 first_time = time.time() 54 #空列表 55 lis = [] 56 57 #生成列表 58 new_num(lis) 59 print(lis) 60 61 #进行列表排序 62 print(merge_sort(lis)) 63 64 #结束时间 65 last_time = time.time() 66 67 print('time = : {}'.format(last_time- first_time))
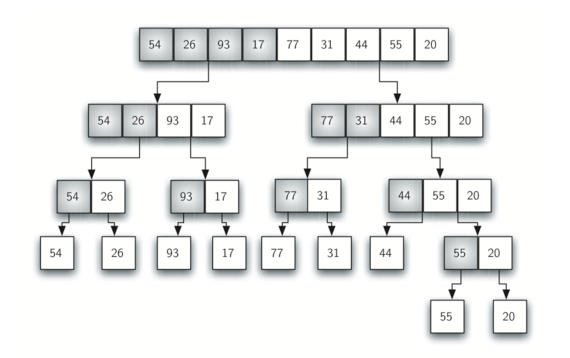
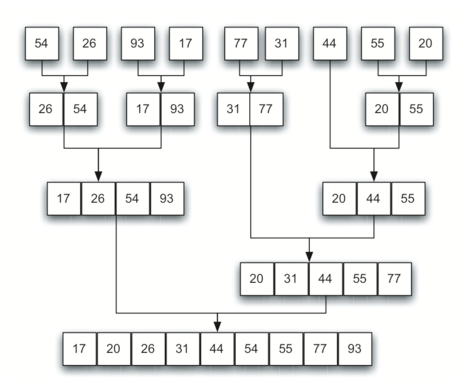
为了分析 mergeSort 函数,我们需要考虑组成其实现的两个不同的过程。
首先,列表被分成两半。我们已经计算过(在二分查找中)将列表划分为一半需要 log^n 次,其中 n 是列表的长度。
第二个过程是合并。列表中的每个项将最终被处理并放置在排序的列表上。因此,大小为 n 的列表的合并操作需要 n 个操作。此分析的结果是 logn的拆分,其中每个操作花费 n,总共 nlogn 。
归并排序是一种 O(nlogn) 算法。
重要的是注意,mergeSort 函数需要额外的空间来保存两个半部分,因为它们是使用切片操作提取的。如果列表很大,这个额外的空间可能是一个关键因素,并且在处理大型数据集时可能会导致此类问题。
6、快速排序
快速排序使用分而治之来获得与归并排序相同的优点,而不使用额外的存储。然而,作为权衡,有可能列表不能被分成两半。当这种情况发生时,我们将看到性能降低。
快速排序首先选择一个值,该值称为 枢轴值。分区从通过在列表中剩余项目的开始和结束处定位两个位置标记(我们称为左标记和右标记)开始。分区的目标是移动相对于枢轴值位于错误侧的项,同时也收敛于分裂点。 下图展示了我们定位54的位置的过程。
过程:
选第一个值54作为枢轴值,左游标从26开始,找到大于54的值停下,右游标从列表尾开始,找到第一个小于54的停下,然后交换这两个值。一直进行下去,知道左右游标相邻,然后将枢轴值放到这两个游标索引的中间。

1 """ 2 快速排序 3 最优时间复杂度:O(nlogn) 4 最坏时间复杂度:O(n2) 5 稳定性:不稳定 6 7 """ 8 import time 9 import random 10 11 12 def quick_sort(list, star, end): 13 # 递归的退出条件 14 if star >= end: 15 return 16 17 # low为序列左边的由左向右移动的游标 18 low = star 19 20 # high 为序列右边的由右向左移动的游标 21 high = end 22 23 # 设定其实元素为要寻找位置的基准元素 24 mid_value = list[star] 25 26 while low < high: 27 # 如果low 与high 未重合,high 指向的元素比基准元素大,则high向左移 28 # 直到找到右游标小于minvalue的值,进行下一步 29 while low < high and list[high] >= mid_value: 30 high -= 1 31 32 # 将high 指向的元素放到low 的位置上 33 # 不用担心list[low]原来的值的会消失,因为之前已经将mid_value = list[star],这里的star=low 34 list[low] = list[high] 35 36 # 如果low与high未重合,low指向的元素比基准元素小,low的向右移 37 # 直到左游标找到比midvalue大的值 38 while high > low and list[low] < mid_value: 39 low += 1 40 41 # 将low指向的元素放到high的位置上 42 list[high] = list[low] 43 44 # 退出循环后,low 与high重合,此时所指位置为基准元素的正确位置 45 # 循环退出时 将基准元素放到该位置 46 list[low] = mid_value 47 48 # 对基准元素的左边的子序列进行快速排序 49 quick_sort(list, star, low-1) 50 51 # 对基准元素右边的子序列进行快速排序 52 quick_sort(list, low+1, end) 53 54 55 def new_num(lis): 56 """随机生成50个数加入列表中""" 57 for i in range(50): 58 j = random.randint(0,10000) 59 lis.append(j) 60 61 62 if __name__ == '__main__': 63 64 first_time = time.time() 65 # 空列表 66 lis = [] 67 68 # 随机函数添加到列表中 69 new_num(lis) 70 71 # 列表排序 72 quick_sort(lis, 0, len(lis)-1) 73 74 print(lis) 75 76 # 结束时间 77 last_time = time.time() 78 79 print("共用时%s" % (last_time - first_time))

