SSD-tensorflow-3 重新训练模型(vgg16)
一、修改pascalvoc_2007.py
生成自己的tfrecord文件后,修改训练数据shape——打开datasets文件夹中的pascalvoc_2007.py文件,
根据自己训练数据修改:NUM_CLASSES = 类别数(不包含背景);
# TRAIN_STATISTICS = { # 'none': (0, 0), # 'aeroplane': (238, 306), # 'bicycle': (243, 353), # 'bird': (330, 486), # 'boat': (181, 290), # 'bottle': (244, 505), # 'bus': (186, 229), # 'car': (713, 1250), # 'cat': (337, 376), # 'chair': (445, 798), # 'cow': (141, 259), # 'diningtable': (200, 215), # 'dog': (421, 510), # 'horse': (287, 362), # 'motorbike': (245, 339), # 'person': (2008, 4690), # 'pottedplant': (245, 514), # 'sheep': (96, 257), # 'sofa': (229, 248), # 'train': (261, 297), # 'tvmonitor': (256, 324), # 'total': (5011, 12608), # } # TEST_STATISTICS = { # 'none': (0, 0), # 'aeroplane': (1, 1), # 'bicycle': (1, 1), # 'bird': (1, 1), # 'boat': (1, 1), # 'bottle': (1, 1), # 'bus': (1, 1), # 'car': (1, 1), # 'cat': (1, 1), # 'chair': (1, 1), # 'cow': (1, 1), # 'diningtable': (1, 1), # 'dog': (1, 1), # 'horse': (1, 1), # 'motorbike': (1, 1), # 'person': (1, 1), # 'pottedplant': (1, 1), # 'sheep': (1, 1), # 'sofa': (1, 1), # 'train': (1, 1), # 'tvmonitor': (1, 1), # 'total': (20, 20), # } # SPLITS_TO_SIZES = { # 'train': 5011, # 'test': 4952, # } # SPLITS_TO_STATISTICS = { # 'train': TRAIN_STATISTICS, # 'test': TEST_STATISTICS, # } # NUM_CLASSES = 20 TRAIN_STATISTICS = { 'none': (0, 0), 'flower': (35,35), 'total': (35, 35), } TEST_STATISTICS = { 'none': (0, 0), 'flower': (15,15) } SPLITS_TO_SIZES = { 'train': 35, 'test': 15 } SPLITS_TO_STATISTICS = { 'train': TRAIN_STATISTICS, 'test': TEST_STATISTICS, } NUM_CLASSES = 1 #类别,不包含背景
二、修改ssd_vgg_300.py
根据自己训练类别数修改96 和97行:等于类别数+1
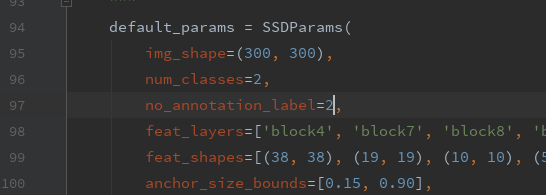
三、修改eval_ssd_network.py
修改类别数和batchsize

四、修改train_ssd_network.py
数据格式改为 NHWC:

numclasses改为类别数加1:

batch_size该为自己设置的:

修改训练步数(None代表无限训练下去):

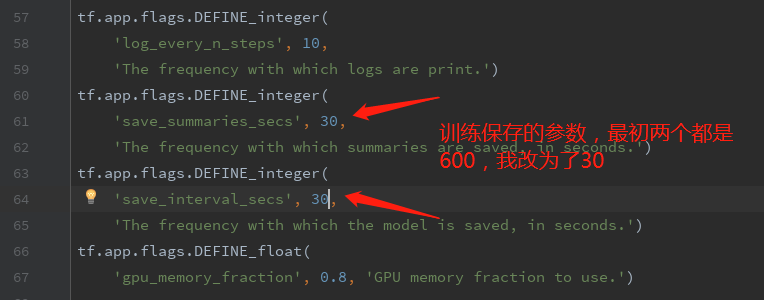
可以更改模型保存的参数:
五:加载VGG_16,重新训练模型
将VGG_16放在checkpoint文件夹下面:

从VGG16开始训练其中某些层的参数
1 # 通过加载预训练好的vgg16模型,对“voc07trainval+voc2012”进行训练 2 # 通过checkpoint_exclude_scopes指定哪些层的参数不需要从vgg16模型里面加载进来 3 # 通过trainable_scopes指定哪些层的参数是需要训练的,未指定的参数保持不变,若注释掉此命令,所有的参数均需要训练 4 DATASET_DIR=/home/doctorimage/kindlehe/common/dataset/VOC0712/ 5 TRAIN_DIR=.././log_files/log_finetune/train_voc0712_20170816_1654_VGG16/ 6 CHECKPOINT_PATH=../checkpoints/vgg_16.ckpt 7 8 python3 ../train_ssd_network.py \ 9 --train_dir=${TRAIN_DIR} \ #训练生成模型的存放路径 10 --dataset_dir=${DATASET_DIR} \ #数据存放路径 11 --dataset_name=pascalvoc_2007 \ #数据名的前缀 12 --dataset_split_name=train \ 13 --model_name=ssd_300_vgg \ #加载的模型的名字 14 --checkpoint_path=${CHECKPOINT_PATH} \ #所加载模型的路径 15 --checkpoint_model_scope=vgg_16 \ #所加载模型里面的作用域名 16 --checkpoint_exclude_scopes=ssd_300_vgg/conv6,ssd_300_vgg/conv7,ssd_300_vgg/block8,ssd_300_vgg/block9,ssd_300_vgg/block10,ssd_300_vgg/block11,ssd_300_vgg/block4_box,ssd_300_vgg/block7_box,ssd_300_vgg/block8_box,ssd_300_vgg/block9_box,ssd_300_vgg/block10_box,ssd_300_vgg/block11_box \ 17 --trainable_scopes=ssd_300_vgg/conv6,ssd_300_vgg/conv7,ssd_300_vgg/block8,ssd_300_vgg/block9,ssd_300_vgg/block10,ssd_300_vgg/block11,ssd_300_vgg/block4_box,ssd_300_vgg/block7_box,ssd_300_vgg/block8_box,ssd_300_vgg/block9_box,ssd_300_vgg/block10_box,ssd_300_vgg/block11_box \ 18 --save_summaries_secs=60 \ #每60s保存一下日志 19 --save_interval_secs=600 \ #每600s保存一下模型 20 --weight_decay=0.0005 \ #正则化的权值衰减的系数 21 --optimizer=adam \ #选取的最优化函数 22 --learning_rate=0.001 \ #学习率 23 --learning_rate_decay_factor=0.94 \ #学习率的衰减因子 24 --batch_size=24 \ 25 --gpu_memory_fraction=0.9 #指定占用gpu内存的百分比
接下来可以进行fine-tunning
1 (当你的模型通过vgg训练的模型收敛到大概o.5mAP的时候,可以进行这一步的fine-tune) 2 3 4 # 通过加载预训练好的vgg16模型,对“voc07trainval+voc2012”进行训练 5 # 通过checkpoint_exclude_scopes指定哪些层的参数不需要从vgg16模型里面加载进来 6 # 通过trainable_scopes指定哪些层的参数是需要训练的,未指定的参数保持不变 7 DATASET_DIR=/home/doctorimage/kindlehe/common/dataset/VOC0712/ 8 TRAIN_DIR=.././log_files/log_finetune/train_voc0712_20170816_1654_VGG16/ 9 CHECKPOINT_PATH=./log_files/log_finetune/train_voc0712_20170712_1741_VGG16/model.ckpt-253287 10 11 python3 ../train_ssd_network.py \ 12 --train_dir=${TRAIN_DIR} \ #训练生成模型的存放路径 13 --dataset_dir=${DATASET_DIR} \ #数据存放路径 14 --dataset_name=pascalvoc_2007 \ #数据名的前缀 15 --dataset_split_name=train \ 16 --model_name=ssd_300_vgg \ #加载的模型的名字 17 --checkpoint_path=${CHECKPOINT_PATH} \ #所加载模型的路径 18 --checkpoint_model_scope=vgg_16 \ #所加载模型里面的作用域名 19 --checkpoint_exclude_scopes=ssd_300_vgg/conv6,ssd_300_vgg/conv7,ssd_300_vgg/block8,ssd_300_vgg/block9,ssd_300_vgg/block10,ssd_300_vgg/block11,ssd_300_vgg/block4_box,ssd_300_vgg/block7_box,ssd_300_vgg/block8_box,ssd_300_vgg/block9_box,ssd_300_vgg/block10_box,ssd_300_vgg/block11_box \ 20 --trainable_scopes=ssd_300_vgg/conv6,ssd_300_vgg/conv7,ssd_300_vgg/block8,ssd_300_vgg/block9,ssd_300_vgg/block10,ssd_300_vgg/block11,ssd_300_vgg/block4_box,ssd_300_vgg/block7_box,ssd_300_vgg/block8_box,ssd_300_vgg/block9_box,ssd_300_vgg/block10_box,ssd_300_vgg/block11_box \ 21 --save_summaries_secs=60 \ #每60s保存一下日志 22 --save_interval_secs=600 \ #每600s保存一下模型 23 --weight_decay=0.0005 \ #正则化的权值衰减的系数 24 --optimizer=adam \ #选取的最优化函数 25 --learning_rate=0.001 \ #学习率 26 --learning_rate_decay_factor=0.94 \ #学习率的衰减因子 27 --batch_size=24 \ 28 --gpu_memory_fraction=0.9 #指定占用gpu内存的百分比
补充:还可以拿来训练vgg512
从自己训练的ssd_300_vgg模型开始训练ssd_512_vgg的模型。
因此ssd_300_vgg中没有block12,又因为block7,block8,block9,block10,block11,中的参数张量两个网络模型中不匹配,因此ssd_512_vgg中这几个模块的参数不从ssd_300_vgg模型中继承,因此使用checkpoint_exclude_scopes命令指出。
因为所有的参数均需要训练,因此不使用命令--trainable_scopes。
1 1 #/bin/bash 2 2 DATASET_DIR=/home/data/xxx/imagedata/xing_tf/train_tf/ 3 3 TRAIN_DIR=/home/data/xxx/model/xing300512_model/ 4 4 CHECKPOINT_PATH=/home/data/xxx/model/xing300_model/model.ckpt-60000 #加载的ssd_300_vgg模型 5 5 python3 ./train_ssd_network.py \ 6 6 --train_dir=${TRAIN_DIR} \ 7 7 --dataset_dir=${DATASET_DIR} \ 8 8 --dataset_name=pascalvoc_2007 \ 9 9 --dataset_split_name=train \ 10 10 --model_name=ssd_512_vgg \ 11 11 --checkpoint_path=${CHECKPOINT_PATH} \ 12 12 --checkpoint_model_scope=ssd_300_vgg \ 13 13 --checkpoint_exclude_scopes=ssd_512_vgg/block7,ssd_512_vgg/block7_box,ssd_512_vgg/block8,ssd_512_vgg/block8_box, ssd_512_vgg/block9,ssd_512_vgg/block9_box,ssd_512_vgg/block10,ssd_512_vgg/block10_box,ssd_512_vgg/block11,ssd_512_vgg/b lock11_box,ssd_512_vgg/block12,ssd_512_vgg/block12_box \ 14 14 #--trainable_scopes=ssd_300_vgg/conv6,ssd_300_vgg/conv7,ssd_300_vgg/block8,ssd_300_vgg/block9,ssd_300_vgg/block1 0,ssd_300_vgg/block11,ssd_300_vgg/block4_box,ssd_300_vgg/block7_box,ssd_300_vgg/block8_box,ssd_300_vgg/block9_box,ssd_3 00_vgg/block10_box,ssd_300_vgg/block11_box \ 15 15 --save_summaries_secs=28800 \ 16 16 --save_interval_secs=28800 \ 17 17 --weight_decay=0.0005 \ 18 18 --optimizer=adam \ 19 19 --learning_rate_decay_factor=0.94 \ 20 20 --batch_size=16 \ 21 21 --num_classes=4 \ 22 22 -gpu_memory_fraction=0.8 \ 23 23
六、全部从头开始训练自己的模型
1 # 注释掉CHECKPOINT_PATH,不提供初始化模型,让模型自己随机初始化权重,从头训练 2 # 删除checkpoint_exclude_scopes和trainable_scopes,因为是从头开始训练 3 # CHECKPOINT_PATH=./log_files/log_finetune/train_voc0712_20170712_1741_VGG16/model.ckpt-253287 4 5 python3 ../train_ssd_network.py \ 6 --train_dir=${TRAIN_DIR} \ #训练生成模型的存放路径 7 --dataset_dir=${DATASET_DIR} \ #数据存放路径 8 --dataset_name=pascalvoc_2007 \ #数据名的前缀 9 --dataset_split_name=train \ 10 --model_name=ssd_300_vgg \ #加载的模型的名字 11 #--checkpoint_path=${CHECKPOINT_PATH} \ #所加载模型的路径,这里注释掉 12 #--checkpoint_model_scope=vgg_16 \ #所加载模型里面的作用域名 13 --save_summaries_secs=60 \ #每60s保存一下日志 14 --save_interval_secs=600 \ #每600s保存一下模型 15 --weight_decay=0.0005 \ #正则化的权值衰减的系数 16 --optimizer=adam \ #选取的最优化函数 17 --learning_rate=0.00001 \ #学习率 18 --learning_rate_decay_factor=0.94 \ #学习率的衰减因子 19 --batch_size=32

