

Jmeter学习笔记(十五)——常用的4种参数化方式
一、Jmeter参数化概念
当使用JMeter进行测试时,测试数据的准备是一项重要的工作。若要求每次迭代的数据不一样时,则需进行参数化,然后从参数化的文件中来读取测试数据。
参数化是自动化测试脚本的一种常用技巧。简单来说,参数化的一般用法就是将脚本中的某些输入使用参数来代替,在脚本运行时指定参数的取值范围和规则;
这样,脚本在运行时就可以根据需要选取不同的参数值作为输入。这种方式通常被称为数据驱动测试(Data Driven Test),参数的取值范围被称为数据池(Data Pool)
二、JMeter参数化方式之使用场景对比
| 参数化方式 | 使用场景 | |
|---|---|---|
| User Parameters(用户参数) | 适用于参数取值范围很小的时候使用 | |
| CSV Data Set Config(CSV数据控件) | 适用于参数取值范围较大的时候使用,该方法具有更大的灵活性 | |
| User Defined Variables(用户自定义变量) | 一般用于Test Plan中不需要随请求迭代的参数设置,如:Host、Port Number | |
| Function Helper(函数助手) | 可作为其他参数化方式的补充项,如:随机数生成的函数${__Random(,,)} |
三、各种方式演示
1、User Parameters(用户参数)
(1)在线程组下面添加用户参数
添加->前置处理器->用户参数,并且设置参数项和参数值

(2)添加http请求
请求参数的值使用用户参数

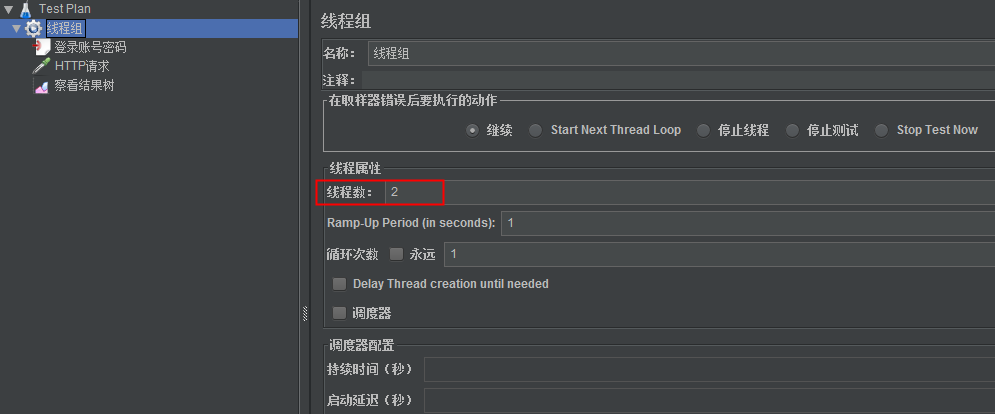
(3)设置线程数
设置线程数=2,即2个虚拟用户数,对应User Parameters中设置的2个用户
注意这里只能设置线程数2,如果是循环次数设置为2,那么指的是拿用户1循环。
(4)执行结果
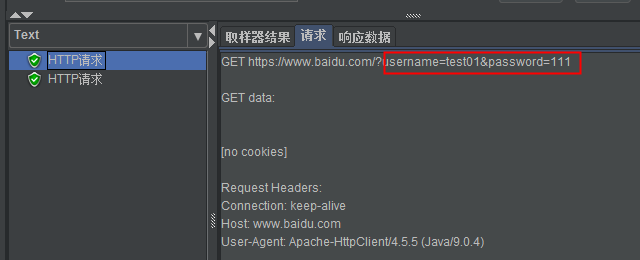
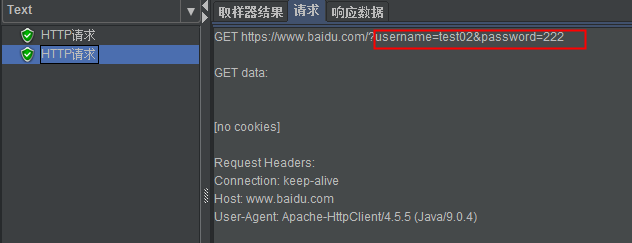
2、CSV Data Set Config(CSV数据控件)
(1)新建数据文件
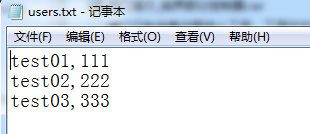
(2)在http请求上添加CSV Data Set Config
添加->配置元件->CVS数据文件设置,设置文件存在路径、文件编码、变量名称
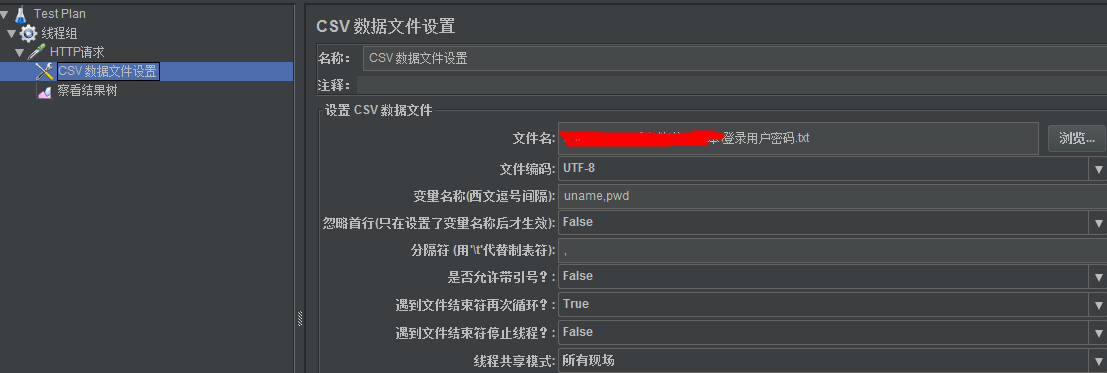
Configure the CSV Data Source配置项&功能:
| 配置项 | 取值or选择项 |
|---|---|
| Filename(文件名) | 参数化文件的读取位置,即保存参数化数据的文件目录。可为绝对路径,也可为相对路径。在分布式测试中,还是利用相对路径比较方便,因为有的机器可能安装路径不一样,同时可避免脚本迁移时需要修改路径 |
| File Encoding(文件编码) | 编码格式,选择utf-8 |
| Variable Names(变量名称) | 变量名称。这里定义的变量名称,后面就可以直接用来引用了。(多个变量名称以逗号隔开,例如username,passwd。参数化文件中同样有对应的两列数据。) |
| Ignore first line(忽略第一行) | 忽略第一行数据(类似LR中第一行数据是变量名称,如果你的配置文件中为了记忆第一行也是变量名,可以选择是忽略该行数据) |
| Delimiter(分隔符) | Variable Names中的参数分隔符,默认为英文逗号 |
| Allow quoted data?(是否允许带引号) | 是否允许引用数据,默认false。选项为“true”时对全角字符的处理可能会出现乱码 |
| Recycle on EOF?(遇到文件结束符再次循环) | 是否循环读取参数文件内容;因为CSV Data Set Config一次读入一行,分割后存入若干变量中交给一个线程,如果线程数超过文本的记录行数,那么可以选择从头再次读入 |
| Stop thread on EOF?(遇到文件结束符停止线程) | 当Recycle on EOF为False时(读取文件到结尾),停止进程,当Recycle on EOF为True时,此项无意义 |
| Sharing mode(共享模式) | 共享模式,即参数文件的作用域:All Threads;Current Thread Group;Current Thread |
(3)设置http请求的参数
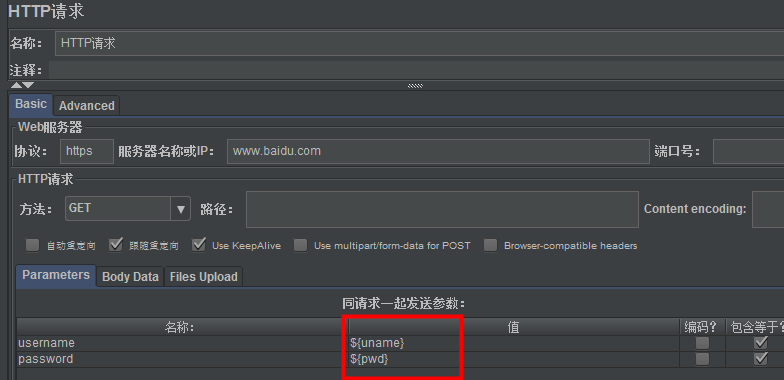
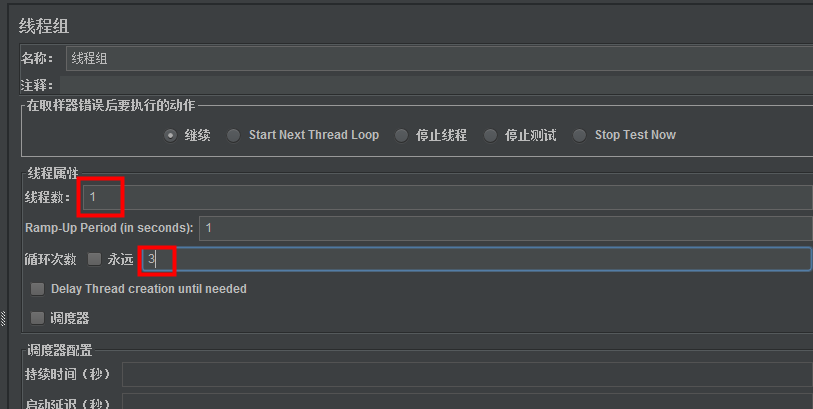
(4)设置线程
设置线程数3或者设置循环次数3都可以
(5)执行结果



3、User Defined Variables(用户自定义变量)
(1)添加用户自定义变量
添加->配置元件->用户定义的变量

(2)http请求的参数设置
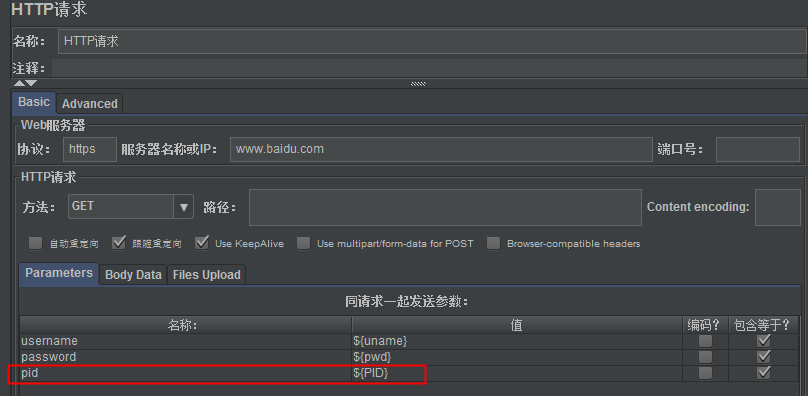
(3)执行结果

4、Function Helper(函数助手)
(1)打开函数助手对话框,选择需要的函数并配置
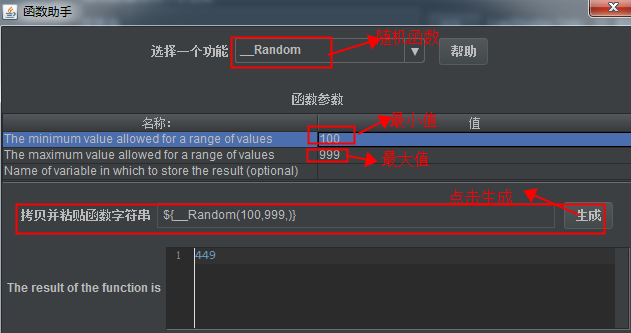
(2)http请求参数设置
复制函数助手生成的函数字符串
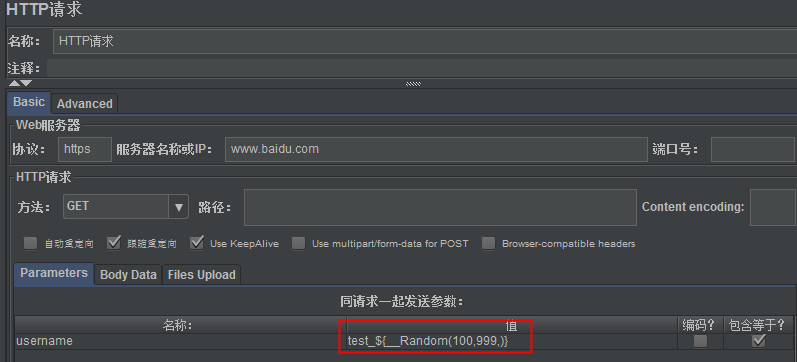
(3)执行结果
每次执行传的参数都不一样


