LIID
文章开头提及一些弱监督实例分割的知识。弱监督的根本原因在于对图像进行逐像素的mask打标签时间开销很大,因此利用弱监督方法为图像生成伪实例标签。其中有一种方法是基于bbox的弱监督方法:因为bbox获取开销要小于mask。而本文用的是一种基于image-level label的方法,基于但不依赖于CAM。这篇文章提出的方法基于“无类别先验的通用基于段建议”SOP,用于获取RP,并提出一种MIL框架,用于对某一个RP同时计算概率分布和类别感知语义特征。RP将被分为两类:对于包含类别的,MIL将学习使该RP对相应的Class的最终分类概率最大;对于有不包含类别的,将会被ignore。从MIL框架中得到的概率分布和语义特征向量,将被用来构成一个知识图谱,最终通过图切的方法获取类别和RP之间的关系。
核心思想
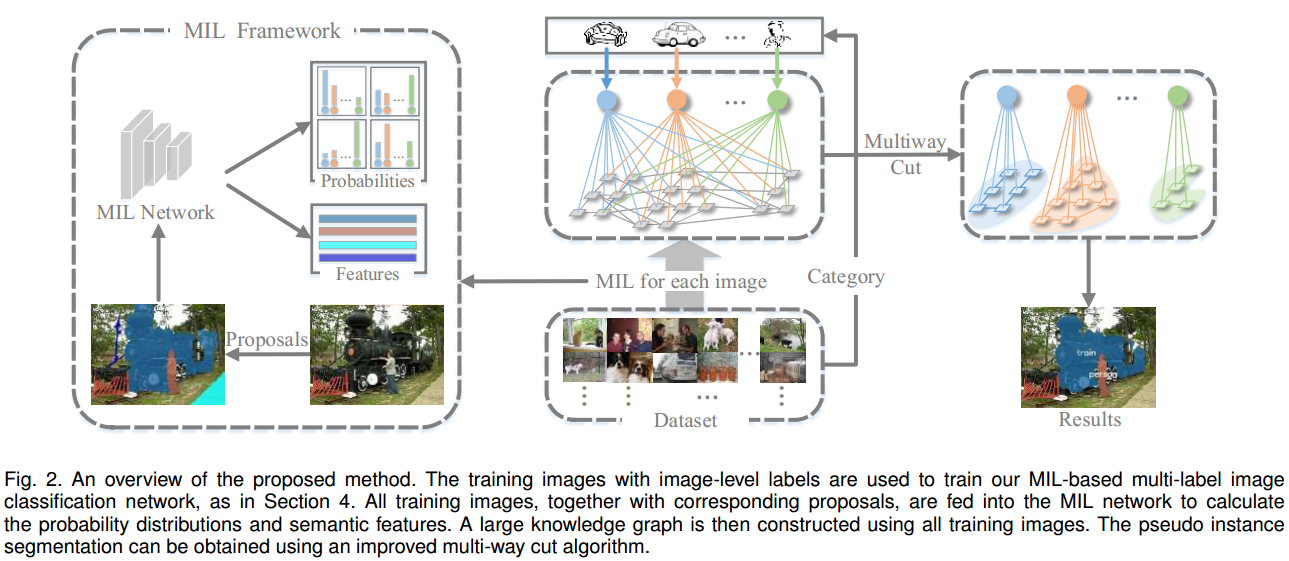
文章的核心思想如图所示。输入一个dataset,其中包括了若干个image。
- 首先将每张图片经过MIL框架:利用SOP方法获得image的RP,再将其放入MIL Network学习,得到不同的RP所对应的类别的概率和类别感知语义特征;
- 之后,用MIL框架中得到的结果构成一个知识图谱,通过Multiway Cut对图谱进行图切,最终得到每一个类别所对应的类别语义特征,并依次决定保留哪些RP作为最终生成的伪实例标签。
1. 多分类网络的架构
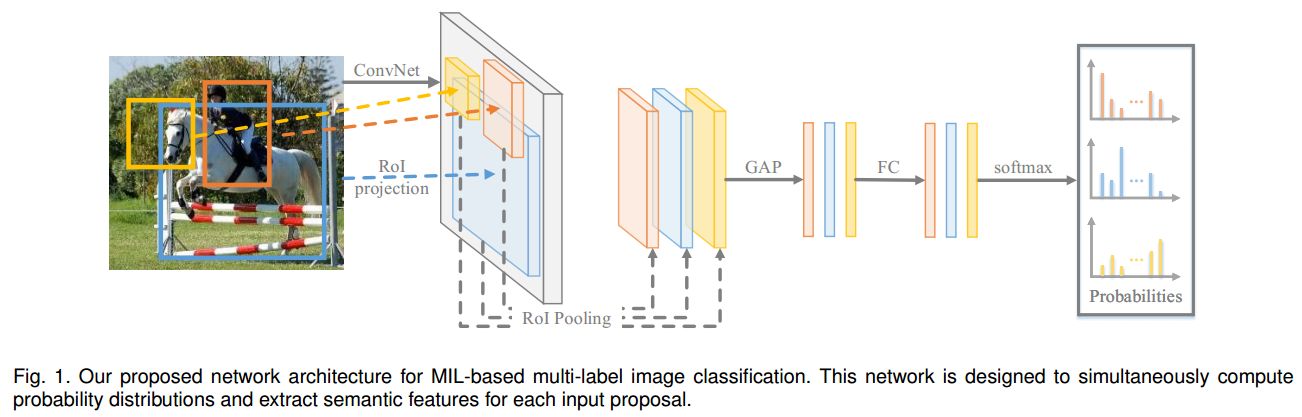
多分类网络的架构比较简单,主要可以分为以下步骤:
- 通过SOP方法(比如selective search,MCG等)获得Region proposal;
- 将RP通过ROI pooling和GAP、FC、softmax,最终输出分类概率。
定义一些变量:
- 表示training image;
- 表示image-level label;
- 表示若干个categories的集合,其中0表示背景类,表示去除背景类之后的categories的集合;
- 表示每张图中对应的SOP产生的RP的集合,其中,其中表示;的数量,即这张图中所有RP的数量。因为RP会提供一个物体所占有的大概区域,所以也可以视为Mask;
- 表示中所对应的bbox,也与之对应。
对于SOP得到的结果,如果不包含语义对象,或者包含多个语义对象,都会被标记为noise;只包含一个语义对线的被认为是合格的。对于上面的变量,可以得到一个函数反应S和K之间的关系,即从RP到类别:
和将会用于产生图像的伪实例标签。
文章使用了一个温和的假设,即每一张图片中都包含背景类。
2. Loss Function
整体的loss主要由三部分构成,分别为CAM-Based Loss,MIL-Based Image Classification Loss和MIL-Based Center Loss。
2.1 CAM-Based Loss
对于一张图像,令其CAM为(这个值会被归一化到0和1之间);对于某一个region proposal ,其在CAM中对应的部分可以表示为。定义一个变量 :
因此取值在上。此时设置一个门槛,则可以通过来生成的伪标签:
分别利用包含与不包含伪标签的部分设置CAM-Based Loss:
其中表示不属于的其他类。
2.2 MIL-Based Image Classification Loss
虽然proposal的ground truth标签是未知的,但是网络得到的概率分布可以表示网络的分类能力。所以虽然没法直接对每个proposal的概率进行监督,但是可以监督每个图像的总体概率聚合。
用表示的中每个类的聚合score。本文并没有用单一的max或average来衡量,而是使用了Log-Sum Exp(LSE)函数来极端:
其中r是一个调制因子,可以控制LSE的值在max和average之间。因此可以分别根据在某一个Image中的present类和absent类来定义损失函数。从直觉上而言,当某个absent类拥有很高的出现概率时,应该给出惩罚,因此MIL-Based Image Classification Loss定义为:
其中,表示的补集,即absent类。
值得注意的是,文章前面提到做出了温和的假设每一张图像都包含有背景类,而在这里作者解释了其必要性:
- 自底向上算法生成的建议会包括一些不属于目标对象类别的噪声建议,因此为了确保网络的训练,需要设置背景类(将这些噪声都归为背景类);
- 网络需要识别和过滤这些噪声,所以这些背景类需要跟随训练,最终利用后面介绍的技术过滤掉。
2.3 MIL-Based Center Loss
对于语义特征相似性,我们希望:同一类别proposal的语义特征相似性最大化,不同类别proposal的语义特征相似性最小化。因此定义:
其中,是第k个类的input sample的learned center,表示L2正则化。这个损失函数衡量了一个特征向量和一个类别中心之间的余弦相似性(cosine similarity)。每一轮训练后,的值会按如下方式更新:
其中是更新率。
(感觉有点像k-means?)
最终的损失函数定义为:
在文章中,作者将三个系数分别设为0.5,0.5和0.1.
3. 标签分配和多路图切
3.1 图切问题简介
假设有一个无向图,令每两个节点v和u之间边权重为,现在要将G分成两个子图G1和G2,且两个子图不通过任何边向量,即相当于对某些边进行切割。最小图切问题(minimum cut problem)是:找到一种切法,使得被切掉的边的集合的weight最小。这个问题可以看做最大流问题(maximum flow problem)的对偶问题,可以在多项式时间(polynomial time)内被解决。
多路图切问题(或者叫“多端图切问题”)则是指:将G分为若干个子图,同样保持被切掉的边的集合的weight最小。这个问题是一个NP-hard问题,本文解决该问题的方法在下面介绍。
3.2 本文知识图谱结构
经过前面的过程,现在得到了K个类别和一些生成的mask,即其中。现在需要将类别和mask之间配对,配对方法如下:
画一个无向图,其中,即将每一个和每一个都作为知识图谱的节点。这些节点之间两两连接一条边,每条边的weight设置如下所示:
对于上式,可以理解为三种情况:
- 两个类别节点之间的权重是0;
- 类别节点和proposal节点之间的权重是该proposal被归为这个类的概率;
- 两个proposal节点之间的权重是他们的特征向量之间的cosine similarity。
3.3 本文知识图谱的图切方法
当时,可以看做是最简单的最小图切问题;但很多情况下都是多路图切问题。解法如下:
定义表示k-simplex(即k+1个节点做构成的k多面体),因此K维的convex polytope可以表示为,(后面包括公式没看懂,直接放截图吧)

直接计算多路图切问题是非常占用CPU内存的,所以作者使用以下方法来化简计算:先将大图变为稀疏图,具体方法是每个节点只保留其weight最大的3条边,这相当于把图分成了若干个子图;然后,对每一个子图用上面的解法,最终得到多路图切的结果。
本文作者:PaB式乌龙茶
本文链接:https://www.cnblogs.com/pab-oolongtea/p/17999716
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步