YOLOv2
改进点讲解1:https://zhuanlan.zhihu.com/p/71179215
改进点讲解2:https://blog.csdn.net/weixin_40227656/article/details/116018040
协变量偏移和BatchNormalization:https://zhuanlan.zhihu.com/p/522525435
YOLOv2相对于v1有十个改进点,主要可以分为Better和Faster两个方面,其中Better有7个改进点,Faster有3个改进点(主要体现在模型的选择和训练测试步骤的调整)。
Better
1. Batch Normalization
BN主要用于解决协变量偏移的问题。首先需要了解协变量偏移的概念:
协变量偏移:
考虑下面的问题:现在考虑全连接网络的一层,其初始的权重矩阵是,此时将数据分成若干个batch输入该层,假设第一个batch的数据是,其前向计算过程是:和做矩阵相乘后的结果是,输出后经过激活函数得到输出。其反向传播过程可以笼统得看成:调整权重矩阵是为。下一轮的前向计算过程是:接收第二个batch的数据是,和做矩阵相乘后的结果是,输出后经过激活函数得到输出.
上面的这个过程中存在着协变量偏移的过程,具体的体现为:对于同一组数据的不同的batch,每一组batch中的数据是独立同分布的,即和是独立同分布的。然而由于反向传播,权重矩阵相对于而言做了调整,因此在进行后续的矩阵惩罚和经过激活函数的过程中,得到的和是不独立同分布的。输入数据独立同分布,输出数据不独立同分布,会导致网络的若干次训练收敛速度慢,稳定性差,且的输出容易落在激活函数(sigmoid函数和tanh函数)的饱和区,导致梯度爆炸或消失。(如下图所示)

BN算法:
可以看做是归一化加一个线性层。分别表示为:
为什么要引入线性层(和)?
如果没有这两个变量,这将是一个标准化过程。这两个变量的存在使得BN和标准化过程的区别在于:
- 当标准化效果不好时,可以调整标准化的程度甚至取消标准化;
- 如果只做标准化,输出容易落在sigmoid和tanh的线性区,降低模型的非线性分类能力;
- 引入噪声,让模型更加鲁棒(不太懂呢)
在进行预测时,将之前训练时batch的mean和var加权求和。
BN层的位置:在sigmoid和relu中需要放在激活函数的前面;当激活函数为ReLU时,可以放在激活函数的后面。
BN和LN有什么区别?
- BN是对同一特征维度的batch做归一化;
- LN是对同意样本不同维度的特征做归一化:例如在数据为文本时,数据是变长序列。如下图所示。

2. High Resolution Classifier
这一步改进用来平衡预训练和检测模型的图像分辨率不同。由于一般的分类模型训练都是在ImageNet数据集上进行的,输入尺寸为,而切换成检验模型时图像的输入为。因此YOLOv1在切换检测模型后还需要适应图像分辨率的改变。
YOLOv2做出的改进是:在进行预训练时,前160个epoch用分辨率为的输入,最后10个epoch用的输入,作为过渡。
3. Convolutional With Anchor Boxes
YOLOv1中利用全连接层的数据完成边框预测,而YOLOv2放弃了fc和pooling,而是使用anchor来参与bbox的回归。
- 在YOLOv1中,同一个Grid cell中预测两个bbox,这两个bbox的分类是相同的;
- 在YOLOv2中,每一个anchor box都要单独进行分类。
上述表述可以直观化地用下图表示:
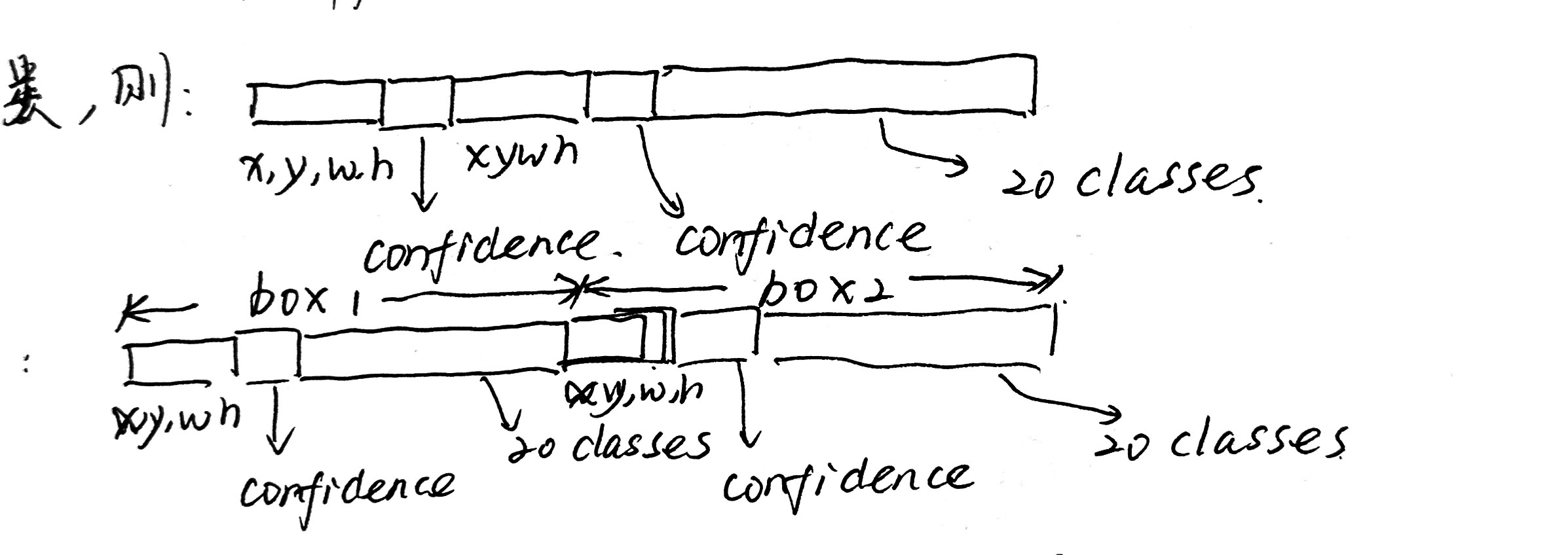
4. Dimension Clusters 维度聚类
我们知道,在Faster RCNN中,对每一个点生成9个anchor。然而,YOLOv2改变了生成anchor的数量。那如何确定anchor的数量?先用K-means对ground truth的bbox进行聚类,并根据最终得到的k类决定每一个点生成k个anchor。
这个k-means与常规聚类任务的不同在于,将常规k-means中使用的欧式距离变味了ground truth bbox之间的IoU,用来规避bbox的尺寸不同对欧式距离所造成的影响。
5. Direct location prediction 直接位置预测
引入anchor可能遇到的问题:在训练开始时,回归过程震荡明显,收敛不稳定。原因在于:faster rcnn中的bbox回归,没有对平移量tx,ty做约束,因此,每一个预测的边界框可以落在图上的不同位置,这就导致了回归过程的收敛缓慢。
YOLOv2中的做法是通过sigmoid将偏移量限制在的范围中,即限制anchor的中心点落在cell中。
6. Fine-Grained Features 细粒度特征
在目标识别任务中,feature map的尺寸越小,对越大的目标的分类效果就越好;反之,对较小目标的识别效果会变差。因此,YOLOv2中提出了一种类似于ResNet的结构:原先的层下采样得到的层,现在用一个残差连接直接将下采样前的feature map和下采样后的融合,相当于将的输出变成了,利用尺寸较大的feature map保留了模型对较小目标的识别效果。
7. Multi-Scale Training
注意区别:前面提到的High Resolution Classifier是在预训练的过程中进行的调整,而Multi-Scale Training是在fine tune过程中进行的。
这一步旨在让模型对于尺寸更有鲁棒性。模型fine tune时,训练每经过10个epoch,更换一次图像的输入尺寸。输入尺寸通过以下方法来确定:YOLOv2的模型输入为, 而输出为,说明下采样率为32,因此,以32的倍数作为每次调整输入的size:[320, 352, ... 608].
Faster
8. Darknet-19 架构
使用Darknet-19替换了YOLOv1中的GoogleNet。
9. train技巧
(主要指在pretrain中)
- 常规的分类网络训练中:
input_size=224*224, lr=0.1, weight decay=0.0005, momentum=0.9; - data augmentation
- 多分辨率训练,即High Resolution Classifier的最后10个epoch中,设置
input_size=448*448, lr=0.001
10. test技巧
不太理解,但应该不是重点吧?
- 最后一个卷积层换成3个
3*3的卷积层,最终每个grid cell中有125个filter(YOLOv1中有30个) - YOLOv1的每一个gridcell中的2个bbox分类是一样的,但是v2中每个bbox都对应了一个分类
本文作者:PaB式乌龙茶
本文链接:https://www.cnblogs.com/pab-oolongtea/p/17999682
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步