YOLO
参考目录:
fasterRCNN是two-stage的目标检测算法,即分别完成分类和回归任务。而YOLO提出将物体检测作为一个回归问题进行求解,即输入图像经过一次网络,就得到物体的位置、类别和置信度,开启了one-stage目标检测。
YOLO的网络结构:
1. YOLO的网络结构
(这段将在我看完YOLO的代码后来补充)

2. 创新点和核心思想
YOLO的创新点和核心思想主要可以总结为以下几个:
2.1 网格
将输入图像设置若干个等间隔的线,假设纵向S条,横向S条,这些线会将图像分割为S*S个cell。每一个cell对应着一个类别,标签的类别将有ground truth决定。在训练和推理过程中,判断一个bbox的方法就是看这个bbox的中心点落在哪一个cell中。因此,一个cell中对应的所有bbox的类别都是同一类。
2.2 confidence
引入了置信度confidence的概念。confidence具有两重信息:(1)目标中心是否落在cell中;(2)预测值和ground truth的IoU。因此,可以表示为:
同时,bounding box的表示从四维增加到了五维,即由原先的变为,添加了置信度(且这里的都是经过归一化的)。
2.3 class-specific confidence score
在进行推理时,会将每个网格预测的条件概率(即,对于这个网格,类别为的概率)和confidence相乘,即:
最后这个成绩为每个bbox的class-specific confidence score,既包含了bbox属于的类别的概率,又包含了bbox的位置的准确度。
3. Training
YOLO的训练过程中,在设计Loss函数时考虑了以下几个方面:
3.1 bbox的坐标预测误差
作者认为,对于不同大小的bbox,相比于大bbox的大小预测有了一定的偏差,小的bbox的大小有了相同的偏差是更致命的。因此,在loss中同等对待不同大小bbox的预测偏差是不合理的。因此作者选择将w和h用进行压缩,这样随着w和h的增大,惩罚程度的上升会逐渐变慢。
3.2 bbox的confidence预测误差
图像中的大部分cell可能包含背景(即不包含目标),因此大多数box的confidence为0.作者认为confidence为1和0的bbox不应该同等对待,confidence=0的惩罚被减轻了,乘以了权重.
此外坐标预测误差和conference预测误差之间也有权重.
3.3 分类预测误差
前面提到过,每一个cell对应的bbox都是同一类,因此在计算时只需要逐cell计算,而不需要逐bbox计算。
最终的预测误差如下:
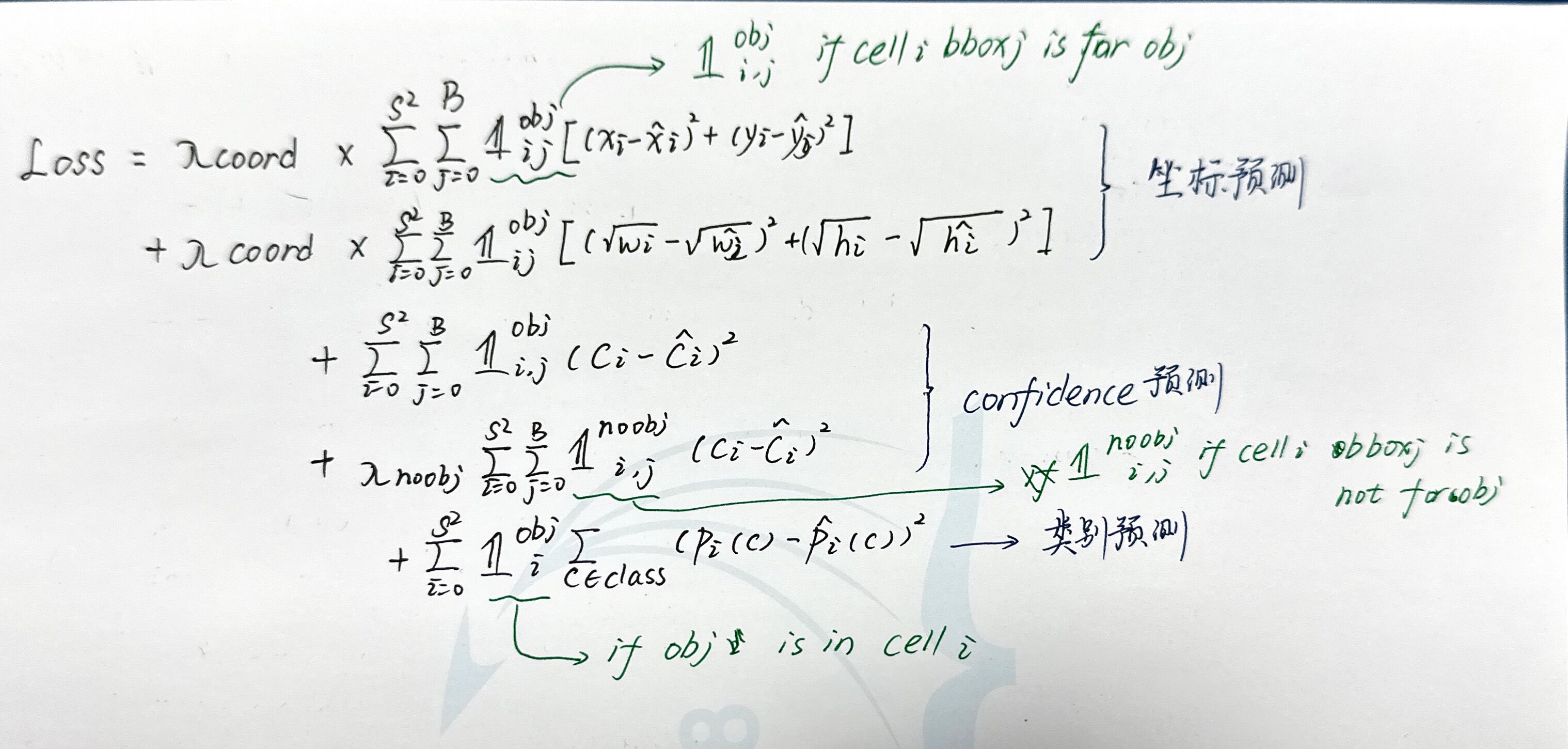
本文作者:PaB式乌龙茶
本文链接:https://www.cnblogs.com/pab-oolongtea/p/17999670
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步