MaskRCNN
maskRCNN:https://blog.csdn.net/weixin_43702653/article/details/124377487
https://www.cnblogs.com/wangyong/p/10614898.html
https://zhuanlan.zhihu.com/p/407831250
feature map:https://blog.csdn.net/MengYa_Dream/article/details/123705503
FPN网络:https://zhuanlan.zhihu.com/p/562953949
感受野:https://zhuanlan.zhihu.com/p/394917827
ROI Align:https://zhuanlan.zhihu.com/p/73113289
https://blog.csdn.net/Tian__Gao/article/details/124474448
双线性插值法:https://zhuanlan.zhihu.com/p/191260037
FCN:https://zhuanlan.zhihu.com/p/384377866
转置卷积:https://blog.csdn.net/weixin_39910711/article/details/124342599?utm_medium=distribute.pc_relevant.none-task-blog-2defaultbaidujs_baidulandingword~default-0-124342599-blog-121181904.235v38pc_relevant_anti_t3&spm=1001.2101.3001.4242.1&utm_relevant_index=3
maskRCNN在fasterRCNN的基础上,与bounding box检测并行地增加了一个预测分割mask的分支,相当于将目标检测和语义分割结合起来,从而达到实力分割的效果。
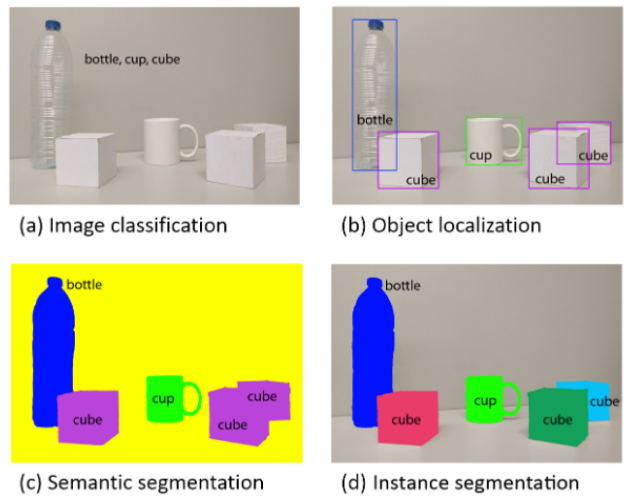
实例分割
实力分割和语义分割的区别:语义分割会分割出不同类别的物体,而实力分割可以分割出同一类中的不同实例的物体。
基本结构
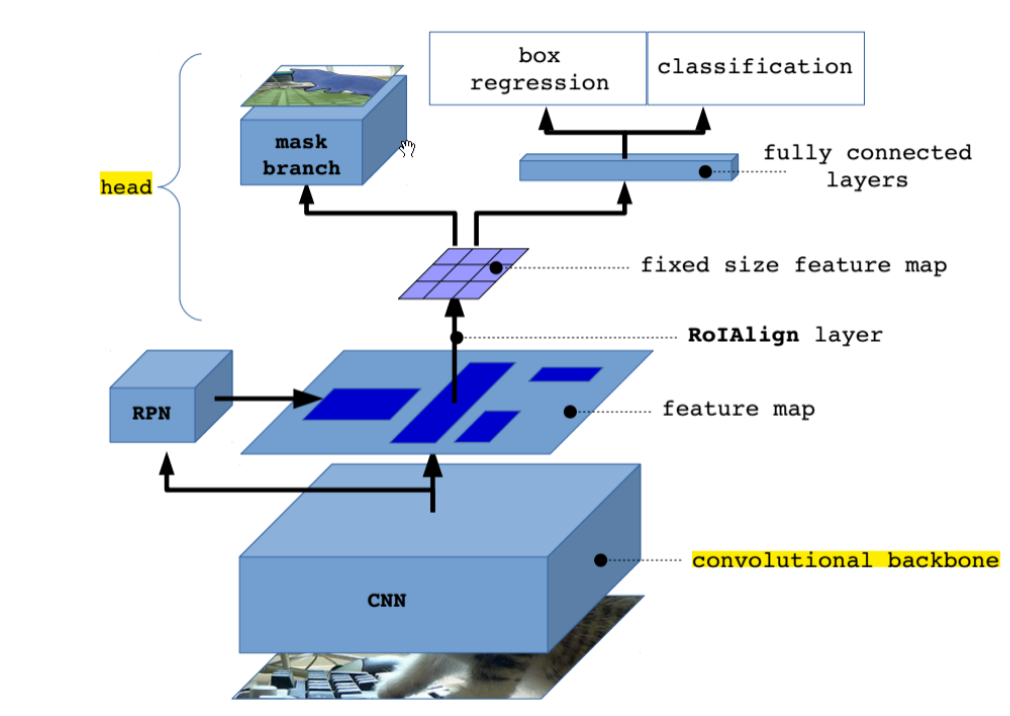
maskRCNN的基本结构图
maskRCNN的基本结构如上图所示。其流程步骤如下:
- 输入一张图片,经过预训练好的CNN(ResNet+FPN)得到feature map;
- 对feature map的每一个点预设一些ROI,从而获得多个候选的ROI;
- 对这些ROI送入RPN网络进行二值分类(前景或背景)和bbox回归,过滤掉超出图像区域的ROI;
- 进行ROI Align操作,将原图和feature map的像素对应起来,然后将feature map和固定的feature对应起来;
- 对ROI进行N类别分类、bbox回归和mask生成(在每个ROI中进行FCN操作)。
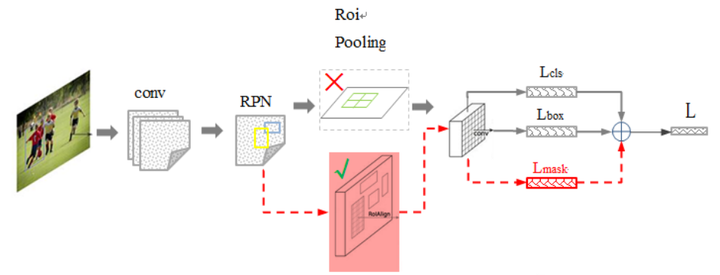
maskRCNN相对于fasterRCNN的结构变化
如上图所示,maskRCNN相对于fasterRCNN的结构变化有有如下几个:
- 使用的ResNet+FPN代替fasterRCNN中的vgg网络;
- 将ROI pooling替换为ROI alig;
- 添加并列的FCN层,完成语义分割任务。
1. FPN
浅层网络中的特征语义信息比较少,但是目标位置准确;深层的特征语义信息比较丰富,但是目标位置比较粗略(原因:浅层网络的感受野较小,每一个像素点代表的区域很小,能够利用更多细粒度特征信息;随着下采样或卷积次数的增加,感受野逐渐增加,每一个像素点代表一个区域的信息,相对不够细粒度。感受野:特征图上的一点,相对于原图的大小)。
FPN的目标:先通过下采样得到语义特征,然后在保留语义特征的基础上进行上采样,最终得到既有语义特征、又有细粒度特征的网络。因此FPN的网络结构可以分为两个部分:自底向上和自顶向下。
FPN网络结构
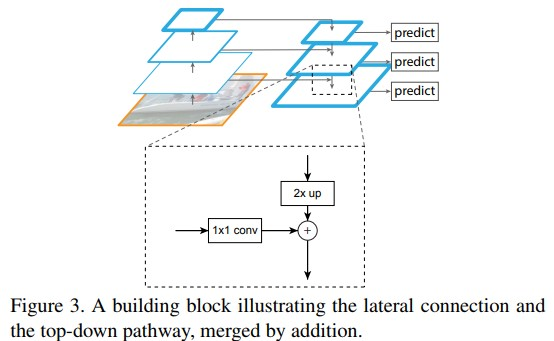
FPN网络结构以及自顶向下过程中的上采样机制
FPN的网络机构如图所示:
- 在自底向上的过程中,通过卷积和池化提取对特征图进行降维,依次得到, , , , 五个特征图。其中,因为,和的特征图的大小是一样的,所以FPN的建立基于到这四个特征层。
- 在自顶向下的过程中,需要进行上采样,同时将上采样结果和下采样过程中的特征图进行merge。同时还需要进行卷积操作,消除上采样中的混叠效应。首先通过的卷积生成,再进行对进行步长为2的下采样,将下采样结构与经过的卷积的结果merge的到,依此类推得到,
- 对进行步长为2的max pooling得到.
Anchor生成规则
规则:
- 遍历,到这五个特征层,对特征层上的每一个像素都生成anchor;
- anchor生成规则:以层为例,其相对于原图的步长为4,因此对于上的每一个尺寸预设为anchor scale锚框,都能够在原图上对应一个的锚框。同时,我们可以为锚框设置长宽比变换,如
RATIO=[0.5,1,2],就可以基于每个锚框得到三种不同尺寸的锚框。在fasterRCNN中可以将anchor scale设置为多个值,而在maskRCNN中每一个特征层只对应着一个anchor scale。
例如,如果我们将anchor scale设置为,则在上,可以生成个锚框。
2. ROI Align
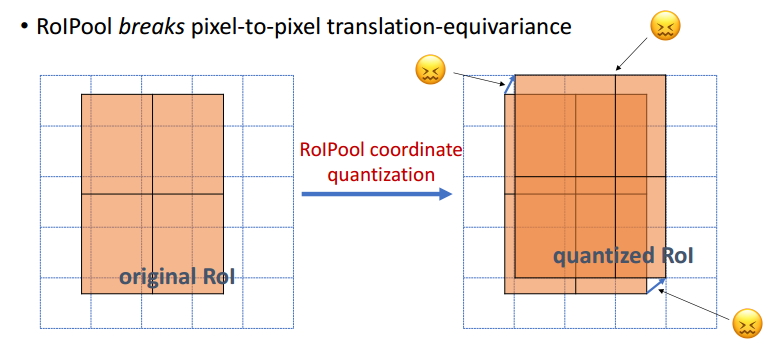
ROI pooling需要进行两次量化操作:图像坐标->feature map; feature map->ROI feature坐标。这两个操作导致ROI pooling并不是按照像素一一对齐的,因此对掩码的精度有较大的影响。因此使用ROI Align来代替ROI pooling。
ROI pooling的基本步骤
在得到ROI后,如果ROI的边界没有位于feature map的网格,需要进行对齐操作,如下图所示。这一步中会引入位置的偏差。
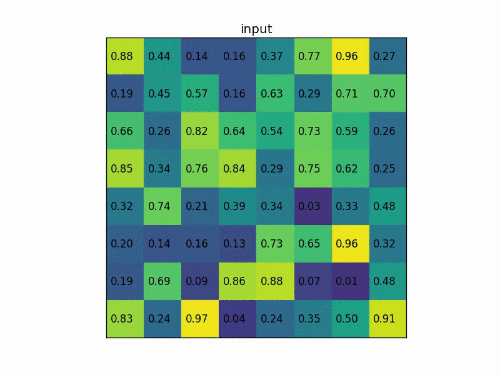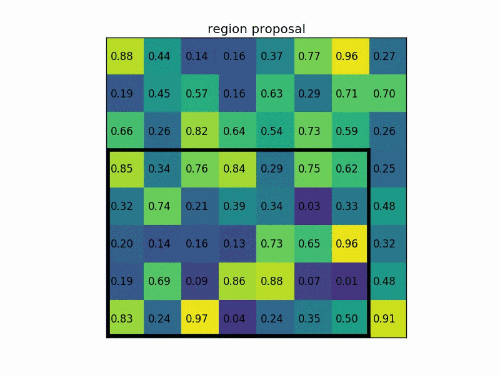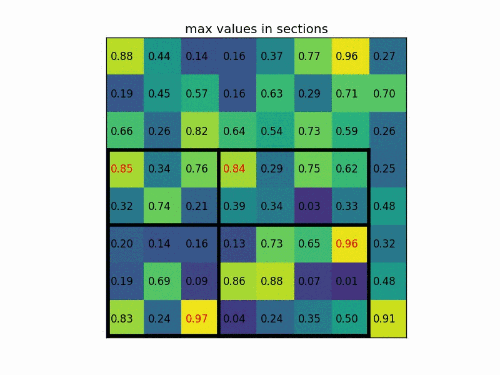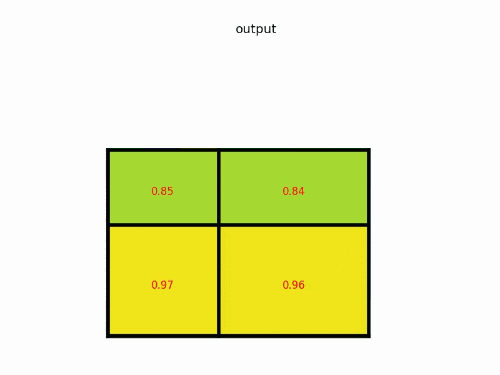
在进行完上一步后,需要划分子区域。此时如果ROI的大小为,则对于长度为奇数的边进行先取平均值再向上向下取整的操作,再对子区域做max pooling,如下图所示,这一步也会引入偏差。
ROI Align的步骤
首先,对浮点数边界不做对齐;其次划分子区域时采用均匀划分。
对于划分的每个子区域,取得四个采样点(选取方式为将子区域划分成四个子子区域,并取每个子子区域的中心点),再利用双线性插值法计算四个采样点的像素值大小,最后通过max pooling或average pooling对每一个子区域执行聚合操作,得到最终的特征图。
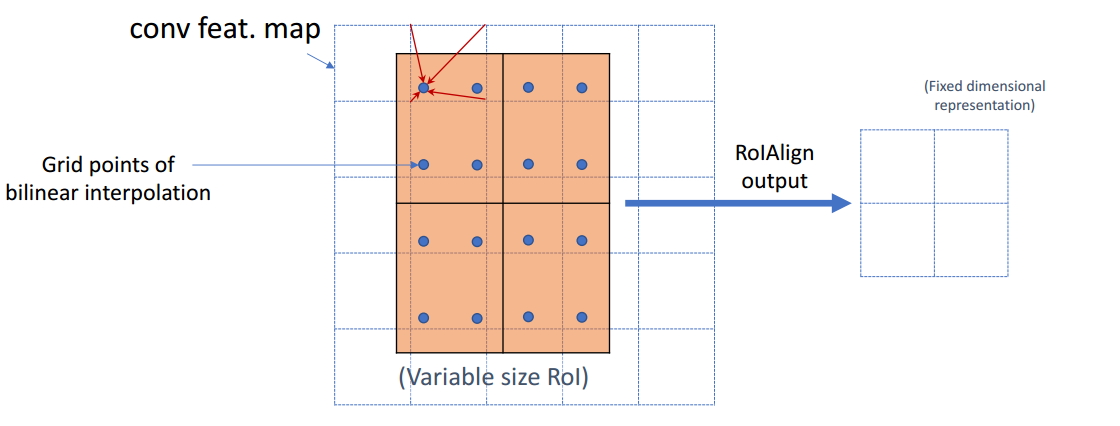
双线性插值法
首先介绍一下插值法。插值法是在图像缩放的过程中,将旧图片中的像素放到新图片中时所使用的算法。对于原图像中的像素的坐标,假设原图像的宽高为,,目标图像的宽高为,,则对应的目标图像中的坐标为:
如果得到的和不是整值的话,就需要使用插值的方法。速度最快但效果最差的是最近邻插值法,直接用计算结果找到最邻近的点。
而双线性插值法则不是找到附近的一个点,而是找到四个点。双线性插值可以看作进行三次单线性插值,两次x一次y或者两次y一次x。单线性插值就是利用直线上一点到直线两端的关系,得到如下的关系:
3. FCN层
传统的CNN会将图像下采样后,最后输出一个n维的向量来表示输入图像属于每一类的概率。而FCN则是对图像进行像素级的分类,深度模型后使用转置卷积进行上采样,最后输出的heat map上的每一个像素都产生一个预测,同时保留了原始输入图像中的空间信息。
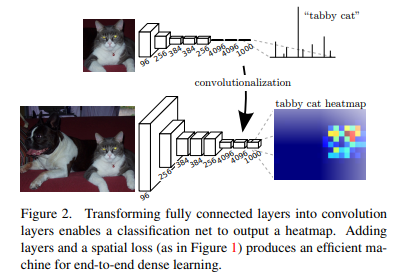
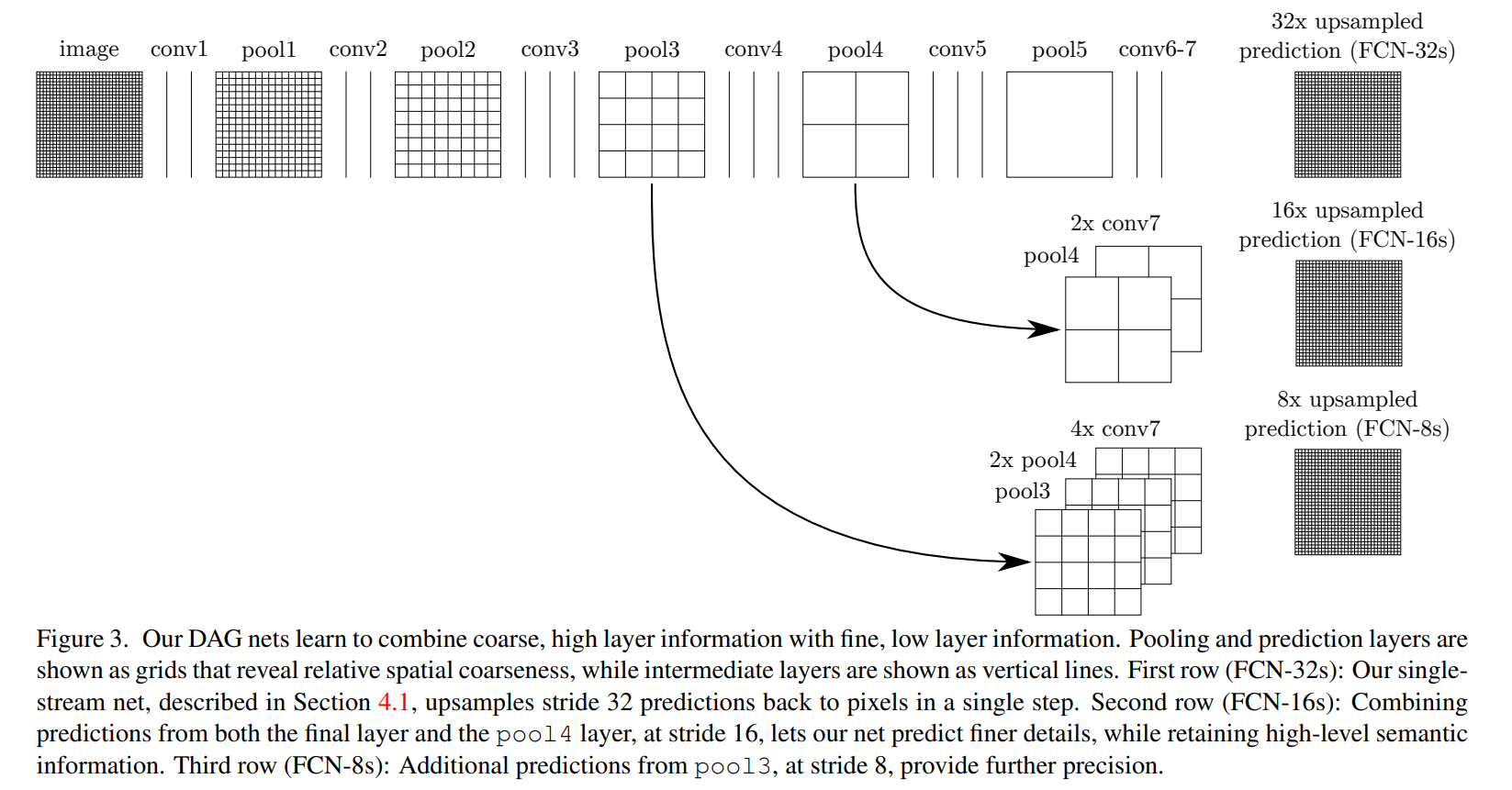
FCN网络的流程如下(如下图所示):
- 输入的图像经过convi+pooli(i=1~5)进行下采样,得到1/32尺寸特征图;
- 经过两个卷积层后图像尺寸不变;
- 使用转置卷积对1/32特征图进行上采样,得到图像预测结果FCN-32s;
- 将1/32特征图进行2倍上采样,再和pool4的1/16特征图进行融合,对融合原理进行上采样得到预测图FCN-16s;
- 最后将pool3的1/8特征图与1/16图和1/32图做上述同样的操作,最后上采样得到图像预测FCN-8s。
本文作者:PaB式乌龙茶
本文链接:https://www.cnblogs.com/pab-oolongtea/p/17999558
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步