
Go标准库源码分析: atomic.AddInt64
atomic.AddInt64
介绍
原理
源码
看不到源码解释个勾八原理
源码里只有函数doc, 但是没有函数实现, 但是有一段注释
// AddInt64 atomically adds delta to *addr and returns the new value.
// Consider using the more ergonomic and less error-prone [Int64.Add] instead
// (particularly if you target 32-bit platforms; see the bugs section).
介绍了他的功能是原子性的对地址所指的数字 + delta, 需要注意一个问题, 在32位的平台上不应该使用, 会存在bug
在全局搜索过后, 一段特别的注释引起了我的注意
//go:linkname abigen_sync_atomic_AddInt64 sync/atomic.AddInt64
这条指令告诉编译器,虽然sync/atomic.AddInt64函数定义在sync/atomic包中,但是可以通过abigen_sync_atomic_AddInt64这个别名在其他包中被直接调用,就好像它定义在那个包内一样。
好了, 我们已经找到了实际对应的源码位置, 但是奇怪的事情出现了, 此处依然没有实现
//go:linkname abigen_sync_atomic_AddInt64 sync/atomic.AddInt64
func abigen_sync_atomic_AddInt64(addr *int64, delta int64) (new int64)
在同级目录下, 存在这么一个文件
这就是他的实现源码了, 为了不同的平台的适配, 底层的实现使用了汇编, 在最后编译时在链接起来.
分析
函数签名
func abigen_sync_atomic_AddInt64(addr *int64, delta int64) (new int64)
栈帧布局(不太准确, 先忽略)
+----------------+
| addr |
+----------------+
| delta |
+----------------+
| 返回值 (new) |
+----------------+
变量对应
-
addr: +0(FP) -
delta: +8(FP) -
new: +16(FP)
代码解释
TEXT sync∕atomic·AddInt64(SB), NOSPLIT|NOFRAME, $0-24
GO_ARGS
MOVQ $__tsan_go_atomic64_fetch_add(SB), AX
CALL racecallatomic<>(SB)
MOVQ add+8(FP), AX // convert fetch_add to add_fetch
ADDQ AX, ret+16(FP)
RET
-
载入函数
__tsan_go_atomic64_fetch_add到寄存器AX中 -
执行函数
__tsan_go_atomic64_fetch_add, 这一步执行的是fetch_add在并发编程中,
fetch_add和add_fetch是两种常见的原子操作,用于实现对共享变量的原子加操作。它们的区别在于操作的顺序不同。-
fetch_add:fetch_add操作首先读取共享变量的当前值,然后将指定的值加到该变量上,并返回变量之前的值。换句话说,fetch_add的顺序是先读取再相加。 -
add_fetch:与fetch_add相反,add_fetch操作首先将指定的值加到共享变量上,然后返回变量的新值。换句话说,add_fetch的顺序是先相加再返回。
举个简单例子,假设共享变量的初始值为0,执行以下操作:
-
fetch_add(3):首先读取变量的当前值为0,然后将3加到变量上,最后返回之前的值0。 -
add_fetch(3):首先将3加到变量上,变量的新值为3,然后返回新值3。
-
-
载入delta, 存放进AX寄存器, 需要注意的是此时的
ret+16(FP)存放的是__tsan_go_atomic64_fetch_add的结果, 是未执行加操作前的数值, 在外面在执行一遍加法, 保证一致, 函数结束.
汇编分析

我们需要注意看黄色部分的上半边内容
- 将 0x3f (63) 载入CX寄存器
- ((20240329223156-gclhnmm 'XADD')) 进行原子性的加法, 并将使用加法之前的
(AX)写入CX - 将CX结果移入
0x8(SP)
但是到这里会有问题, 因为此时返回的是one增加之前的值, 而我是需要的是加完之后的值
我们接着看后半部分
-
MOVQ 0x8(SP), AX 将返回的结果写入AX寄存器 -
ADDQ $0x3f, AX 执行加法, 此时得到的才是真正的返回值
也就是说, 这里执行了一个懒加载, 即在实际使用时, 才去计算了真实的返回值.
未优化汇编
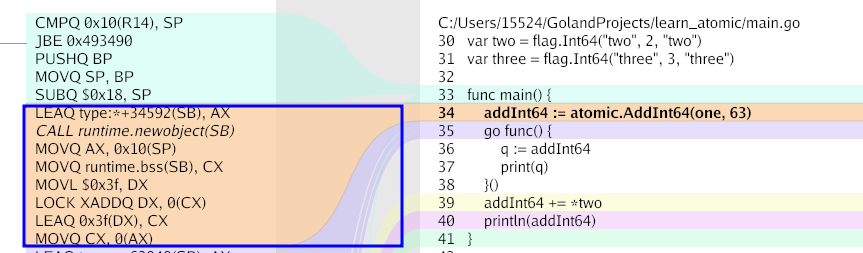
我们从LEAQ开始看, 能够发现, 0x3f又出现了一次
LEA
https://blog.csdn.net/Chauncyxu/article/details/121890457
加载有效地址(load effective address)指令 leaq 实际上是 movq 指令的变形。
它的指令形式是从内存读数据到寄存器,但实际上它根本就没有引用内存。
第一个操作数 S看上去是一个内存引用,但该指令并不是从指定的位置读入数据,而是将有效地址写入到目的操作数 D。这条指令可以为后面的内存引用产生指针。
目的操作数 D 必须是一个寄存器。
另外,它还可以简洁地描述普通的算术操作。例如,如果寄存器 %rdx 的值为 x,那么指令
leaq 7(%rdx, %rdx,4), %rax 将设置寄存器 %rax 的值为 5x+7。
他所做的事情就是将DX的值 + 63, 然后将结果写回CX中
最后将CX的结果写回(AX), (AX)就是实际的返回值即AddInt64的正确返回值
注意
为什么要有Lock?
参考 https://stackoverflow.com/questions/30130752/assembly-does-xadd-instruction-need-lock
如果没有Lock, XADDQ依然可以保证原子性, 但是只能保证在单个core上的原子性, 无法提供全局保证.
PS
__tsan_go_atomic64_fetch_add 函数是 Go 语言运行时在使用数据竞态检测(ThreadSanitizer,简称 TSan)时的内部函数。它的实现细节通常是隐藏的,因为这个函数是由运行时的系统库提供的,不是由 Go 语言本身直接实现的。TSan 是一个用于检测多线程程序中数据竞态的工具,它会在运行时拦截所有的内存操作以检测潜在的数据竞态问题。
在大多数平台, 都是通过LOCK+ XADD来实现的.
atomic.AddInt64 的使用还是比较简单的, 只需要传入一个指针, 同时指定delta就可以
atomic.AddInt64(&i, 64)

